 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LP-based Sampling Policy for Multi-Armed Bandits with Side-Observations and Stochastic Availability
Mar 27, 2026We study the stochastic multi-armed bandit (MAB) problem where an underlying network structure enables side-observations across related actions. We use a bipartite graph to link actions to a set of unknowns, such that selecting an action reveals observations for all the unknowns it is connected to. While previous works rely on the assumption that all actions are permanently accessible, we investigate the more practical setting of stochastic availability, where the set of feasible actions (the "activation set") varies dynamically in each round. This framework models real-world systems with both structural dependencies and volatility, such as social networks where users provide side-information about their peers' preferences, yet are not always online to be queried. To address this challenge, we propose UCB-LP-A, a novel policy that leverages a Linear Programming (LP) approach to optimize exploration-exploitation trade-offs under stochastic availability. Unlike standard network bandit algorithms that assume constant access, UCB-LP-A computes an optimal sampling distribution over the realizable activation sets, ensuring that the necessary observations are gathered using only the currently active arms. We derive a theoretical upper bound on the regret of our policy, characterizing the impact of both the network structure and the activation probabilities. Finally, we demonstrate through numerical simulations that UCB-LP-A significantly outperforms existing heuristics that ignore either the side-information or the availability constraints.
Beyond Freshness and Semantics: A Coupon-Collector Framework for Effective Status Updates
Mar 27, 2026For status update systems operating over unreliable energy-constrained wireless channels, we address Weaver's long-standing Level-C question: do my packets actually improve the plant's behavior? Each fresh sample carries a stochastic expiration time -- governed by the plant's instability dynamics -- after which the information becomes useless for control. Casting the problem as a coupon-collector variant with expiring coupons, we (i) formulate a two-dimensional average-reward MDP, (ii) prove that the optimal schedule is doubly thresholded in the receiver's freshness timer and the sender's stored lifetime, (iii) derive a closed-form policy for deterministic lifetimes, and (iv) design a Structure-Aware Q-learning algorithm (SAQ) that learns the optimal policy without knowing the channel success probability or lifetime distribution. Simulations validate our theoretical predictions: SAQ matches optimal Value Iteration performance while converging significantly faster than baseline Q-learning, and expiration-aware scheduling achieves up to 50% higher reward than age-based baselines by adapting transmissions to state-dependent urgency -- thereby delivering Level-C effectiveness under tight resource constraints.
Reinforcement Learning from Multi-Source Imperfect Preferences: Best-of-Both-Regimes Regret
Mar 20, 2026Reinforcement learning from human feedback (RLHF) replaces hard-to-specify rewards with pairwise trajectory preferences, yet regret-oriented theory often assumes that preference labels are generated consistently from a single ground-truth objective. In practical RLHF systems, however, feedback is typically \emph{multi-source} (annotators, experts, reward models, heuristics) and can exhibit systematic, persistent mismatches due to subjectivity, expertise variation, and annotation/modeling artifacts. We study episodic RL from \emph{multi-source imperfect preferences} through a cumulative imperfection budget: for each source, the total deviation of its preference probabilities from an ideal oracle is at most $ω$ over $K$ episodes. We propose a unified algorithm with regret $\tilde{O}(\sqrt{K/M}+ω)$, which exhibits a best-of-both-regimes behavior: it achieves $M$-dependent statistical gains when imperfection is small (where $M$ is the number of sources), while remaining robust with unavoidable additive dependence on $ω$ when imperfection is large. We complement this with a lower bound $\tildeΩ(\max\{\sqrt{K/M},ω\})$, which captures the best possible improvement with respect to $M$ and the unavoidable dependence on $ω$, and a counterexample showing that naïvely treating imperfect feedback as as oracle-consistent can incur regret as large as $\tildeΩ(\min\{ω\sqrt{K},K\})$. Technically, our approach involves imperfection-adaptive weighted comparison learning, value-targeted transition estimation to control hidden feedback-induced distribution shift, and sub-importance sampling to keep the weighted objectives analyzable, yielding regret guarantees that quantify when multi-source feedback provably improves RLHF and how cumulative imperfection fundamentally limits it.
Escaping Offline Pessimism: Vector-Field Reward Shaping for Safe Frontier Exploration
Mar 18, 2026While offline reinforcement learning provides reliable policies for real-world deployment, its inherent pessimism severely restricts an agent's ability to explore and collect novel data online. Drawing inspiration from safe reinforcement learning, exploring near the boundary of regions well covered by the offline dataset and reliably modeled by the simulator allows an agent to take manageable risks--venturing into informative but moderate-uncertainty states while remaining close enough to familiar regions for safe recovery. However, naively rewarding this boundary-seeking behavior can lead to a degenerate parking behavior, where the agent simply stops once it reaches the frontier. To solve this, we propose a novel vector-field reward shaping paradigm designed to induce continuous, safe boundary exploration for non-adaptive deployed policies. Operating on an uncertainty oracle trained from offline data, our reward combines two complementary components: a gradient-alignment term that attracts the agent toward a target uncertainty level, and a rotational-flow term that promotes motion along the local tangent plane of the uncertainty manifold. Through theoretical analysis, we show that this reward structure naturally induces sustained exploratory behavior along the boundary while preventing degenerate solutions. Empirically, by integrating our proposed reward shaping with Soft Actor-Critic on a 2D continuous navigation task, we validate that agents successfully traverse uncertainty boundaries while balancing safe, informative data collection with primary task completion.
Constraint-Rectified Training for Efficient Chain-of-Thought
Feb 13, 2026Chain-of-Thought (CoT) has significantly enhanced the reasoning capabilities of Large Language Models (LLMs), especially when combined with reinforcement learning (RL) based post-training methods. While longer reasoning traces can improve answer quality and unlock abilities such as self-correction, they also incur high inference costs and often introduce redundant steps, known as overthinking. Recent research seeks to develop efficient reasoning strategies that balance reasoning length and accuracy, either through length-aware reward design or prompt-based calibration. However, these heuristic-based approaches may suffer from severe accuracy drop and be very sensitive to hyperparameters. To address these problems, we introduce CRT (Constraint-Rectified Training), a principled post-training framework based on reference-guarded constrained optimization, yielding a more stable and interpretable formulation for efficient reasoning. CRT alternates between minimizing reasoning length and rectifying accuracy only when performance falls below the reference, enabling stable and effective pruning of redundant reasoning. We further extend CRT with a two-stage training scheme that first discovers the shortest reliable reasoning patterns and then refines accuracy under a learnt length budget, preventing the re-emergence of verbose CoT. Our comprehensive evaluation shows that this framework consistently reduces token usage while maintaining answer quality at a robust and reliable level. Further analysis reveals that CRT improves reasoning efficiency not only by shortening responses but also by reducing internal language redundancy, leading to a new evaluation metric. Moreover, CRT-based training naturally yields a sequence of intermediate checkpoints that span a spectrum of explanation lengths while preserving correctness, enabling fine-grained control over reasoning verbosity without retraining.
Mixture-of-Transformers Learn Faster: A Theoretical Study on Classification Problems
Oct 30, 2025Mixture-of-Experts (MoE) models improve transformer efficiency but lack a unified theoretical explanation, especially when both feed-forward and attention layers are allowed to specialize. To this end, we study the Mixture-of-Transformers (MoT), a tractable theoretical framework in which each transformer block acts as an expert governed by a continuously trained gating network. This design allows us to isolate and study the core learning dynamics of expert specialization and attention alignment. In particular, we develop a three-stage training algorithm with continuous training of the gating network, and show that each transformer expert specializes in a distinct class of tasks and that the gating network accurately routes data samples to the correct expert. Our analysis shows how expert specialization reduces gradient conflicts and makes each subtask strongly convex. We prove that the training drives the expected prediction loss to near zero in $O(\log(\epsilon^{-1}))$ iteration steps, significantly improving over the $O(\epsilon^{-1})$ rate for a single transformer. We further validate our theoretical findings through extensive real-data experiments, demonstrating the practical effectiveness of MoT. Together, these results offer the first unified theoretical account of transformer-level specialization and learning dynamics, providing practical guidance for designing efficient large-scale models.
Monitoring State Transitions in Markovian Systems with Sampling Cost
Oct 25, 2025We consider a node-monitor pair, where the node's state varies with time. The monitor needs to track the node's state at all times; however, there is a fixed cost for each state query. So the monitor may instead predict the state using time-series forecasting methods, including time-series foundation models (TSFMs), and query only when prediction uncertainty is high. Since query decisions influence prediction accuracy, determining when to query is nontrivial. A natural approach is a greedy policy that predicts when the expected prediction loss is below the query cost and queries otherwise. We analyze this policy in a Markovian setting, where the optimal (OPT) strategy is a state-dependent threshold policy minimizing the time-averaged sum of query cost and prediction losses. We show that, in general, the greedy policy is suboptimal and can have an unbounded competitive ratio, but under common conditions such as identically distributed transition probabilities, it performs close to OPT. For the case of unknown transition probabilities, we further propose a projected stochastic gradient descent (PSGD)-based learning variant of the greedy policy, which achieves a favorable predict-query tradeoff with improved computational efficiency compared to OPT.
Provably Efficient RL for Linear MDPs under Instantaneous Safety Constraints in Non-Convex Feature Spaces
Feb 25, 2025
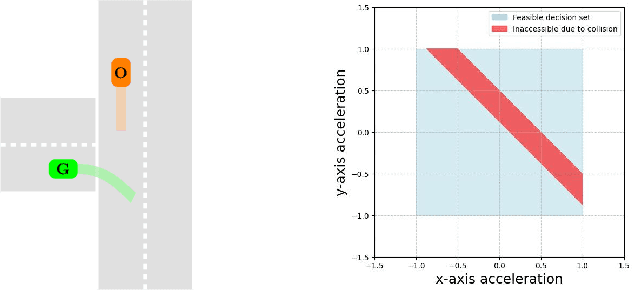
In Reinforcement Learning (RL), tasks with instantaneous hard constraints present significant challenges, particularly when the decision space is non-convex or non-star-convex. This issue is especially relevant in domains like autonomous vehicles and robotics, where constraints such as collision avoidance often take a non-convex form. In this paper, we establish a regret bound of $\tilde{\mathcal{O}}\bigl(\bigl(1 + \tfrac{1}{\tau}\bigr) \sqrt{\log(\tfrac{1}{\tau}) d^3 H^4 K} \bigr)$, applicable to both star-convex and non-star-convex cases, where $d$ is the feature dimension, $H$ the episode length, $K$ the number of episodes, and $\tau$ the safety threshold. Moreover, the violation of safety constraints is zero with high probability throughout the learning process. A key technical challenge in these settings is bounding the covering number of the value-function class, which is essential for achieving value-aware uniform concentration in model-free function approximation. For the star-convex setting, we develop a novel technique called Objective Constraint-Decomposition (OCD) to properly bound the covering number. This result also resolves an error in a previous work on constrained RL. In non-star-convex scenarios, where the covering number can become infinitely large, we propose a two-phase algorithm, Non-Convex Safe Least Squares Value Iteration (NCS-LSVI), which first reduces uncertainty about the safe set by playing a known safe policy. After that, it carefully balances exploration and exploitation to achieve the regret bound. Finally, numerical simulations on an autonomous driving scenario demonstrate the effectiveness of NCS-LSVI.
Provably Efficient Multi-Objective Bandit Algorithms under Preference-Centric Customization
Feb 19, 2025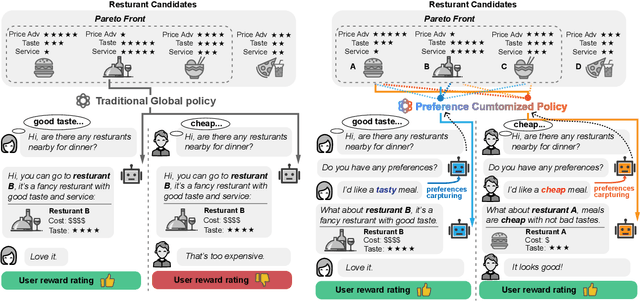
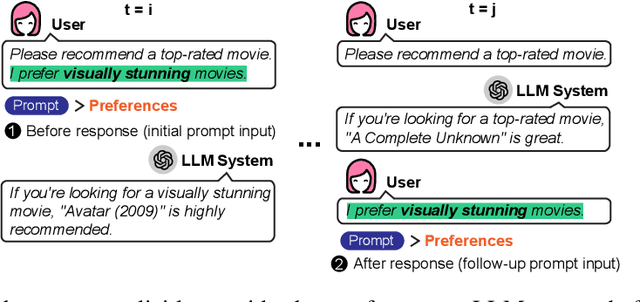
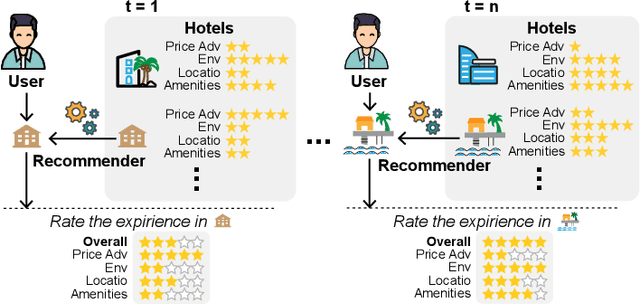
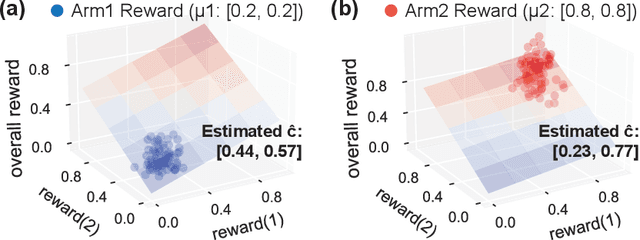
Multi-objective multi-armed bandit (MO-MAB) problems traditionally aim to achieve Pareto optimality. However, real-world scenarios often involve users with varying preferences across objectives, resulting in a Pareto-optimal arm that may score high for one user but perform quite poorly for another. This highlights the need for customized learning, a factor often overlooked in prior research. To address this, we study a preference-aware MO-MAB framework in the presence of explicit user preference. It shifts the focus from achieving Pareto optimality to further optimizing within the Pareto front under preference-centric customization. To our knowledge, this is the first theoretical study of customized MO-MAB optimization with explicit user preferences. Motivated by practical applications, we explore two scenarios: unknown preference and hidden preference, each presenting unique challenges for algorithm design and analysis. At the core of our algorithms are preference estimation and preference-aware optimization mechanisms to adapt to user preferences effectively. We further develop novel analytical techniques to establish near-optimal regret of the proposed algorithms. Strong empirical performance confirm the effectiveness of our approach.
BeST -- A Novel Source Selection Metric for Transfer Learning
Jan 19, 2025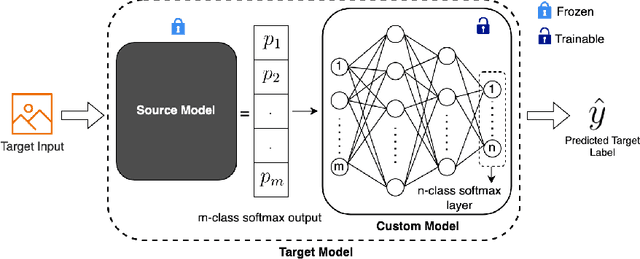

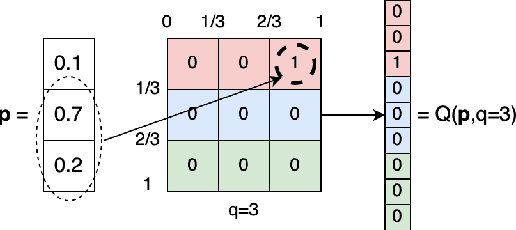

One of the most fundamental, and yet relatively less explored, goals in transfer learning is the efficient means of selecting top candidates from a large number of previously trained models (optimized for various "source" tasks) that would perform the best for a new "target" task with a limited amount of data. In this paper, we undertake this goal by developing a novel task-similarity metric (BeST) and an associated method that consistently performs well in identifying the most transferrable source(s) for a given task. In particular, our design employs an innovative quantization-level optimization procedure in the context of classification tasks that yields a measure of similarity between a source model and the given target data. The procedure uses a concept similar to early stopping (usually implemented to train deep neural networks (DNNs) to ensure generalization) to derive a function that approximates the transfer learning mapping without training. The advantage of our metric is that it can be quickly computed to identify the top candidate(s) for a given target task before a computationally intensive transfer operation (typically using DNNs) can be implemented between the selected source and the target task. As such, our metric can provide significant computational savings for transfer learning from a selection of a large number of possible source models. Through extensive experimental evaluations, we establish that our metric performs well over different datasets and varying numbers of data samples.