 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Phone-Use Agents Respect Your Privacy?
Apr 02, 2026We study whether phone-use agents respect privacy while completing benign mobile tasks. This question has remained hard to answer because privacy-compliant behavior is not operationalized for phone-use agents, and ordinary apps do not reveal exactly what data agents type into which form entries during execution. To make this question measurable, we introduce MyPhoneBench, a verifiable evaluation framework for privacy behavior in mobile agents. We operationalize privacy-respecting phone use as permissioned access, minimal disclosure, and user-controlled memory through a minimal privacy contract, iMy, and pair it with instrumented mock apps plus rule-based auditing that make unnecessary permission requests, deceptive re-disclosure, and unnecessary form filling observable and reproducible. Across five frontier models on 10 mobile apps and 300 tasks, we find that task success, privacy-compliant task completion, and later-session use of saved preferences are distinct capabilities, and no single model dominates all three. Evaluating success and privacy jointly reshuffles the model ordering relative to either metric alone. The most persistent failure mode across models is simple data minimization: agents still fill optional personal entries that the task does not require. These results show that privacy failures arise from over-helpful execution of benign tasks, and that success-only evaluation overestimates the deployment readiness of current phone-use agents. All code, mock apps, and agent trajectories are publicly available at~ https://github.com/FreedomIntelligence/MyPhoneBench.
DIVE: Scaling Diversity in Agentic Task Synthesis for Generalizable Tool Use
Mar 10, 2026Recent work synthesizes agentic tasks for post-training tool-using LLMs, yet robust generalization under shifts in tasks and toolsets remains an open challenge. We trace this brittleness to insufficient diversity in synthesized tasks. Scaling diversity is difficult because training requires tasks to remain executable and verifiable, while generalization demands coverage of diverse tool types, toolset combinations, and heterogeneous tool-use patterns. We propose DIVE, an evidence-driven recipe that inverts synthesis order, executing diverse, real-world tools first and reverse-deriving tasks strictly entailed by the resulting traces, thereby providing grounding by construction. DIVE scales structural diversity along two controllable axes, tool-pool coverage and per-task toolset variety, and an Evidence Collection--Task Derivation loop further induces rich multi-step tool-use patterns across 373 tools in five domains. Training Qwen3-8B on DIVE data (48k SFT + 3.2k RL) improves by +22 average points across 9 OOD benchmarks and outperforms the strongest 8B baseline by +68. Remarkably, controlled scaling analysis reveals that diversity scaling consistently outperforms quantity scaling for OOD generalization, even with 4x less data.
Unlearning of Knowledge Graph Embedding via Preference Optimization
Jul 28, 2025



Existing knowledge graphs (KGs) inevitably contain outdated or erroneous knowledge that needs to be removed from knowledge graph embedding (KGE) models. To address this challenge, knowledge unlearning can be applied to eliminate specific information while preserving the integrity of the remaining knowledge in KGs. Existing unlearning methods can generally be categorized into exact unlearning and approximate unlearning. However, exact unlearning requires high training costs while approximate unlearning faces two issues when applied to KGs due to the inherent connectivity of triples: (1) It fails to fully remove targeted information, as forgetting triples can still be inferred from remaining ones. (2) It focuses on local data for specific removal, which weakens the remaining knowledge in the forgetting boundary. To address these issues, we propose GraphDPO, a novel approximate unlearning framework based on direct preference optimization (DPO). Firstly, to effectively remove forgetting triples, we reframe unlearning as a preference optimization problem, where the model is trained by DPO to prefer reconstructed alternatives over the original forgetting triples. This formulation penalizes reliance on forgettable knowledge, mitigating incomplete forgetting caused by KG connectivity. Moreover, we introduce an out-boundary sampling strategy to construct preference pairs with minimal semantic overlap, weakening the connection between forgetting and retained knowledge. Secondly, to preserve boundary knowledge, we introduce a boundary recall mechanism that replays and distills relevant information both within and across time steps. We construct eight unlearning datasets across four popular KGs with varying unlearning rates. Experiments show that GraphDPO outperforms state-of-the-art baselines by up to 10.1% in MRR_Avg and 14.0% in MRR_F1.
QFFT, Question-Free Fine-Tuning for Adaptive Reasoning
Jun 15, 2025

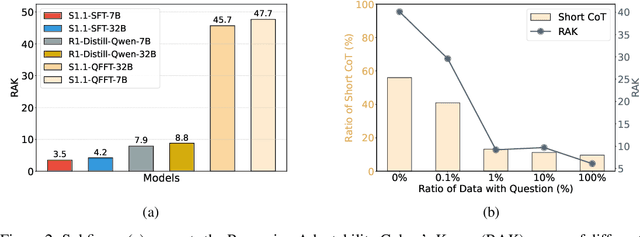

Recent advancements in Long Chain-of-Thought (CoT) reasoning models have improved performance on complex tasks, but they suffer from overthinking, which generates redundant reasoning steps, especially for simple questions. This paper revisits the reasoning patterns of Long and Short CoT models, observing that the Short CoT patterns offer concise reasoning efficiently, while the Long CoT patterns excel in challenging scenarios where the Short CoT patterns struggle. To enable models to leverage both patterns, we propose Question-Free Fine-Tuning (QFFT), a fine-tuning approach that removes the input question during training and learns exclusively from Long CoT responses. This approach enables the model to adaptively employ both reasoning patterns: it prioritizes the Short CoT patterns and activates the Long CoT patterns only when necessary. Experiments on various mathematical datasets demonstrate that QFFT reduces average response length by more than 50\%, while achieving performance comparable to Supervised Fine-Tuning (SFT). Additionally, QFFT exhibits superior performance compared to SFT in noisy, out-of-domain, and low-resource scenarios.
The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models
Mar 04, 2025
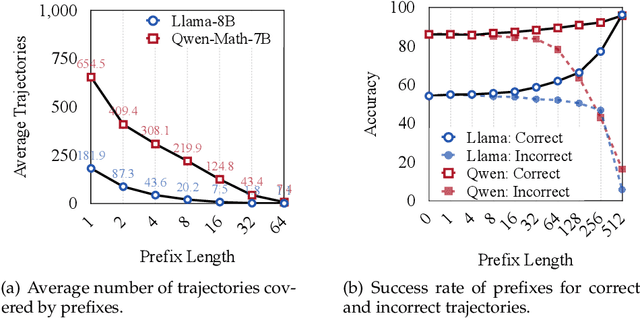
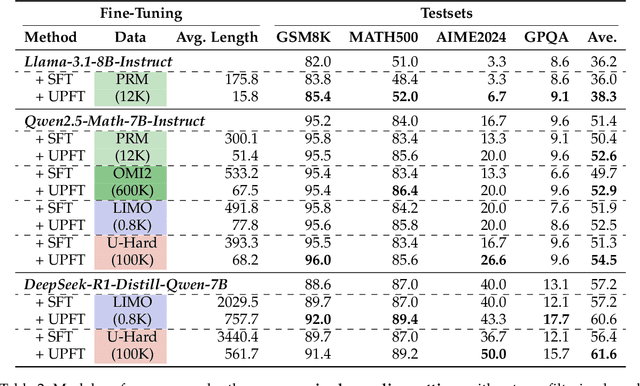

Improving the reasoning capabilities of large language models (LLMs) typically requires supervised fine-tuning with labeled data or computationally expensive sampling. We introduce Unsupervised Prefix Fine-Tuning (UPFT), which leverages the observation of Prefix Self-Consistency -- the shared initial reasoning steps across diverse solution trajectories -- to enhance LLM reasoning efficiency. By training exclusively on the initial prefix substrings (as few as 8 tokens), UPFT removes the need for labeled data or exhaustive sampling. Experiments on reasoning benchmarks show that UPFT matches the performance of supervised methods such as Rejection Sampling Fine-Tuning, while reducing training time by 75% and sampling cost by 99%. Further analysis reveals that errors tend to appear in later stages of the reasoning process and that prefix-based training preserves the model's structural knowledge. This work demonstrates how minimal unsupervised fine-tuning can unlock substantial reasoning gains in LLMs, offering a scalable and resource-efficient alternative to conventional approaches.
RAG-Instruct: Boosting LLMs with Diverse Retrieval-Augmented Instructions
Dec 31, 2024



Retrieval-Augmented Generation (RAG) has emerged as a key paradigm for enhancing large language models (LLMs) by incorporating external knowledge. However, current RAG methods face two limitations: (1) they only cover limited RAG scenarios. (2) They suffer from limited task diversity due to the lack of a general RAG dataset. To address these limitations, we propose RAG-Instruct, a general method for synthesizing diverse and high-quality RAG instruction data based on any source corpus. Our approach leverages (1) five RAG paradigms, which encompass diverse query-document relationships, and (2) instruction simulation, which enhances instruction diversity and quality by utilizing the strengths of existing instruction datasets. Using this method, we construct a 40K instruction dataset from Wikipedia, comprehensively covering diverse RAG scenarios and tasks. Experiments demonstrate that RAG-Instruct effectively enhances LLMs' RAG capabilities, achieving strong zero-shot performance and significantly outperforming various RAG baselines across a diverse set of tasks. RAG-Instruct is publicly available at https://github.com/FreedomIntelligence/RAG-Instruct.
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Dec 25, 2024



The breakthrough of OpenAI o1 highlights the potential of enhancing reasoning to improve LLM. Yet, most research in reasoning has focused on mathematical tasks, leaving domains like medicine underexplored. The medical domain, though distinct from mathematics, also demands robust reasoning to provide reliable answers, given the high standards of healthcare. However, verifying medical reasoning is challenging, unlike those in mathematics. To address this, we propose verifiable medical problems with a medical verifier to check the correctness of model outputs. This verifiable nature enables advancements in medical reasoning through a two-stage approach: (1) using the verifier to guide the search for a complex reasoning trajectory for fine-tuning LLMs, (2) applying reinforcement learning (RL) with verifier-based rewards to enhance complex reasoning further. Finally, we introduce HuatuoGPT-o1, a medical LLM capable of complex reasoning, which outperforms general and medical-specific baselines using only 40K verifiable problems. Experiments show complex reasoning improves medical problem-solving and benefits more from RL. We hope our approach inspires advancements in reasoning across medical and other specialized domains.
CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis
Jul 18, 2024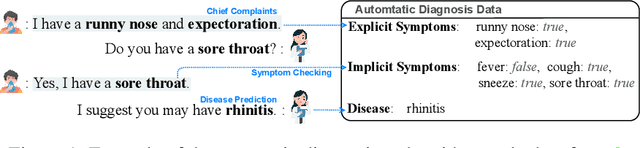
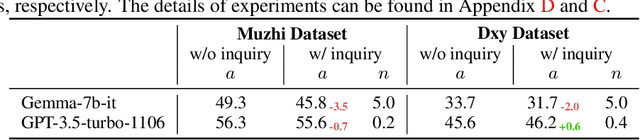
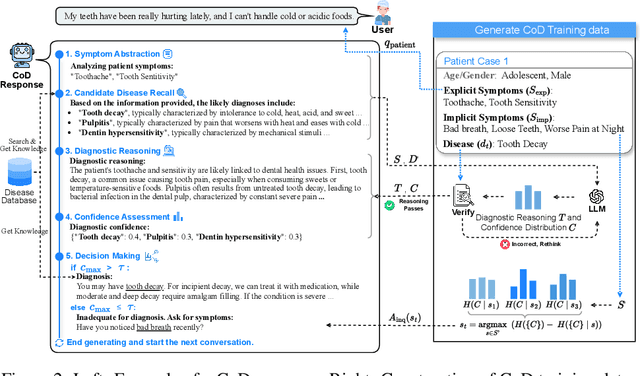

The field of medical diagnosis has undergone a significant transformation with the advent of large language models (LLMs), yet the challenges of interpretability within these models remain largely unaddressed. This study introduces Chain-of-Diagnosis (CoD) to enhance the interpretability of LLM-based medical diagnostics. CoD transforms the diagnostic process into a diagnostic chain that mirrors a physician's thought process, providing a transparent reasoning pathway. Additionally, CoD outputs the disease confidence distribution to ensure transparency in decision-making. This interpretability makes model diagnostics controllable and aids in identifying critical symptoms for inquiry through the entropy reduction of confidences. With CoD, we developed DiagnosisGPT, capable of diagnosing 9604 diseases. Experimental results demonstrate that DiagnosisGPT outperforms other LLMs on diagnostic benchmarks. Moreover, DiagnosisGPT provides interpretability while ensuring controllability in diagnostic rigor.
Domain-Hierarchy Adaptation via Chain of Iterative Reasoning for Few-shot Hierarchical Text Classification
Jul 12, 2024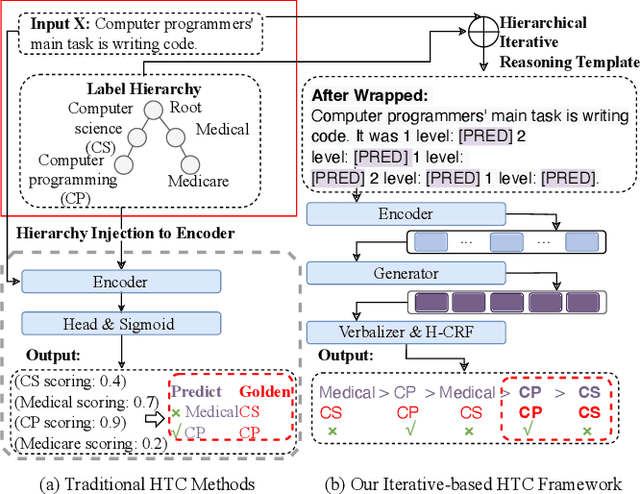
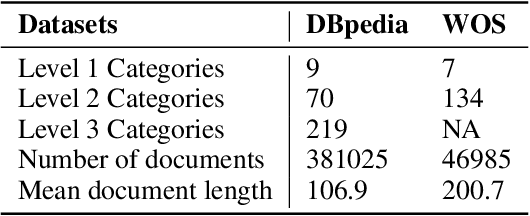
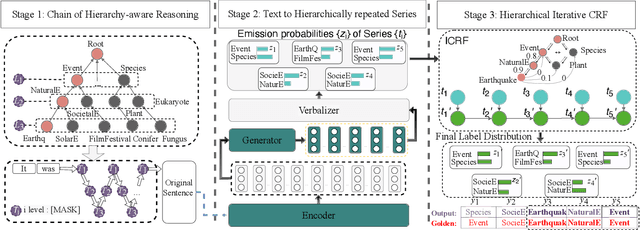
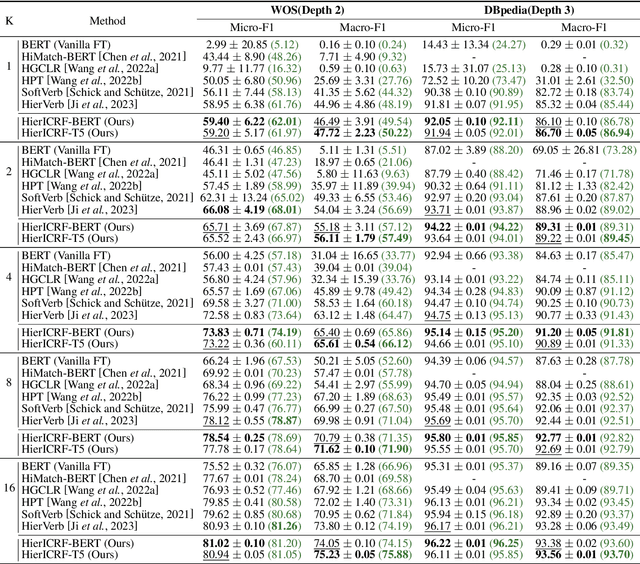
Recently, various pre-trained language models (PLMs) have been proposed to prove their impressive performances on a wide range of few-shot tasks. However, limited by the unstructured prior knowledge in PLMs, it is difficult to maintain consistent performance on complex structured scenarios, such as hierarchical text classification (HTC), especially when the downstream data is extremely scarce. The main challenge is how to transfer the unstructured semantic space in PLMs to the downstream domain hierarchy. Unlike previous work on HTC which directly performs multi-label classification or uses graph neural network (GNN) to inject label hierarchy, in this work, we study the HTC problem under a few-shot setting to adapt knowledge in PLMs from an unstructured manner to the downstream hierarchy. Technically, we design a simple yet effective method named Hierarchical Iterative Conditional Random Field (HierICRF) to search the most domain-challenging directions and exquisitely crafts domain-hierarchy adaptation as a hierarchical iterative language modeling problem, and then it encourages the model to make hierarchical consistency self-correction during the inference, thereby achieving knowledge transfer with hierarchical consistency preservation. We perform HierICRF on various architectures, and extensive experiments on two popular HTC datasets demonstrate that prompt with HierICRF significantly boosts the few-shot HTC performance with an average Micro-F1 by 28.80% to 1.50% and Macro-F1 by 36.29% to 1.5% over the previous state-of-the-art (SOTA) baselines under few-shot settings, while remaining SOTA hierarchical consistency performance.
Fast and Continual Knowledge Graph Embedding via Incremental LoRA
Jul 08, 2024



Continual Knowledge Graph Embedding (CKGE) aims to efficiently learn new knowledge and simultaneously preserve old knowledge. Dominant approaches primarily focus on alleviating catastrophic forgetting of old knowledge but neglect efficient learning for the emergence of new knowledge. However, in real-world scenarios, knowledge graphs (KGs) are continuously growing, which brings a significant challenge to fine-tuning KGE models efficiently. To address this issue, we propose a fast CKGE framework (\model), incorporating an incremental low-rank adapter (\mec) mechanism to efficiently acquire new knowledge while preserving old knowledge. Specifically, to mitigate catastrophic forgetting, \model\ isolates and allocates new knowledge to specific layers based on the fine-grained influence between old and new KGs. Subsequently, to accelerate fine-tuning, \model\ devises an efficient \mec\ mechanism, which embeds the specific layers into incremental low-rank adapters with fewer training parameters. Moreover, \mec\ introduces adaptive rank allocation, which makes the LoRA aware of the importance of entities and adjusts its rank scale adaptively. We conduct experiments on four public datasets and two new datasets with a larger initial scale. Experimental results demonstrate that \model\ can reduce training time by 34\%-49\% while still achieving competitive link prediction performance against state-of-the-art models on four public datasets (average MRR score of 21.0\% vs. 21.1\%).Meanwhile, on two newly constructed datasets, \model\ saves 51\%-68\% training time and improves link prediction performance by 1.5\%.