 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Calibration for Multimodal LLMs: An Empirical Study through Medical VQA
Jun 18, 2026Multimodal Large Language Models (MLLMs) show great potential in medical tasks, but their elicited confidence often misaligns with actual accuracy, potentially leading to misdiagnosis or overlooking correct advice. This study presents the first comprehensive analysis of the relationship between accuracy and confidence in medical MLLMs. It proposes a novel method that combines Multi-Strategy Fusion-Based Interrogation (MS-FBI) with auxiliary expert LLM assessment, aiming to improve confidence calibration in Medical Visual Question Answering (VQA). Experiments demonstrate that our method reduces the Expected Calibration Error (ECE) by an average of 40\% across three Medical VQA datasets, significantly enhancing MLLMs' reliability. The findings highlight the importance of domain-specific calibration for MLLMs in healthcare, offering a more trustworthy solution for AI-assisted diagnosis.
FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
Jun 09, 2026Conventional LLMs keep the full KV cache loaded during decoding, causing a severe GPU memory bottleneck for ultra-long context serving. In this report, we propose Lookahead Sparse Attention (LSA), a novel inference paradigm powered by a Neural Memory Indexer built upon the DeepSeek-V4 architecture. Rather than passively attending to all historical tokens, LSA proactively predicts future context demands and preserves only the query-critical KV chunks in the GPU memory. Crucially, we instantiate this architecture via a backbone-free decoupled training strategy. By formulating the indexer as a standard dual-encoder architecture, we train it independently using standard retrieval training frameworks without ever loading the massive backbone model into GPU memory. We demonstrate that this "less is more" paradigm significantly maximizes serving efficiency while acting as an effective attention denoiser in tasks that rely on long-term global memory. Across primary long-context evaluation suites (e.g., LongBench-v2, LongMemEval, and RULER), FM-DS-V4 compresses the average physical KV cache footprint down to merely 13.5% of the full-context baseline, while consistently preserving or slightly elevating downstream accuracy (+0.6% absolute margin on average). Crucially, at extreme 500K scales, FlashMemory suppresses the physical KV cache overhead by over 90% without destabilizing the backbone's core reasoning capacities.
Towards Robotic Dexterous Hand Intelligence: A Survey
May 13, 2026Robotic dexterous hands are central to contact-rich manipulation, with rapid progress driven by advances in hardware, sensing, control, simulation, and data generation. However, existing studies are often developed under different assumptions regarding hand embodiments, sensory configurations, task settings, training data, and evaluation protocols, making systematic comparison difficult and obscuring the developmental trajectory of the field. This survey provides a holistic review of dexterous hand research from four complementary aspects. First, we present a hardware-level analysis covering actuation, transmission, perception, and representative hand designs, highlighting the key trade-offs in force capability, compliance, bandwidth, integration, and system complexity. Furthermore, we review control and learning methods for dexterous manipulation from a methodological perspective, grouping representative works by major paradigms and tracing their evolution in chronological order. In addition, we consolidate datasets, modality design, and evaluation practices, which enables methodological progress to be interpreted together with the ways in which it is trained, benchmarked, and assessed. Finally, we discuss the major limitations of current dexterous hand research and summarize the corresponding future directions. By connecting hardware analysis, methodological development, data resources, and evaluation, this survey aims to provide a structured understanding of dexterous hand research and to clarify the most important open challenges for future study.
From $P(y|x)$ to $P(y)$: Investigating Reinforcement Learning in Pre-train Space
Apr 15, 2026While reinforcement learning with verifiable rewards (RLVR) significantly enhances LLM reasoning by optimizing the conditional distribution P(y|x), its potential is fundamentally bounded by the base model's existing output distribution. Optimizing the marginal distribution P(y) in the Pre-train Space addresses this bottleneck by encoding reasoning ability and preserving broad exploration capacity. Yet, conventional pre-training relies on static corpora for passive learning, leading to a distribution shift that hinders targeted reasoning enhancement. In this paper, we introduce PreRL (Pre-train Space RL), which applies reward-driven online updates directly to P(y). We theoretically and empirically validate the strong gradient alignment between log P(y) and log P(y|x), establishing PreRL as a viable surrogate for standard RL. Furthermore, we uncover a critical mechanism: Negative Sample Reinforcement (NSR) within PreRL serves as an exceptionally effective driver for reasoning. NSR-PreRL rapidly prunes incorrect reasoning spaces while stimulating endogenous reflective behaviors, increasing transition and reflection thoughts by 14.89x and 6.54x, respectively. Leveraging these insights, we propose Dual Space RL (DSRL), a Policy Reincarnation strategy that initializes models with NSR-PreRL to expand the reasoning horizon before transitioning to standard RL for fine-grained optimization. Extensive experiments demonstrate that DSRL consistently outperforms strong baselines, proving that pre-train space pruning effectively steers the policy toward a refined correct reasoning subspace.
The Pensieve Paradigm: Stateful Language Models Mastering Their Own Context
Feb 12, 2026In the world of Harry Potter, when Dumbledore's mind is overburdened, he extracts memories into a Pensieve to be revisited later. In the world of AI, while we possess the Pensieve-mature databases and retrieval systems, our models inexplicably lack the "wand" to operate it. They remain like a Dumbledore without agency, passively accepting a manually engineered context as their entire memory. This work finally places the wand in the model's hand. We introduce StateLM, a new class of foundation models endowed with an internal reasoning loop to manage their own state. We equip our model with a suite of memory tools, such as context pruning, document indexing, and note-taking, and train it to actively manage these tools. By learning to dynamically engineering its own context, our model breaks free from the architectural prison of a fixed window. Experiments across various model sizes demonstrate StateLM's effectiveness across diverse scenarios. On long-document QA tasks, StateLMs consistently outperform standard LLMs across all model scales; on the chat memory task, they achieve absolute accuracy improvements of 10% to 20% over standard LLMs. On the deep research task BrowseComp-Plus, the performance gap becomes even more pronounced: StateLM achieves up to 52% accuracy, whereas standard LLM counterparts struggle around 5%. Ultimately, our approach shifts LLMs from passive predictors to state-aware agents where reasoning becomes a stateful and manageable process.
Free(): Learning to Forget in Malloc-Only Reasoning Models
Feb 08, 2026Reasoning models enhance problem-solving by scaling test-time compute, yet they face a critical paradox: excessive thinking tokens often degrade performance rather than improve it. We attribute this to a fundamental architectural flaw: standard LLMs operate as "malloc-only" engines, continuously accumulating valid and redundant steps alike without a mechanism to prune obsolete information. To break this cycle, we propose Free()LM, a model that introduces an intrinsic self-forgetting capability via the Free-Module, a plug-and-play LoRA adapter. By iteratively switching between reasoning and cleaning modes, Free()LM dynamically identifies and prunes useless context chunks, maintaining a compact and noise-free state. Extensive experiments show that Free()LM provides consistent improvements across all model scales (8B to 685B). It achieves a 3.3% average improvement over top-tier reasoning baselines, even establishing a new SOTA on IMOanswerBench using DeepSeek V3.2-Speciale. Most notably, in long-horizon tasks where the standard Qwen3-235B-A22B model suffers a total collapse (0% accuracy), Free()LM restores performance to 50%. Our findings suggest that sustainable intelligence requires the freedom to forget as much as the power to think.
Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
Dec 22, 2025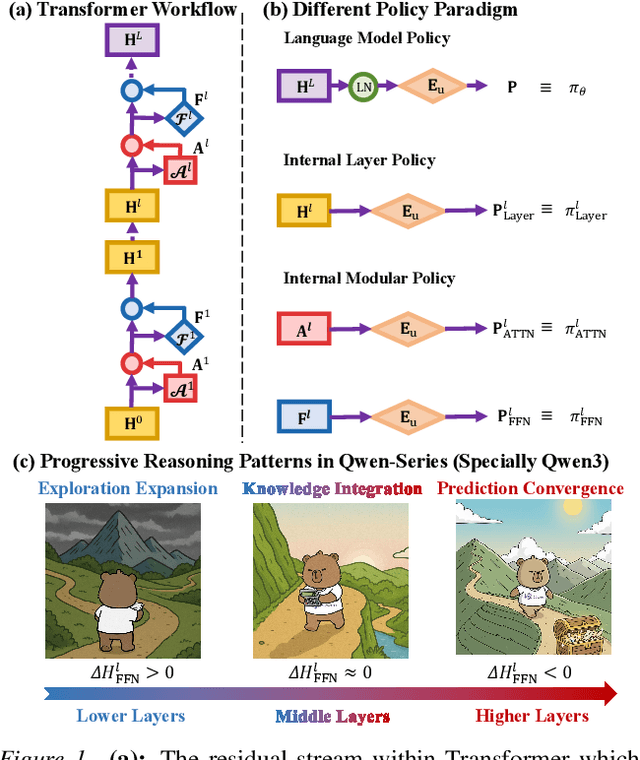
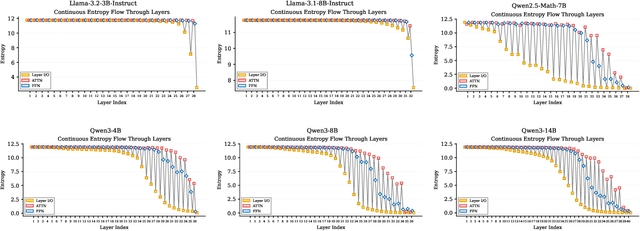
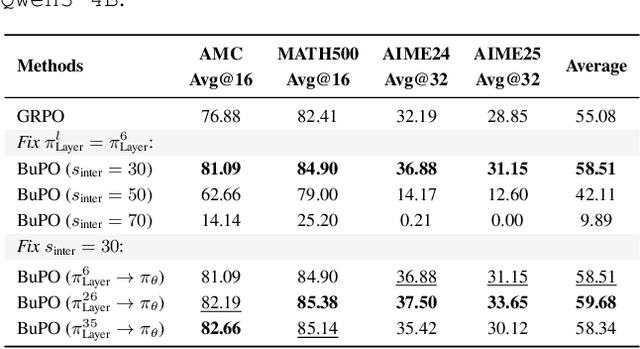
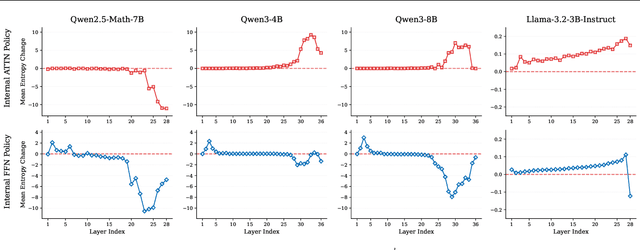
Existing reinforcement learning (RL) approaches treat large language models (LLMs) as a single unified policy, overlooking their internal mechanisms. Understanding how policy evolves across layers and modules is therefore crucial for enabling more targeted optimization and raveling out complex reasoning mechanisms. In this paper, we decompose the language model policy by leveraging the intrinsic split of the Transformer residual stream and the equivalence between the composition of hidden states with the unembedding matrix and the resulting samplable policy. This decomposition reveals Internal Layer Policies, corresponding to contributions from individual layers, and Internal Modular Policies, which align with the self-attention and feed-forward network (FFN) components within each layer. By analyzing the entropy of internal policy, we find that: (a) Early layers keep high entropy for exploration, top layers converge to near-zero entropy for refinement, with convergence patterns varying across model series. (b) LLama's prediction space rapidly converges in the final layer, whereas Qwen-series models, especially Qwen3, exhibit a more human-like, progressively structured reasoning pattern. Motivated by these findings, we propose Bottom-up Policy Optimization (BuPO), a novel RL paradigm that directly optimizes the internal layer policy during early training. By aligning training objective at lower layer, BuPO reconstructs foundational reasoning capabilities and achieves superior performance. Extensive experiments on complex reasoning benchmarks demonstrates the effectiveness of our method. Our code is available at https://github.com/Trae1ounG/BuPO.
DeepCompress: A Dual Reward Strategy for Dynamically Exploring and Compressing Reasoning Chains
Oct 31, 2025Large Reasoning Models (LRMs) have demonstrated impressive capabilities but suffer from cognitive inefficiencies like ``overthinking'' simple problems and ``underthinking'' complex ones. While existing methods that use supervised fine-tuning~(SFT) or reinforcement learning~(RL) with token-length rewards can improve efficiency, they often do so at the cost of accuracy. This paper introduces \textbf{DeepCompress}, a novel framework that simultaneously enhances both the accuracy and efficiency of LRMs. We challenge the prevailing approach of consistently favoring shorter reasoning paths, showing that longer responses can contain a broader range of correct solutions for difficult problems. DeepCompress employs an adaptive length reward mechanism that dynamically classifies problems as ``Simple'' or ``Hard'' in real-time based on the model's evolving capability. It encourages shorter, more efficient reasoning for ``Simple'' problems while promoting longer, more exploratory thought chains for ``Hard'' problems. This dual-reward strategy enables the model to autonomously adjust its Chain-of-Thought (CoT) length, compressing reasoning for well-mastered problems and extending it for those it finds challenging. Experimental results on challenging mathematical benchmarks show that DeepCompress consistently outperforms baseline methods, achieving superior accuracy while significantly improving token efficiency.
DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning
May 29, 2025


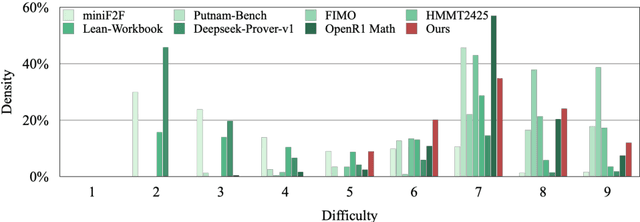
Theorem proving serves as a major testbed for evaluating complex reasoning abilities in large language models (LLMs). However, traditional automated theorem proving (ATP) approaches rely heavily on formal proof systems that poorly align with LLMs' strength derived from informal, natural language knowledge acquired during pre-training. In this work, we propose DeepTheorem, a comprehensive informal theorem-proving framework exploiting natural language to enhance LLM mathematical reasoning. DeepTheorem includes a large-scale benchmark dataset consisting of 121K high-quality IMO-level informal theorems and proofs spanning diverse mathematical domains, rigorously annotated for correctness, difficulty, and topic categories, accompanied by systematically constructed verifiable theorem variants. We devise a novel reinforcement learning strategy (RL-Zero) explicitly tailored to informal theorem proving, leveraging the verified theorem variants to incentivize robust mathematical inference. Additionally, we propose comprehensive outcome and process evaluation metrics examining proof correctness and the quality of reasoning steps. Extensive experimental analyses demonstrate DeepTheorem significantly improves LLM theorem-proving performance compared to existing datasets and supervised fine-tuning protocols, achieving state-of-the-art accuracy and reasoning quality. Our findings highlight DeepTheorem's potential to fundamentally advance automated informal theorem proving and mathematical exploration.
Two Experts Are All You Need for Steering Thinking: Reinforcing Cognitive Effort in MoE Reasoning Models Without Additional Training
May 20, 2025Mixture-of-Experts (MoE) architectures within Large Reasoning Models (LRMs) have achieved impressive reasoning capabilities by selectively activating experts to facilitate structured cognitive processes. Despite notable advances, existing reasoning models often suffer from cognitive inefficiencies like overthinking and underthinking. To address these limitations, we introduce a novel inference-time steering methodology called Reinforcing Cognitive Experts (RICE), designed to improve reasoning performance without additional training or complex heuristics. Leveraging normalized Pointwise Mutual Information (nPMI), we systematically identify specialized experts, termed ''cognitive experts'' that orchestrate meta-level reasoning operations characterized by tokens like ''<think>''. Empirical evaluations with leading MoE-based LRMs (DeepSeek-R1 and Qwen3-235B) on rigorous quantitative and scientific reasoning benchmarks demonstrate noticeable and consistent improvements in reasoning accuracy, cognitive efficiency, and cross-domain generalization. Crucially, our lightweight approach substantially outperforms prevalent reasoning-steering techniques, such as prompt design and decoding constraints, while preserving the model's general instruction-following skills. These results highlight reinforcing cognitive experts as a promising, practical, and interpretable direction to enhance cognitive efficiency within advanced reasoning models.