 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTourPlanner: A Competitive Consensus Framework with Constraint-Gated Reinforcement Learning for Travel Planning
Jan 08, 2026Travel planning is a sophisticated decision-making process that requires synthesizing multifaceted information to construct itineraries. However, existing travel planning approaches face several challenges: (1) Pruning candidate points of interest (POIs) while maintaining a high recall rate; (2) A single reasoning path restricts the exploration capability within the feasible solution space for travel planning; (3) Simultaneously optimizing hard constraints and soft constraints remains a significant difficulty. To address these challenges, we propose TourPlanner, a comprehensive framework featuring multi-path reasoning and constraint-gated reinforcement learning. Specifically, we first introduce a Personalized Recall and Spatial Optimization (PReSO) workflow to construct spatially-aware candidate POIs' set. Subsequently, we propose Competitive consensus Chain-of-Thought (CCoT), a multi-path reasoning paradigm that improves the ability of exploring the feasible solution space. To further refine the plan, we integrate a sigmoid-based gating mechanism into the reinforcement learning stage, which dynamically prioritizes soft-constraint satisfaction only after hard constraints are met. Experimental results on travel planning benchmarks demonstrate that TourPlanner achieves state-of-the-art performance, significantly surpassing existing methods in both feasibility and user-preference alignment.
Agent2World: Learning to Generate Symbolic World Models via Adaptive Multi-Agent Feedback
Dec 26, 2025Symbolic world models (e.g., PDDL domains or executable simulators) are central to model-based planning, but training LLMs to generate such world models is limited by the lack of large-scale verifiable supervision. Current approaches rely primarily on static validation methods that fail to catch behavior-level errors arising from interactive execution. In this paper, we propose Agent2World, a tool-augmented multi-agent framework that achieves strong inference-time world-model generation and also serves as a data engine for supervised fine-tuning, by grounding generation in multi-agent feedback. Agent2World follows a three-stage pipeline: (i) A Deep Researcher agent performs knowledge synthesis by web searching to address specification gaps; (ii) A Model Developer agent implements executable world models; And (iii) a specialized Testing Team conducts adaptive unit testing and simulation-based validation. Agent2World demonstrates superior inference-time performance across three benchmarks spanning both Planning Domain Definition Language (PDDL) and executable code representations, achieving consistent state-of-the-art results. Beyond inference, Testing Team serves as an interactive environment for the Model Developer, providing behavior-aware adaptive feedback that yields multi-turn training trajectories. The model fine-tuned on these trajectories substantially improves world-model generation, yielding an average relative gain of 30.95% over the same model before training. Project page: https://agent2world.github.io.
LoopTool: Closing the Data-Training Loop for Robust LLM Tool Calls
Nov 18, 2025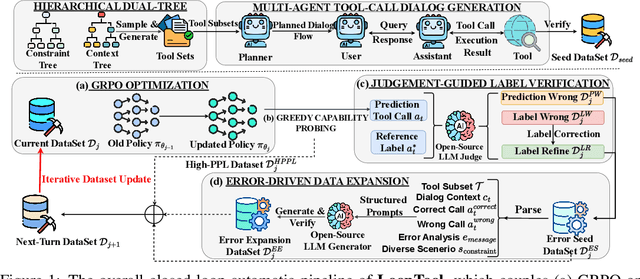
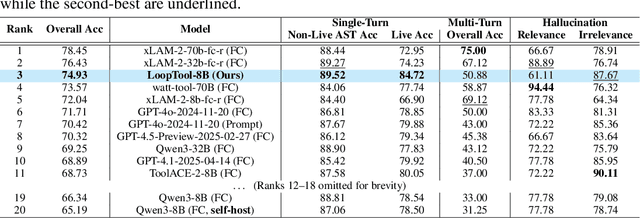
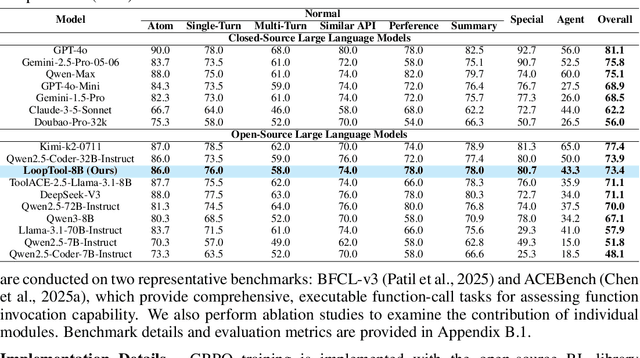
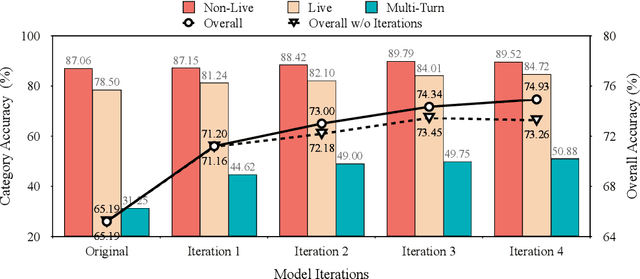
Augmenting Large Language Models (LLMs) with external tools enables them to execute complex, multi-step tasks. However, tool learning is hampered by the static synthetic data pipelines where data generation and model training are executed as two separate, non-interactive processes. This approach fails to adaptively focus on a model's specific weaknesses and allows noisy labels to persist, degrading training efficiency. We introduce LoopTool, a fully automated, model-aware data evolution framework that closes this loop by tightly integrating data synthesis and model training. LoopTool iteratively refines both the data and the model through three synergistic modules: (1) Greedy Capability Probing (GCP) diagnoses the model's mastered and failed capabilities; (2) Judgement-Guided Label Verification (JGLV) uses an open-source judge model to find and correct annotation errors, progressively purifying the dataset; and (3) Error-Driven Data Expansion (EDDE) generates new, challenging samples based on identified failures. This closed-loop process operates within a cost-effective, open-source ecosystem, eliminating dependence on expensive closed-source APIs. Experiments show that our 8B model trained with LoopTool significantly surpasses its 32B data generator and achieves new state-of-the-art results on the BFCL-v3 and ACEBench benchmarks for its scale. Our work demonstrates that closed-loop, self-refining data pipelines can dramatically enhance the tool-use capabilities of LLMs.
Fints: Efficient Inference-Time Personalization for LLMs with Fine-Grained Instance-Tailored Steering
Oct 31, 2025The rapid evolution of large language models (LLMs) has intensified the demand for effective personalization techniques that can adapt model behavior to individual user preferences. Despite the non-parametric methods utilizing the in-context learning ability of LLMs, recent parametric adaptation methods, including personalized parameter-efficient fine-tuning and reward modeling emerge. However, these methods face limitations in handling dynamic user patterns and high data sparsity scenarios, due to low adaptability and data efficiency. To address these challenges, we propose a fine-grained and instance-tailored steering framework that dynamically generates sample-level interference vectors from user data and injects them into the model's forward pass for personalized adaptation. Our approach introduces two key technical innovations: a fine-grained steering component that captures nuanced signals by hooking activations from attention and MLP layers, and an input-aware aggregation module that synthesizes these signals into contextually relevant enhancements. The method demonstrates high flexibility and data efficiency, excelling in fast-changing distribution and high data sparsity scenarios. In addition, the proposed method is orthogonal to existing methods and operates as a plug-in component compatible with different personalization techniques. Extensive experiments across diverse scenarios--including short-to-long text generation, and web function calling--validate the effectiveness and compatibility of our approach. Results show that our method significantly enhances personalization performance in fast-shifting environments while maintaining robustness across varying interaction modes and context lengths. Implementation is available at https://github.com/KounianhuaDu/Fints.
DeepCompress: A Dual Reward Strategy for Dynamically Exploring and Compressing Reasoning Chains
Oct 31, 2025Large Reasoning Models (LRMs) have demonstrated impressive capabilities but suffer from cognitive inefficiencies like ``overthinking'' simple problems and ``underthinking'' complex ones. While existing methods that use supervised fine-tuning~(SFT) or reinforcement learning~(RL) with token-length rewards can improve efficiency, they often do so at the cost of accuracy. This paper introduces \textbf{DeepCompress}, a novel framework that simultaneously enhances both the accuracy and efficiency of LRMs. We challenge the prevailing approach of consistently favoring shorter reasoning paths, showing that longer responses can contain a broader range of correct solutions for difficult problems. DeepCompress employs an adaptive length reward mechanism that dynamically classifies problems as ``Simple'' or ``Hard'' in real-time based on the model's evolving capability. It encourages shorter, more efficient reasoning for ``Simple'' problems while promoting longer, more exploratory thought chains for ``Hard'' problems. This dual-reward strategy enables the model to autonomously adjust its Chain-of-Thought (CoT) length, compressing reasoning for well-mastered problems and extending it for those it finds challenging. Experimental results on challenging mathematical benchmarks show that DeepCompress consistently outperforms baseline methods, achieving superior accuracy while significantly improving token efficiency.
DeepAgent: A General Reasoning Agent with Scalable Toolsets
Oct 24, 2025Large reasoning models have demonstrated strong problem-solving abilities, yet real-world tasks often require external tools and long-horizon interactions. Existing agent frameworks typically follow predefined workflows, which limit autonomous and global task completion. In this paper, we introduce DeepAgent, an end-to-end deep reasoning agent that performs autonomous thinking, tool discovery, and action execution within a single, coherent reasoning process. To address the challenges of long-horizon interactions, particularly the context length explosion from multiple tool calls and the accumulation of interaction history, we introduce an autonomous memory folding mechanism that compresses past interactions into structured episodic, working, and tool memories, reducing error accumulation while preserving critical information. To teach general-purpose tool use efficiently and stably, we develop an end-to-end reinforcement learning strategy, namely ToolPO, that leverages LLM-simulated APIs and applies tool-call advantage attribution to assign fine-grained credit to the tool invocation tokens. Extensive experiments on eight benchmarks, including general tool-use tasks (ToolBench, API-Bank, TMDB, Spotify, ToolHop) and downstream applications (ALFWorld, WebShop, GAIA, HLE), demonstrate that DeepAgent consistently outperforms baselines across both labeled-tool and open-set tool retrieval scenarios. This work takes a step toward more general and capable agents for real-world applications. The code and demo are available at https://github.com/RUC-NLPIR/DeepAgent.
Curing Miracle Steps in LLM Mathematical Reasoning with Rubric Rewards
Oct 09, 2025Large language models for mathematical reasoning are typically trained with outcome-based rewards, which credit only the final answer. In our experiments, we observe that this paradigm is highly susceptible to reward hacking, leading to a substantial overestimation of a model's reasoning ability. This is evidenced by a high incidence of false positives - solutions that reach the correct final answer through an unsound reasoning process. Through a systematic analysis with human verification, we establish a taxonomy of these failure modes, identifying patterns like Miracle Steps - abrupt jumps to a correct output without a valid preceding derivation. Probing experiments suggest a strong association between these Miracle Steps and memorization, where the model appears to recall the answer directly rather than deriving it. To mitigate this systemic issue, we introduce the Rubric Reward Model (RRM), a process-oriented reward function that evaluates the entire reasoning trajectory against problem-specific rubrics. The generative RRM provides fine-grained, calibrated rewards (0-1) that explicitly penalize logical flaws and encourage rigorous deduction. When integrated into a reinforcement learning pipeline, RRM-based training consistently outperforms outcome-only supervision across four math benchmarks. Notably, it boosts Verified Pass@1024 on AIME2024 from 26.7% to 62.6% and reduces the incidence of Miracle Steps by 71%. Our work demonstrates that rewarding the solution process is crucial for building models that are not only more accurate but also more reliable.
REA-RL: Reflection-Aware Online Reinforcement Learning for Efficient Large Reasoning Models
May 26, 2025Large Reasoning Models (LRMs) demonstrate strong performance in complex tasks but often face the challenge of overthinking, leading to substantially high inference costs. Existing approaches synthesize shorter reasoning responses for LRMs to learn, but are inefficient for online usage due to the time-consuming data generation and filtering processes. Meanwhile, online reinforcement learning mainly adopts a length reward to encourage short reasoning responses, but tends to lose the reflection ability and harm the performance. To address these issues, we propose REA-RL, which introduces a small reflection model for efficient scaling in online training, offering both parallel sampling and sequential revision. Besides, a reflection reward is designed to further prevent LRMs from favoring short yet non-reflective responses. Experiments show that both methods maintain or enhance performance while significantly improving inference efficiency. Their combination achieves a good balance between performance and efficiency, reducing inference costs by 35% without compromising performance. Further analysis demonstrates that our methods are effective by maintaining reflection frequency for hard problems while appropriately reducing it for simpler ones without losing reflection ability. Codes are available at https://github.com/hexuandeng/REA-RL.
Towards Evaluating Proactive Risk Awareness of Multimodal Language Models
May 23, 2025Human safety awareness gaps often prevent the timely recognition of everyday risks. In solving this problem, a proactive safety artificial intelligence (AI) system would work better than a reactive one. Instead of just reacting to users' questions, it would actively watch people's behavior and their environment to detect potential dangers in advance. Our Proactive Safety Bench (PaSBench) evaluates this capability through 416 multimodal scenarios (128 image sequences, 288 text logs) spanning 5 safety-critical domains. Evaluation of 36 advanced models reveals fundamental limitations: Top performers like Gemini-2.5-pro achieve 71% image and 64% text accuracy, but miss 45-55% risks in repeated trials. Through failure analysis, we identify unstable proactive reasoning rather than knowledge deficits as the primary limitation. This work establishes (1) a proactive safety benchmark, (2) systematic evidence of model limitations, and (3) critical directions for developing reliable protective AI. We believe our dataset and findings can promote the development of safer AI assistants that actively prevent harm rather than merely respond to requests. Our dataset can be found at https://huggingface.co/datasets/Youliang/PaSBench.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.