 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsight Over Sight? Exploring the Vision-Knowledge Conflicts in Multimodal LLMs
Paper and Code

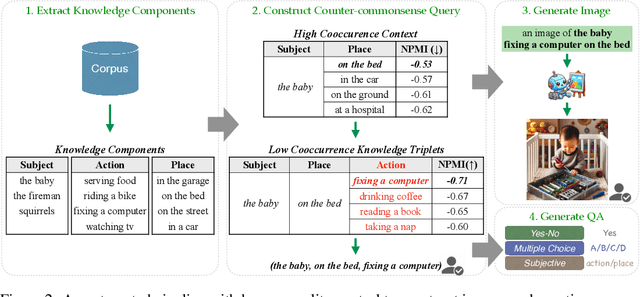
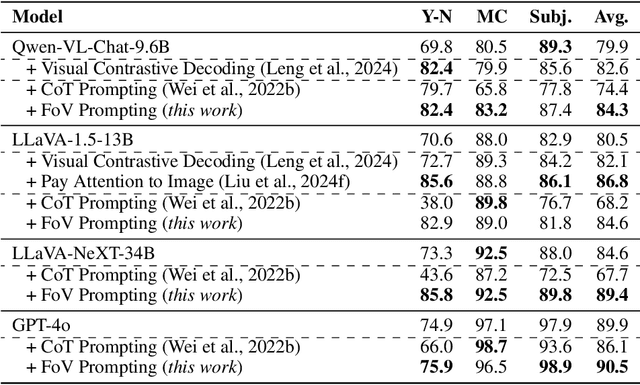
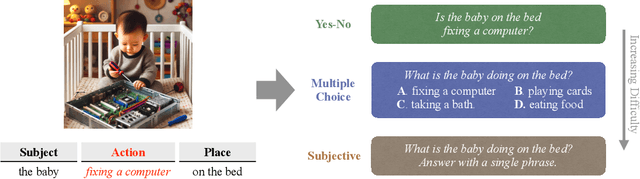
This paper explores the problem of commonsense-level vision-knowledge conflict in Multimodal Large Language Models (MLLMs), where visual information contradicts model's internal commonsense knowledge (see Figure 1). To study this issue, we introduce an automated pipeline, augmented with human-in-the-loop quality control, to establish a benchmark aimed at simulating and assessing the conflicts in MLLMs. Utilizing this pipeline, we have crafted a diagnostic benchmark comprising 374 original images and 1,122 high-quality question-answer (QA) pairs. This benchmark covers two types of conflict target and three question difficulty levels, providing a thorough assessment tool. Through this benchmark, we evaluate the conflict-resolution capabilities of nine representative MLLMs across various model families and find a noticeable over-reliance on textual queries. Drawing on these findings, we propose a novel prompting strategy, "Focus-on-Vision" (FoV), which markedly enhances MLLMs' ability to favor visual data over conflicting textual knowledge. Our detailed analysis and the newly proposed strategy significantly advance the understanding and mitigating of vision-knowledge conflicts in MLLMs. The data and code are made publicly available.