 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Transformers Learn Faster: A Theoretical Study on Classification Problems
Oct 30, 2025Mixture-of-Experts (MoE) models improve transformer efficiency but lack a unified theoretical explanation, especially when both feed-forward and attention layers are allowed to specialize. To this end, we study the Mixture-of-Transformers (MoT), a tractable theoretical framework in which each transformer block acts as an expert governed by a continuously trained gating network. This design allows us to isolate and study the core learning dynamics of expert specialization and attention alignment. In particular, we develop a three-stage training algorithm with continuous training of the gating network, and show that each transformer expert specializes in a distinct class of tasks and that the gating network accurately routes data samples to the correct expert. Our analysis shows how expert specialization reduces gradient conflicts and makes each subtask strongly convex. We prove that the training drives the expected prediction loss to near zero in $O(\log(\epsilon^{-1}))$ iteration steps, significantly improving over the $O(\epsilon^{-1})$ rate for a single transformer. We further validate our theoretical findings through extensive real-data experiments, demonstrating the practical effectiveness of MoT. Together, these results offer the first unified theoretical account of transformer-level specialization and learning dynamics, providing practical guidance for designing efficient large-scale models.
Provable In-Context Learning of Nonlinear Regression with Transformers
Jul 28, 2025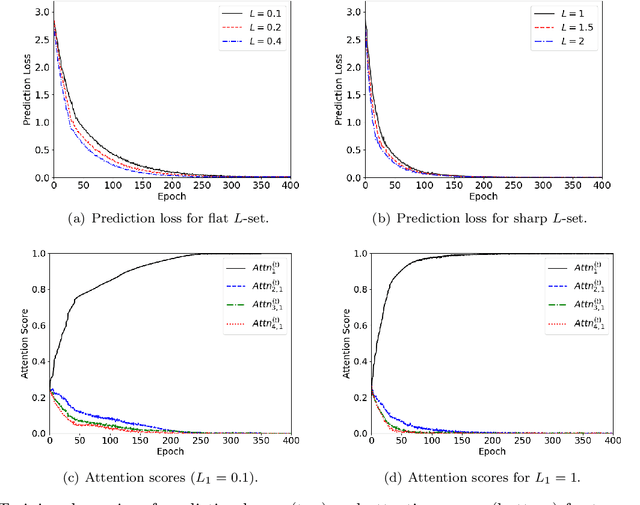
The transformer architecture, which processes sequences of input tokens to produce outputs for query tokens, has revolutionized numerous areas of machine learning. A defining feature of transformers is their ability to perform previously unseen tasks using task-specific prompts without updating parameters, a phenomenon known as in-context learning (ICL). Recent research has actively explored the training dynamics behind ICL, with much of the focus on relatively simple tasks such as linear regression and binary classification. To advance the theoretical understanding of ICL, this paper investigates more complex nonlinear regression tasks, aiming to uncover how transformers acquire in-context learning capabilities in these settings. We analyze the stage-wise dynamics of attention during training: attention scores between a query token and its target features grow rapidly in the early phase, then gradually converge to one, while attention to irrelevant features decays more slowly and exhibits oscillatory behavior. Our analysis introduces new proof techniques that explicitly characterize how the nature of general non-degenerate L-Lipschitz task functions affects attention weights. Specifically, we identify that the Lipschitz constant L of nonlinear function classes as a key factor governing the convergence dynamics of transformers in ICL. Leveraging these insights, for two distinct regimes depending on whether L is below or above a threshold, we derive different time bounds to guarantee near-zero prediction error. Notably, despite the convergence time depending on the underlying task functions, we prove that query tokens consistently attend to prompt tokens with highly relevant features at convergence, demonstrating the ICL capability of transformers for unseen functions.
MLEP: Multi-granularity Local Entropy Patterns for Universal AI-generated Image Detection
Apr 18, 2025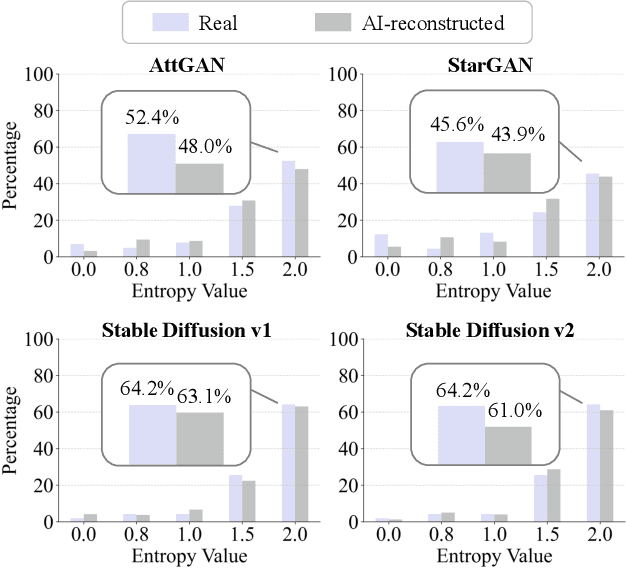
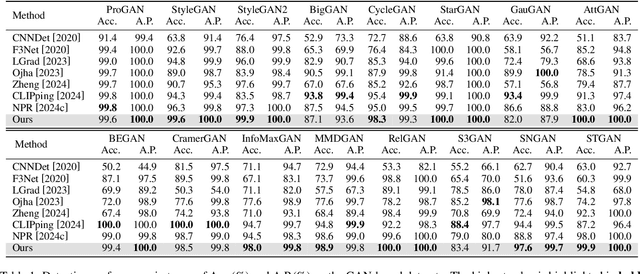
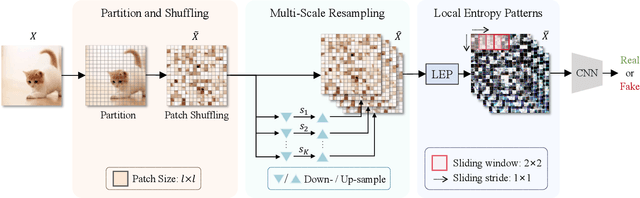
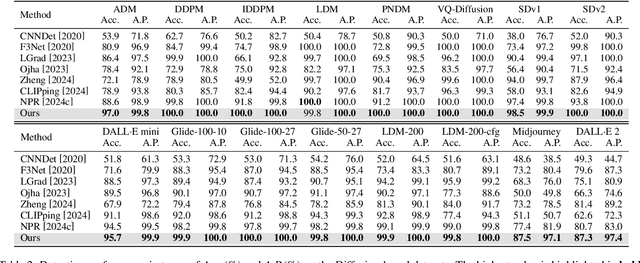
Advancements in image generation technologies have raised significant concerns about their potential misuse, such as producing misinformation and deepfakes. Therefore, there is an urgent need for effective methods to detect AI-generated images (AIGI). Despite progress in AIGI detection, achieving reliable performance across diverse generation models and scenes remains challenging due to the lack of source-invariant features and limited generalization capabilities in existing methods. In this work, we explore the potential of using image entropy as a cue for AIGI detection and propose Multi-granularity Local Entropy Patterns (MLEP), a set of entropy feature maps computed across shuffled small patches over multiple image scaled. MLEP comprehensively captures pixel relationships across dimensions and scales while significantly disrupting image semantics, reducing potential content bias. Leveraging MLEP, a robust CNN-based classifier for AIGI detection can be trained. Extensive experiments conducted in an open-world scenario, evaluating images synthesized by 32 distinct generative models, demonstrate significant improvements over state-of-the-art methods in both accuracy and generalization.
Big Brother is Watching: Proactive Deepfake Detection via Learnable Hidden Face
Apr 15, 2025As deepfake technologies continue to advance, passive detection methods struggle to generalize with various forgery manipulations and datasets. Proactive defense techniques have been actively studied with the primary aim of preventing deepfake operation effectively working. In this paper, we aim to bridge the gap between passive detection and proactive defense, and seek to solve the detection problem utilizing a proactive methodology. Inspired by several watermarking-based forensic methods, we explore a novel detection framework based on the concept of ``hiding a learnable face within a face''. Specifically, relying on a semi-fragile invertible steganography network, a secret template image is embedded into a host image imperceptibly, acting as an indicator monitoring for any malicious image forgery when being restored by the inverse steganography process. Instead of being manually specified, the secret template is optimized during training to resemble a neutral facial appearance, just like a ``big brother'' hidden in the image to be protected. By incorporating a self-blending mechanism and robustness learning strategy with a simulative transmission channel, a robust detector is built to accurately distinguish if the steganographic image is maliciously tampered or benignly processed. Finally, extensive experiments conducted on multiple datasets demonstrate the superiority of the proposed approach over competing passive and proactive detection methods.
Competitive Multi-armed Bandit Games for Resource Sharing
Mar 26, 2025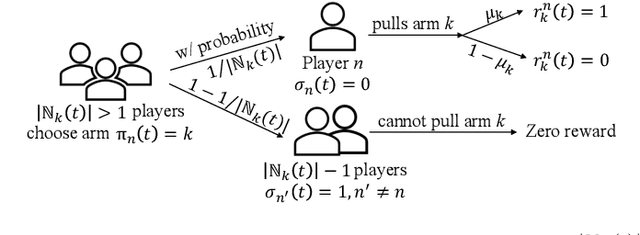
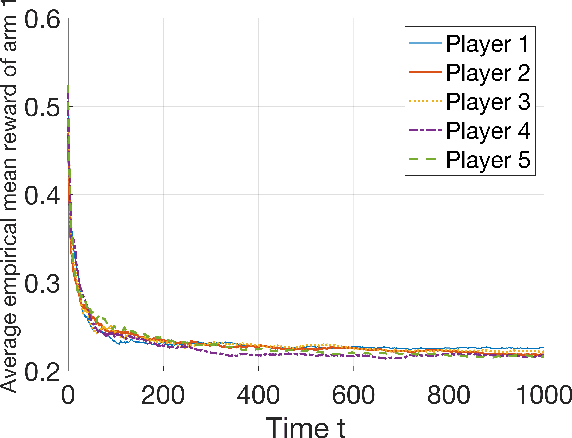
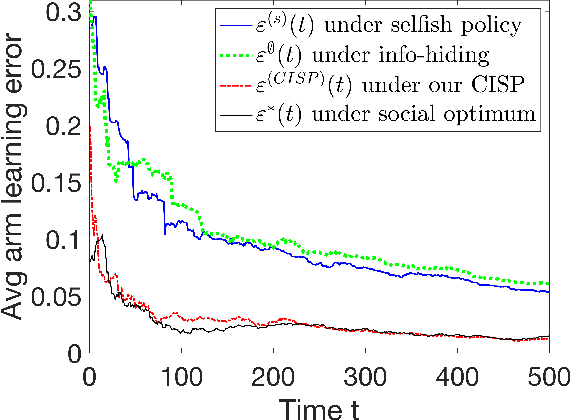
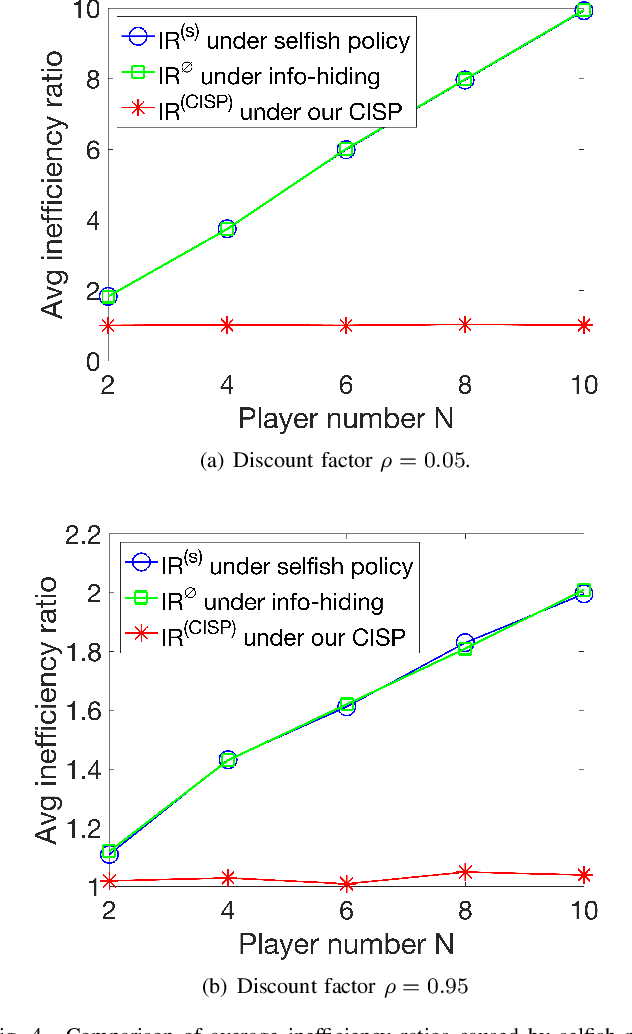
In modern resource-sharing systems, multiple agents access limited resources with unknown stochastic conditions to perform tasks. When multiple agents access the same resource (arm) simultaneously, they compete for successful usage, leading to contention and reduced rewards. This motivates our study of competitive multi-armed bandit (CMAB) games. In this paper, we study a new N-player K-arm competitive MAB game, where non-myopic players (agents) compete with each other to form diverse private estimations of unknown arms over time. Their possible collisions on same arms and time-varying nature of arm rewards make the policy analysis more involved than existing studies for myopic players. We explicitly analyze the threshold-based structures of social optimum and existing selfish policy, showing that the latter causes prolonged convergence time $\Omega(\frac{K}{\eta^2}\ln({\frac{KN}{\delta}}))$, while socially optimal policy with coordinated communication reduces it to $\mathcal{O}(\frac{K}{N\eta^2}\ln{(\frac{K}{\delta})})$. Based on the comparison, we prove that the competition among selfish players for the best arm can result in an infinite price of anarchy (PoA), indicating an arbitrarily large efficiency loss compared to social optimum. We further prove that no informational (non-monetary) mechanism (including Bayesian persuasion) can reduce the infinite PoA, as the strategic misreporting by non-myopic players undermines such approaches. To address this, we propose a Combined Informational and Side-Payment (CISP) mechanism, which provides socially optimal arm recommendations with proper informational and monetary incentives to players according to their time-varying private beliefs. Our CISP mechanism keeps ex-post budget balanced for social planner and ensures truthful reporting from players, achieving the minimum PoA=1 and same convergence time as social optimum.
To Analyze and Regulate Human-in-the-loop Learning for Congestion Games
Jan 06, 2025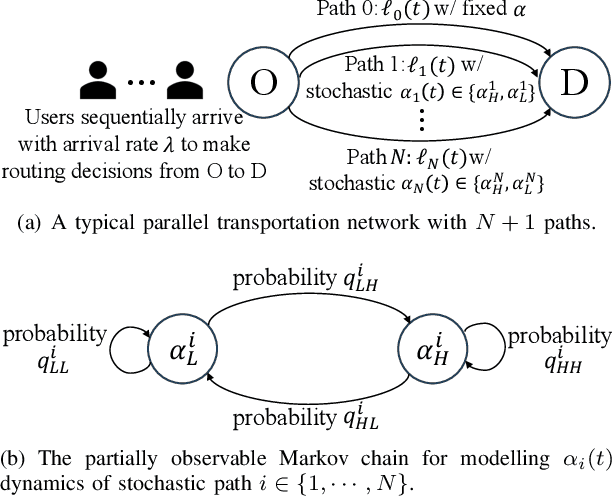
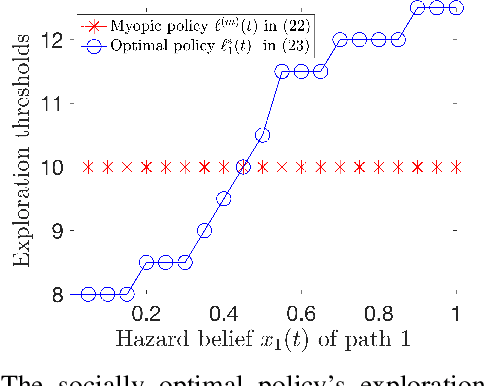
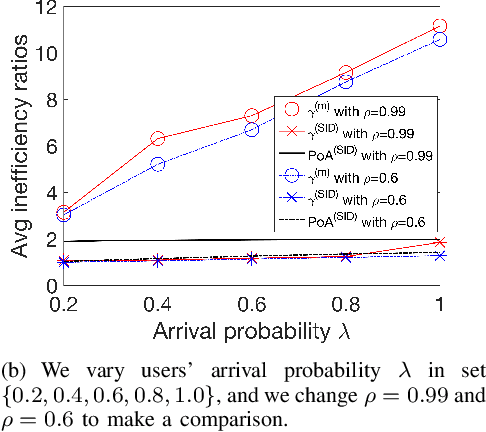

In congestion games, selfish users behave myopically to crowd to the shortest paths, and the social planner designs mechanisms to regulate such selfish routing through information or payment incentives. However, such mechanism design requires the knowledge of time-varying traffic conditions and it is the users themselves to learn and report past road experiences to the social planner (e.g., Waze or Google Maps). When congestion games meet mobile crowdsourcing, it is critical to incentivize selfish users to explore non-shortest paths in the best exploitation-exploration trade-off. First, we consider a simple but fundamental parallel routing network with one deterministic path and multiple stochastic paths for users with an average arrival probability $\lambda$. We prove that the current myopic routing policy (widely used in Waze and Google Maps) misses both exploration (when strong hazard belief) and exploitation (when weak hazard belief) as compared to the social optimum. Due to the myopic policy's under-exploration, we prove that the caused price of anarchy (PoA) is larger than \(\frac{1}{1-\rho^{\frac{1}{\lambda}}}\), which can be arbitrarily large as discount factor \(\rho\rightarrow1\). To mitigate such huge efficiency loss, we propose a novel selective information disclosure (SID) mechanism: we only reveal the latest traffic information to users when they intend to over-explore stochastic paths upon arrival, while hiding such information when they want to under-explore. We prove that our mechanism successfully reduces PoA to be less than~\(2\). Besides the parallel routing network, we further extend our mechanism and PoA results to any linear path graphs with multiple intermediate nodes.
Scalable Hierarchical Reinforcement Learning for Hyper Scale Multi-Robot Task Planning
Dec 27, 2024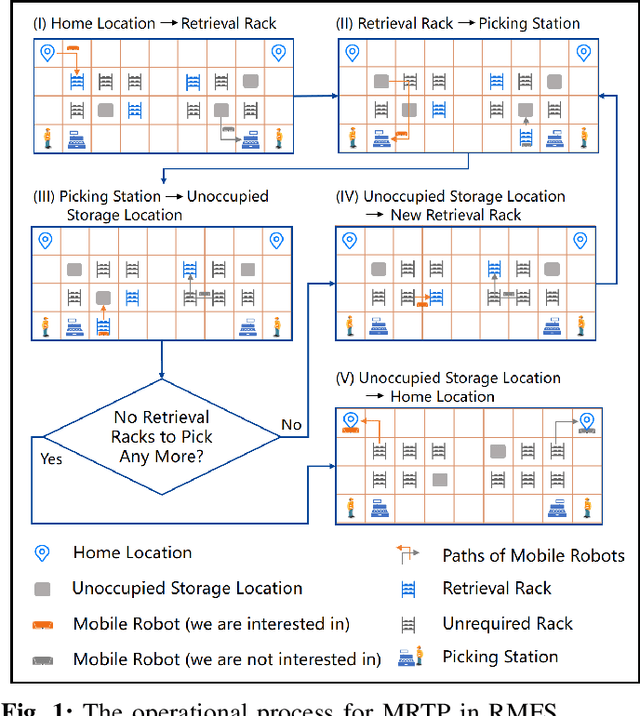
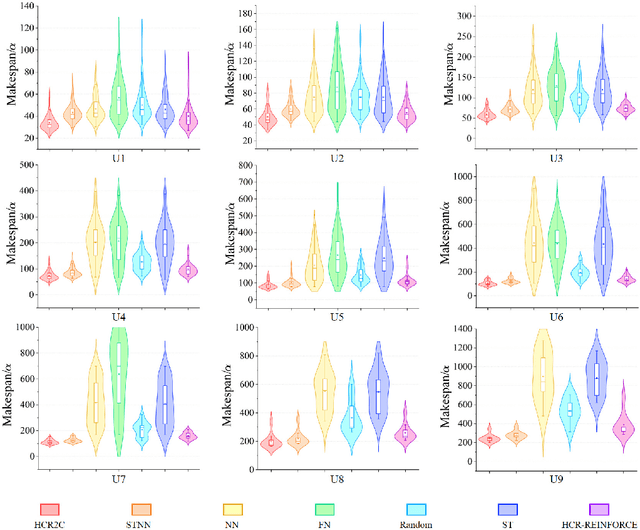
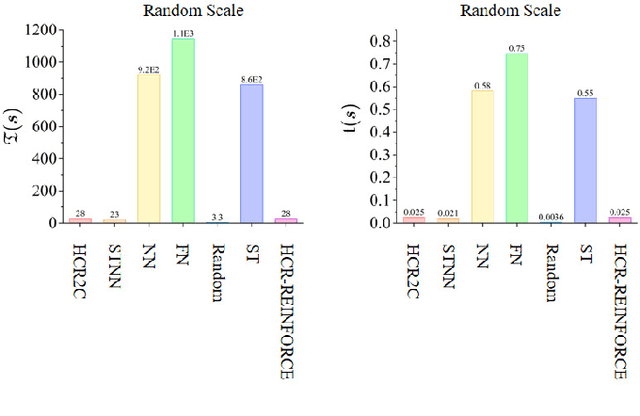

To improve the efficiency of warehousing system and meet huge customer orders, we aim to solve the challenges of dimension disaster and dynamic properties in hyper scale multi-robot task planning (MRTP) for robotic mobile fulfillment system (RMFS). Existing research indicates that hierarchical reinforcement learning (HRL) is an effective method to reduce these challenges. Based on that, we construct an efficient multi-stage HRL-based multi-robot task planner for hyper scale MRTP in RMFS, and the planning process is represented with a special temporal graph topology. To ensure optimality, the planner is designed with a centralized architecture, but it also brings the challenges of scaling up and generalization that require policies to maintain performance for various unlearned scales and maps. To tackle these difficulties, we first construct a hierarchical temporal attention network (HTAN) to ensure basic ability of handling inputs with unfixed lengths, and then design multi-stage curricula for hierarchical policy learning to further improve the scaling up and generalization ability while avoiding catastrophic forgetting. Additionally, we notice that policies with hierarchical structure suffer from unfair credit assignment that is similar to that in multi-agent reinforcement learning, inspired of which, we propose a hierarchical reinforcement learning algorithm with counterfactual rollout baseline to improve learning performance. Experimental results demonstrate that our planner outperform other state-of-the-art methods on various MRTP instances in both simulated and real-world RMFS. Also, our planner can successfully scale up to hyper scale MRTP instances in RMFS with up to 200 robots and 1000 retrieval racks on unlearned maps while keeping superior performance over other methods.
Theory of Mixture-of-Experts for Mobile Edge Computing
Dec 20, 2024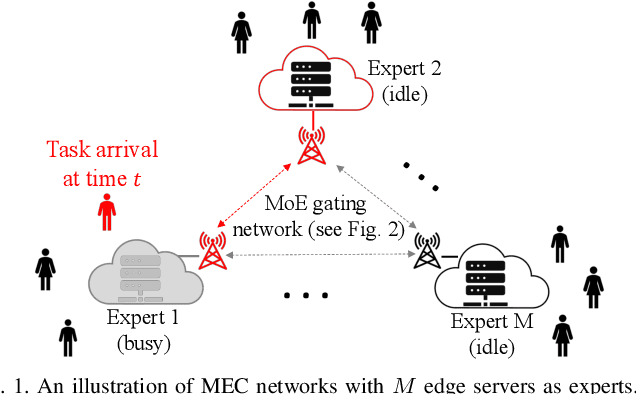
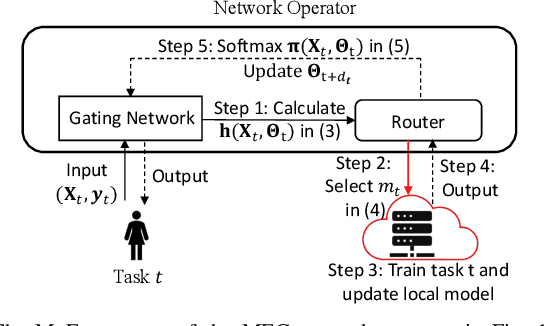
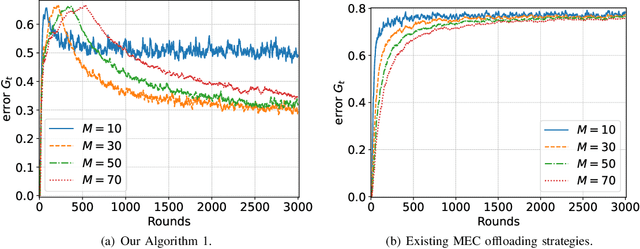
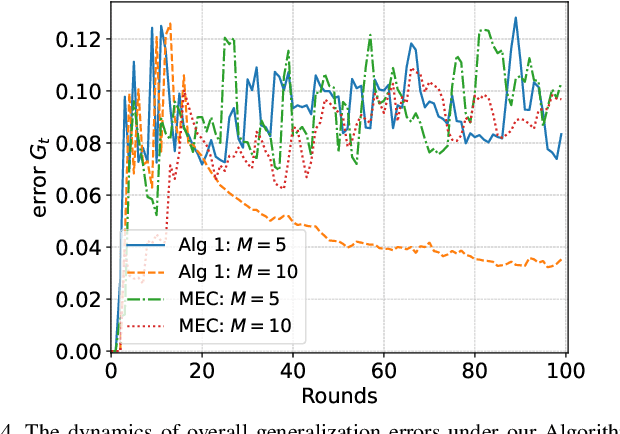
In mobile edge computing (MEC) networks, mobile users generate diverse machine learning tasks dynamically over time. These tasks are typically offloaded to the nearest available edge server, by considering communication and computational efficiency. However, its operation does not ensure that each server specializes in a specific type of tasks and leads to severe overfitting or catastrophic forgetting of previous tasks. To improve the continual learning (CL) performance of online tasks, we are the first to introduce mixture-of-experts (MoE) theory in MEC networks and save MEC operation from the increasing generalization error over time. Our MoE theory treats each MEC server as an expert and dynamically adapts to changes in server availability by considering data transfer and computation time. Unlike existing MoE models designed for offline tasks, ours is tailored for handling continuous streams of tasks in the MEC environment. We introduce an adaptive gating network in MEC to adaptively identify and route newly arrived tasks of unknown data distributions to available experts, enabling each expert to specialize in a specific type of tasks upon convergence. We derived the minimum number of experts required to match each task with a specialized, available expert. Our MoE approach consistently reduces the overall generalization error over time, unlike the traditional MEC approach. Interestingly, when the number of experts is sufficient to ensure convergence, adding more experts delays the convergence time and worsens the generalization error. Finally, we perform extensive experiments on real datasets in deep neural networks (DNNs) to verify our theoretical results.
NASM: Neural Anisotropic Surface Meshing
Oct 30, 2024This paper introduces a new learning-based method, NASM, for anisotropic surface meshing. Our key idea is to propose a graph neural network to embed an input mesh into a high-dimensional (high-d) Euclidean embedding space to preserve curvature-based anisotropic metric by using a dot product loss between high-d edge vectors. This can dramatically reduce the computational time and increase the scalability. Then, we propose a novel feature-sensitive remeshing on the generated high-d embedding to automatically capture sharp geometric features. We define a high-d normal metric, and then derive an automatic differentiation on a high-d centroidal Voronoi tessellation (CVT) optimization with the normal metric to simultaneously preserve geometric features and curvature anisotropy that exhibit in the original 3D shapes. To our knowledge, this is the first time that a deep learning framework and a large dataset are proposed to construct a high-d Euclidean embedding space for 3D anisotropic surface meshing. Experimental results are evaluated and compared with the state-of-the-art in anisotropic surface meshing on a large number of surface models from Thingi10K dataset as well as tested on extensive unseen 3D shapes from Multi-Garment Network dataset and FAUST human dataset.
SCSA: Exploring the Synergistic Effects Between Spatial and Channel Attention
Jul 06, 2024Channel and spatial attentions have respectively brought significant improvements in extracting feature dependencies and spatial structure relations for various downstream vision tasks. While their combination is more beneficial for leveraging their individual strengths, the synergy between channel and spatial attentions has not been fully explored, lacking in fully harness the synergistic potential of multi-semantic information for feature guidance and mitigation of semantic disparities. Our study attempts to reveal the synergistic relationship between spatial and channel attention at multiple semantic levels, proposing a novel Spatial and Channel Synergistic Attention module (SCSA). Our SCSA consists of two parts: the Shareable Multi-Semantic Spatial Attention (SMSA) and the Progressive Channel-wise Self-Attention (PCSA). SMSA integrates multi-semantic information and utilizes a progressive compression strategy to inject discriminative spatial priors into PCSA's channel self-attention, effectively guiding channel recalibration. Additionally, the robust feature interactions based on the self-attention mechanism in PCSA further mitigate the disparities in multi-semantic information among different sub-features within SMSA. We conduct extensive experiments on seven benchmark datasets, including classification on ImageNet-1K, object detection on MSCOCO 2017, segmentation on ADE20K, and four other complex scene detection datasets. Our results demonstrate that our proposed SCSA not only surpasses the current state-of-the-art attention but also exhibits enhanced generalization capabilities across various task scenarios. The code and models are available at: https://github.com/HZAI-ZJNU/SCSA.