 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pensieve Paradigm: Stateful Language Models Mastering Their Own Context
Feb 12, 2026In the world of Harry Potter, when Dumbledore's mind is overburdened, he extracts memories into a Pensieve to be revisited later. In the world of AI, while we possess the Pensieve-mature databases and retrieval systems, our models inexplicably lack the "wand" to operate it. They remain like a Dumbledore without agency, passively accepting a manually engineered context as their entire memory. This work finally places the wand in the model's hand. We introduce StateLM, a new class of foundation models endowed with an internal reasoning loop to manage their own state. We equip our model with a suite of memory tools, such as context pruning, document indexing, and note-taking, and train it to actively manage these tools. By learning to dynamically engineering its own context, our model breaks free from the architectural prison of a fixed window. Experiments across various model sizes demonstrate StateLM's effectiveness across diverse scenarios. On long-document QA tasks, StateLMs consistently outperform standard LLMs across all model scales; on the chat memory task, they achieve absolute accuracy improvements of 10% to 20% over standard LLMs. On the deep research task BrowseComp-Plus, the performance gap becomes even more pronounced: StateLM achieves up to 52% accuracy, whereas standard LLM counterparts struggle around 5%. Ultimately, our approach shifts LLMs from passive predictors to state-aware agents where reasoning becomes a stateful and manageable process.
MicLog: Towards Accurate and Efficient LLM-based Log Parsing via Progressive Meta In-Context Learning
Jan 11, 2026Log parsing converts semi-structured logs into structured templates, forming a critical foundation for downstream analysis. Traditional syntax and semantic-based parsers often struggle with semantic variations in evolving logs and data scarcity stemming from their limited domain coverage. Recent large language model (LLM)-based parsers leverage in-context learning (ICL) to extract semantics from examples, demonstrating superior accuracy. However, LLM-based parsers face two main challenges: 1) underutilization of ICL capabilities, particularly in dynamic example selection and cross-domain generalization, leading to inconsistent performance; 2) time-consuming and costly LLM querying. To address these challenges, we present MicLog, the first progressive meta in-context learning (ProgMeta-ICL) log parsing framework that combines meta-learning with ICL on small open-source LLMs (i.e., Qwen-2.5-3B). Specifically, MicLog: i) enhances LLMs' ICL capability through a zero-shot to k-shot ProgMeta-ICL paradigm, employing weighted DBSCAN candidate sampling and enhanced BM25 demonstration selection; ii) accelerates parsing via a multi-level pre-query cache that dynamically matches and refines recently parsed templates. Evaluated on Loghub-2.0, MicLog achieves 10.3% higher parsing accuracy than the state-of-the-art parser while reducing parsing time by 42.4%.
Scalable Supervising Software Agents with Patch Reasoner
Oct 26, 2025



While large language model agents have advanced software engineering tasks, the unscalable nature of existing test-based supervision is limiting the potential improvement of data scaling. The reason is twofold: (1) building and running test sandbox is rather heavy and fragile, and (2) data with high-coverage tests is naturally rare and threatened by test hacking via edge cases. In this paper, we propose R4P, a patch verifier model to provide scalable rewards for training and testing SWE agents via reasoning. We consider that patch verification is fundamentally a reasoning task, mirroring how human repository maintainers review patches without writing and running new reproduction tests. To obtain sufficient reference and reduce the risk of reward hacking, R4P uses a group-wise objective for RL training, enabling it to verify multiple patches against each other's modification and gain a dense reward for stable training. R4P achieves 72.2% Acc. for verifying patches from SWE-bench-verified, surpassing OpenAI o3. To demonstrate R4P's practicality, we design and train a lite scaffold, Mini-SE, with pure reinforcement learning where all rewards are derived from R4P. As a result, Mini-SE achieves 26.2% Pass@1 on SWE-bench-verified, showing a 10.0% improvement over the original Qwen3-32B. This can be further improved to 32.8% with R4P for test-time scaling. Furthermore, R4P verifies patches within a second, 50x faster than testing on average. The stable scaling curves of rewards and accuracy along with high efficiency reflect R4P's practicality.
CLEANet: Robust and Efficient Anomaly Detection in Contaminated Multivariate Time Series
Oct 26, 2025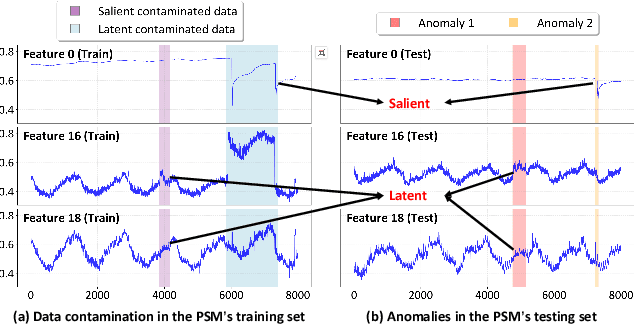
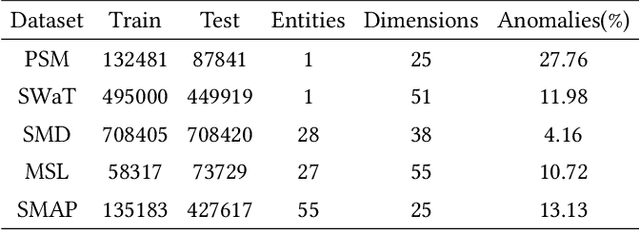
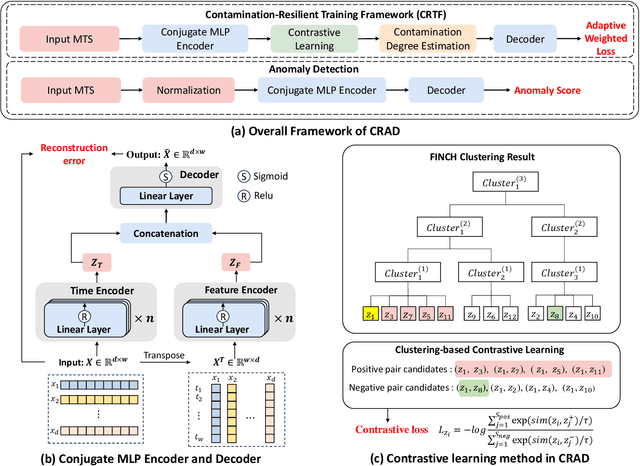
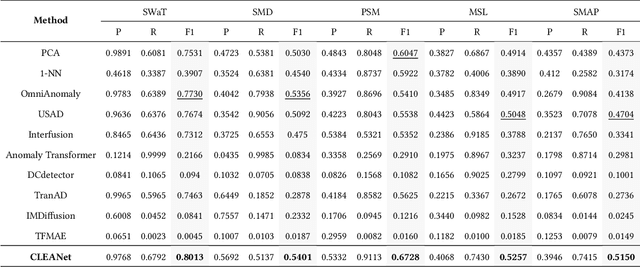
Multivariate time series (MTS) anomaly detection is essential for maintaining the reliability of industrial systems, yet real-world deployment is hindered by two critical challenges: training data contamination (noises and hidden anomalies) and inefficient model inference. Existing unsupervised methods assume clean training data, but contamination distorts learned patterns and degrades detection accuracy. Meanwhile, complex deep models often overfit to contamination and suffer from high latency, limiting practical use. To address these challenges, we propose CLEANet, a robust and efficient anomaly detection framework in contaminated multivariate time series. CLEANet introduces a Contamination-Resilient Training Framework (CRTF) that mitigates the impact of corrupted samples through an adaptive reconstruction weighting strategy combined with clustering-guided contrastive learning, thereby enhancing robustness. To further avoid overfitting on contaminated data and improve computational efficiency, we design a lightweight conjugate MLP that disentangles temporal and cross-feature dependencies. Across five public datasets, CLEANet achieves up to 73.04% higher F1 and 81.28% lower runtime compared with ten state-of-the-art baselines. Furthermore, integrating CRTF into three advanced models yields an average 5.35% F1 gain, confirming its strong generalizability.
Curing Miracle Steps in LLM Mathematical Reasoning with Rubric Rewards
Oct 09, 2025Large language models for mathematical reasoning are typically trained with outcome-based rewards, which credit only the final answer. In our experiments, we observe that this paradigm is highly susceptible to reward hacking, leading to a substantial overestimation of a model's reasoning ability. This is evidenced by a high incidence of false positives - solutions that reach the correct final answer through an unsound reasoning process. Through a systematic analysis with human verification, we establish a taxonomy of these failure modes, identifying patterns like Miracle Steps - abrupt jumps to a correct output without a valid preceding derivation. Probing experiments suggest a strong association between these Miracle Steps and memorization, where the model appears to recall the answer directly rather than deriving it. To mitigate this systemic issue, we introduce the Rubric Reward Model (RRM), a process-oriented reward function that evaluates the entire reasoning trajectory against problem-specific rubrics. The generative RRM provides fine-grained, calibrated rewards (0-1) that explicitly penalize logical flaws and encourage rigorous deduction. When integrated into a reinforcement learning pipeline, RRM-based training consistently outperforms outcome-only supervision across four math benchmarks. Notably, it boosts Verified Pass@1024 on AIME2024 from 26.7% to 62.6% and reduces the incidence of Miracle Steps by 71%. Our work demonstrates that rewarding the solution process is crucial for building models that are not only more accurate but also more reliable.
UTBoost: Rigorous Evaluation of Coding Agents on SWE-Bench
Jun 10, 2025The advent of Large Language Models (LLMs) has spurred the development of coding agents for real-world code generation. As a widely used benchmark for evaluating the code generation capabilities of these agents, SWE-Bench uses real-world problems based on GitHub issues and their corresponding pull requests. However, the manually written test cases included in these pull requests are often insufficient, allowing generated patches to pass the tests without resolving the underlying issue. To address this challenge, we introduce UTGenerator, an LLM-driven test case generator that automatically analyzes codebases and dependencies to generate test cases for real-world Python projects. Building on UTGenerator, we propose UTBoost, a comprehensive framework for test case augmentation. In our evaluation, we identified 36 task instances with insufficient test cases and uncovered 345 erroneous patches incorrectly labeled as passed in the original SWE Bench. These corrections, impacting 40.9% of SWE-Bench Lite and 24.4% of SWE-Bench Verified leaderboard entries, yield 18 and 11 ranking changes, respectively.
Towards Evaluating Proactive Risk Awareness of Multimodal Language Models
May 23, 2025Human safety awareness gaps often prevent the timely recognition of everyday risks. In solving this problem, a proactive safety artificial intelligence (AI) system would work better than a reactive one. Instead of just reacting to users' questions, it would actively watch people's behavior and their environment to detect potential dangers in advance. Our Proactive Safety Bench (PaSBench) evaluates this capability through 416 multimodal scenarios (128 image sequences, 288 text logs) spanning 5 safety-critical domains. Evaluation of 36 advanced models reveals fundamental limitations: Top performers like Gemini-2.5-pro achieve 71% image and 64% text accuracy, but miss 45-55% risks in repeated trials. Through failure analysis, we identify unstable proactive reasoning rather than knowledge deficits as the primary limitation. This work establishes (1) a proactive safety benchmark, (2) systematic evidence of model limitations, and (3) critical directions for developing reliable protective AI. We believe our dataset and findings can promote the development of safer AI assistants that actively prevent harm rather than merely respond to requests. Our dataset can be found at https://huggingface.co/datasets/Youliang/PaSBench.
Trust, But Verify: A Self-Verification Approach to Reinforcement Learning with Verifiable Rewards
May 19, 2025Large Language Models (LLMs) show great promise in complex reasoning, with Reinforcement Learning with Verifiable Rewards (RLVR) being a key enhancement strategy. However, a prevalent issue is ``superficial self-reflection'', where models fail to robustly verify their own outputs. We introduce RISE (Reinforcing Reasoning with Self-Verification), a novel online RL framework designed to tackle this. RISE explicitly and simultaneously trains an LLM to improve both its problem-solving and self-verification abilities within a single, integrated RL process. The core mechanism involves leveraging verifiable rewards from an outcome verifier to provide on-the-fly feedback for both solution generation and self-verification tasks. In each iteration, the model generates solutions, then critiques its own on-policy generated solutions, with both trajectories contributing to the policy update. Extensive experiments on diverse mathematical reasoning benchmarks show that RISE consistently improves model's problem-solving accuracy while concurrently fostering strong self-verification skills. Our analyses highlight the advantages of online verification and the benefits of increased verification compute. Additionally, RISE models exhibit more frequent and accurate self-verification behaviors during reasoning. These advantages reinforce RISE as a flexible and effective path towards developing more robust and self-aware reasoners.
VisFactor: Benchmarking Fundamental Visual Cognition in Multimodal Large Language Models
Feb 23, 2025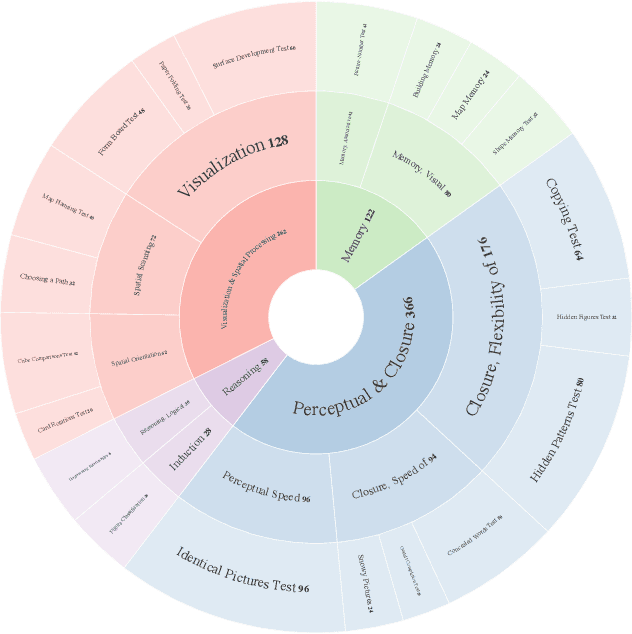
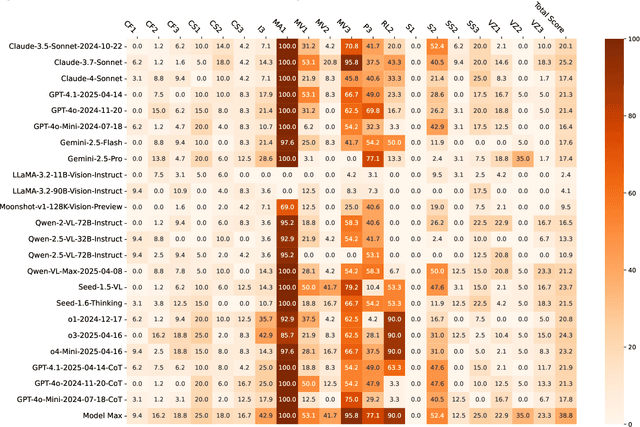
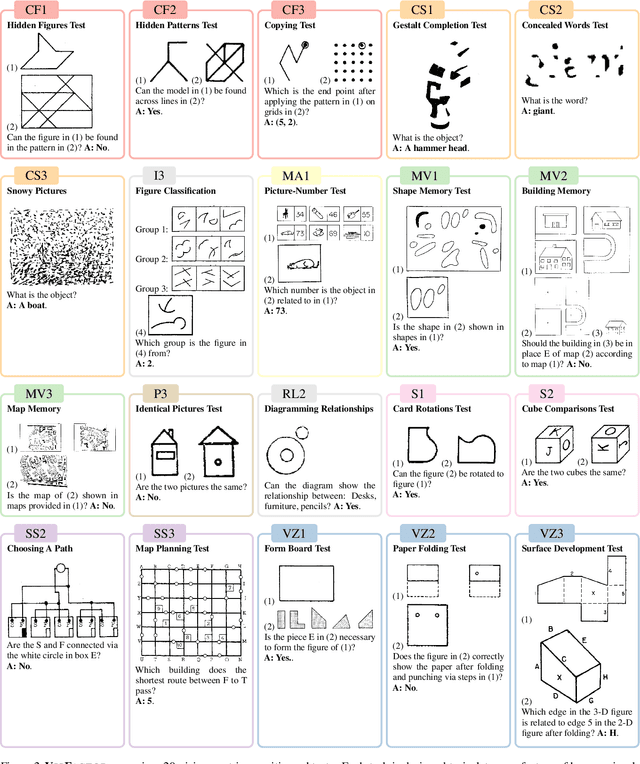

Multimodal Large Language Models (MLLMs) have demonstrated remarkable advancements in multimodal understanding; however, their fundamental visual cognitive abilities remain largely underexplored. To bridge this gap, we introduce VisFactor, a novel benchmark derived from the Factor-Referenced Cognitive Test (FRCT), a well-established psychometric assessment of human cognition. VisFactor digitalizes vision-related FRCT subtests to systematically evaluate MLLMs across essential visual cognitive tasks including spatial reasoning, perceptual speed, and pattern recognition. We present a comprehensive evaluation of state-of-the-art MLLMs, such as GPT-4o, Gemini-Pro, and Qwen-VL, using VisFactor under diverse prompting strategies like Chain-of-Thought and Multi-Agent Debate. Our findings reveal a concerning deficiency in current MLLMs' fundamental visual cognition, with performance frequently approaching random guessing and showing only marginal improvements even with advanced prompting techniques. These results underscore the critical need for focused research to enhance the core visual reasoning capabilities of MLLMs. To foster further investigation in this area, we release our VisFactor benchmark at https://github.com/CUHK-ARISE/VisFactor.
How Should I Build A Benchmark?
Jan 18, 2025Various benchmarks have been proposed to assess the performance of large language models (LLMs) in different coding scenarios. We refer to them as code-related benchmarks. However, there are no systematic guidelines by which such a benchmark should be developed to ensure its quality, reliability, and reproducibility. We propose How2Bench, which is comprised of a 55- 55-criteria checklist as a set of guidelines to govern the development of code-related benchmarks comprehensively. Using HOW2BENCH, we profiled 274 benchmarks released within the past decade and found concerning issues. Nearly 70% of the benchmarks did not take measures for data quality assurance; over 10% did not even open source or only partially open source. Many highly cited benchmarks have loopholes, including duplicated samples, incorrect reference codes/tests/prompts, and unremoved sensitive/confidential information. Finally, we conducted a human study involving 49 participants, which revealed significant gaps in awareness of the importance of data quality, reproducibility, and transparency.