 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTri-Domain Multiuser MIMO Precoding Optimization and Channel Estimation with Spatial-EM Reconfigurable Antenna
May 22, 2026In this paper, we propose a tri-domain reconfigurable multiuser multiple-input multiple-output (MIMO) communication system that integrates the electromagnetic (EM) reconfigurable antenna (EMRA) with the spatially movable antenna (SMA), termed the spatial-EM reconfigurable antenna (SEMRA). The proposed system offers EM, spatial, and digital domain degrees of freedom (DoFs) for joint channel reconfiguration, yet introduces new challenges in channel estimation (CE) and precoding optimization. Specifically, for multiuser orthogonal frequency division multiplexing (OFDM) downlink, the precoding design is formulated as a tri-domain optimization problem over antenna positions, EM-domain radiation-pattern weights, and digital precoders. We first develop a zero-forcing (ZF)-based baseline algorithm to decouple the design of spatial reconfiguration, and then propose a weighted minimum mean square error (WMMSE)-based tri-domain joint optimization algorithm for further improving the spectral efficiency (SE). Furthermore, we propose a low-overhead movement-aided channel estimation scheme in which coordinated antenna repositioning across pilot slots synthesizes a denser virtual array, enabling more accurate angle-of-departure (AoD) estimation and EM-domain channel state information (eCSI) reconstruction under the same per-user pilot overhead as the EMRA baseline. The resulting parametric representation enables eCSI assembly at desired antenna positions without additional pilots. Simulation results show that the proposed CE scheme improves eCSI estimation accuracy and the proposed SEMRA achieves higher SE than the EMRA baseline under the same pilot overhead.
Linearizing Vision Transformer with Test-Time Training
May 04, 2026While linear-complexity attention mechanisms offer a promising alternative to Softmax attention for overcoming the quadratic bottleneck, training such models from scratch remains prohibitively expensive. Inheriting weights from pretrained Transformers provides an appealing shortcut, yet the fundamental representational gap between Softmax and linear attention prevents effective weight transfer. In this work, we address this conversion challenge from two perspectives: architectural alignment and representational alignment. We identify Test-Time Training (TTT) as a linear-complexity architecture whose two-layer dynamic formulation is structurally aligned with Softmax attention, enabling direct inheritance of pretrained attention weights. To further align representational properties, including key shift-invariance and locality, we introduce key instance normalization and a lightweight locality enhancement module. We validate our approach by linearizing Stable Diffusion 3.5 and introduce SD3.5-T$^5$ (Transformer To Test Time Training). With only 1 hour of fine-tuning on 4$\times$H20 GPUs, SD3.5-T$^5$ achieves comparable text-to-image quality to the fine-tuned Softmax model, while accelerating inference by 1.32$\times$ and 1.47$\times$ at 1K and 2K resolutions.
TREX: Automating LLM Fine-tuning via Agent-Driven Tree-based Exploration
Apr 15, 2026While Large Language Models (LLMs) have empowered AI research agents to perform isolated scientific tasks, automating complex, real-world workflows, such as LLM training, remains a significant challenge. In this paper, we introduce TREX, a multi-agent system that automates the entire LLM training life-cycle. By orchestrating collaboration between two core modules-the Researcher and the Executor-the system seamlessly performs requirement analysis, open-domain literature and data research, formulation of training strategies, preparation of data recipes, and model training and evaluation. The multi-round experimental process is modeled as a search tree, enabling the system to efficiently plan exploration paths, reuse historical results, and distill high-level insights from iterative trials. To evaluate the capability of automated LLM training, we construct FT-Bench, a benchmark comprising 10 tasks derived from real-world scenarios, ranging from optimizing fundamental model capabilities to enhancing performance on domain-specific tasks. Experimental results demonstrate that the TREX agent consistently optimizes model performance on target tasks.
Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
Mar 30, 2026We present Kernel-Smith, a framework for high-performance GPU kernel and operator generation that combines a stable evaluation-driven evolutionary agent with an evolution-oriented post-training recipe. On the agent side, Kernel-Smith maintains a population of executable candidates and iteratively improves them using an archive of top-performing and diverse programs together with structured execution feedback on compilation, correctness, and speedup. To make this search reliable, we build backend-specific evaluation services for Triton on NVIDIA GPUs and Maca on MetaX GPUs. On the training side, we convert long-horizon evolution trajectories into step-centric supervision and reinforcement learning signals by retaining correctness-preserving, high-gain revisions, so that the model is optimized as a strong local improver inside the evolutionary loop rather than as a one-shot generator. Under a unified evolutionary protocol, Kernel-Smith-235B-RL achieves state-of-the-art overall performance on KernelBench with Nvidia Triton backend, attaining the best average speedup ratio and outperforming frontier proprietary models including Gemini-3.0-pro and Claude-4.6-opus. We further validate the framework on the MetaX MACA backend, where our Kernel-Smith-MACA-30B surpasses large-scale counterparts such as DeepSeek-V3.2-think and Qwen3-235B-2507-think, highlighting potential for seamless adaptation across heterogeneous platforms. Beyond benchmark results, the same workflow produces upstream contributions to production systems including SGLang and LMDeploy, demonstrating that LLM-driven kernel optimization can transfer from controlled evaluation to practical deployment.
Provable Last-Iterate Convergence for Multi-Objective Safe LLM Alignment via Optimistic Primal-Dual
Feb 25, 2026Reinforcement Learning from Human Feedback (RLHF) plays a significant role in aligning Large Language Models (LLMs) with human preferences. While RLHF with expected reward constraints can be formulated as a primal-dual optimization problem, standard primal-dual methods only guarantee convergence with a distributional policy where the saddle-point problem is in convex-concave form. Moreover, standard primal-dual methods may exhibit instability or divergence in the last iterate under policy parameterization in practical applications. In this work, we propose a universal primal-dual framework for safe RLHF that unifies a broad class of existing alignment algorithms, including safe-RLHF, one-shot, and multi-shot based methods. Building on this framework, we introduce an optimistic primal-dual (OPD) algorithm that incorporates predictive updates for both primal and dual variables to stabilize saddle-point dynamics. We establish last-iterate convergence guarantees for the proposed method, covering both exact policy optimization in the distributional space and convergence to a neighborhood of the optimal solution whose gap is related to approximation error and bias under parameterized policies. Our analysis reveals that optimism plays a crucial role in mitigating oscillations inherent to constrained alignment objectives, thereby closing a key theoretical gap between constrained RL and practical RLHF.
DataChef: Cooking Up Optimal Data Recipes for LLM Adaptation via Reinforcement Learning
Feb 11, 2026In the current landscape of Large Language Models (LLMs), the curation of large-scale, high-quality training data is a primary driver of model performance. A key lever is the \emph{data recipe}, which comprises a data processing pipeline to transform raw sources into training corpora. Despite the growing use of LLMs to automate individual data processing steps, such as data synthesis and filtering, the overall design of data recipes remains largely manual and labor-intensive, requiring substantial human expertise and iteration. To bridge this gap, we formulate \emph{end-to-end data recipe generation} for LLM adaptation. Given a target benchmark and a pool of available data sources, a model is required to output a complete data recipe that adapts a base LLM to the target task. We present DataChef-32B, which performs online reinforcement learning using a proxy reward that predicts downstream performance for candidate recipes. Across six held-out tasks, DataChef-32B produces practical recipes that reach comparable downstream performance to those curated by human experts. Notably, the recipe from DataChef-32B adapts Qwen3-1.7B-Base to the math domain, achieving 66.7 on AIME'25 and surpassing Qwen3-1.7B. This work sheds new light on automating LLM training and developing self-evolving AI systems.
RouteMoA: Dynamic Routing without Pre-Inference Boosts Efficient Mixture-of-Agents
Jan 26, 2026Mixture-of-Agents (MoA) improves LLM performance through layered collaboration, but its dense topology raises costs and latency. Existing methods employ LLM judges to filter responses, yet still require all models to perform inference before judging, failing to cut costs effectively. They also lack model selection criteria and struggle with large model pools, where full inference is costly and can exceed context limits. To address this, we propose RouteMoA, an efficient mixture-of-agents framework with dynamic routing. It employs a lightweight scorer to perform initial screening by predicting coarse-grained performance from the query, narrowing candidates to a high-potential subset without inference. A mixture of judges then refines these scores through lightweight self- and cross-assessment based on existing model outputs, providing posterior correction without additional inference. Finally, a model ranking mechanism selects models by balancing performance, cost, and latency. RouteMoA outperforms MoA across varying tasks and model pool sizes, reducing cost by 89.8% and latency by 63.6% in the large-scale model pool.
AI Signal Processing Paradigm for Movable Antenna: From Geometric Optimization to Electromagnetic Reconfigurability
Oct 22, 2025As 6G wireless communication systems evolve toward intelligence and high reconfigurability, the limitations of traditional fixed antenna (TFA) has become increasingly prominent, with geometrically movable antenna (GMA) and electromagnetically reconfigurable antenna (ERA) emerging as key technologies to break through this bottleneck. GMA activates spatial degrees of freedom (DoF) by dynamically adjusting antenna positions, ERA regulates radiation characteristics using tunable metamaterials, thereby introducing DoF in the electromagnetic domain. However, the ``geometric-electromagnetic dual reconfiguration" paradigm formed by their integration poses severe challenges of high-dimensional hybrid optimization to signal processing. To address this issue, we integrate the geometric optimization of GMA and the electromagnetic reconfiguration of ERA for the first time, propose a unified modeling framework for movable and reconfigurable antenna (MARA), investigate the channel modeling and spectral efficiency (SE) optimization for GMA, ERA, and MARA. Besides, we systematically review artificial intelligence (AI)-based solutions, focusing on analyzing the advantages of AI over traditional algorithms in high-dimensional non-convex optimization computations. This paper fills the gap in existing literature regarding the lack of a comprehensive review on the AI-driven signal processing paradigm under geometric-electromagnetic dual reconfiguration and provides theoretical support for the design and optimization of 6G wireless systems with high SE and flexibility.
MIG: Automatic Data Selection for Instruction Tuning by Maximizing Information Gain in Semantic Space
Apr 18, 2025Data quality and diversity are key to the construction of effective instruction-tuning datasets. % With the increasing availability of open-source instruction-tuning datasets, it is advantageous to automatically select high-quality and diverse subsets from a vast amount of data. % Existing methods typically prioritize instance quality and use heuristic rules to maintain diversity. % However, this absence of a comprehensive view of the entire collection often leads to suboptimal results. % Moreover, heuristic rules generally focus on distance or clustering within the embedding space, which fails to accurately capture the intent of complex instructions in the semantic space. % To bridge this gap, we propose a unified method for quantifying the information content of datasets. This method models the semantic space by constructing a label graph and quantifies diversity based on the distribution of information within the graph. % Based on such a measurement, we further introduce an efficient sampling method that selects data samples iteratively to \textbf{M}aximize the \textbf{I}nformation \textbf{G}ain (MIG) in semantic space. % Experiments on various datasets and base models demonstrate that MIG consistently outperforms state-of-the-art methods. % Notably, the model fine-tuned with 5\% Tulu3 data sampled by MIG achieves comparable performance to the official SFT model trained on the full dataset, with improvements of +5.73\% on AlpacaEval and +6.89\% on Wildbench.
How to Find the Exact Pareto Front for Multi-Objective MDPs?
Oct 21, 2024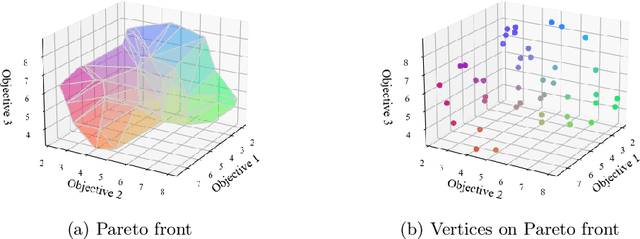
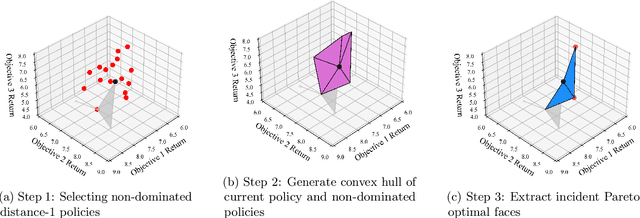
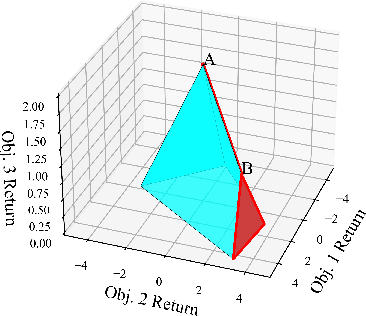
Multi-objective Markov Decision Processes (MDPs) are receiving increasing attention, as real-world decision-making problems often involve conflicting objectives that cannot be addressed by a single-objective MDP. The Pareto front identifies the set of policies that cannot be dominated, providing a foundation for finding optimal solutions that can efficiently adapt to various preferences. However, finding the Pareto front is a highly challenging problem. Most existing methods either (i) rely on traversing the continuous preference space, which is impractical and results in approximations that are difficult to evaluate against the true Pareto front, or (ii) focus solely on deterministic Pareto optimal policies, from which there are no known techniques to characterize the full Pareto front. Moreover, finding the structure of the Pareto front itself remains unclear even in the context of dynamic programming. This work addresses the challenge of efficiently discovering the Pareto front. By investigating the geometric structure of the Pareto front in MO-MDP, we uncover a key property: the Pareto front is on the boundary of a convex polytope whose vertices all correspond to deterministic policies, and neighboring vertices of the Pareto front differ by only one state-action pair of the deterministic policy, almost surely. This insight transforms the global comparison across all policies into a localized search among deterministic policies that differ by only one state-action pair, drastically reducing the complexity of searching for the exact Pareto front. We develop an efficient algorithm that identifies the vertices of the Pareto front by solving a single-objective MDP only once and then traversing the edges of the Pareto front, making it more efficient than existing methods. Our empirical studies demonstrate the effectiveness of our theoretical strategy in discovering the Pareto front.