 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlier-robust Autocovariance Least Square Estimation via Iteratively Reweighted Least Square
Mar 09, 2026The autocovariance least squares (ALS) method is a computationally efficient approach for estimating noise covariances in Kalman filters without requiring specific noise models. However, conventional ALS and its variants rely on the classic least mean squares (LMS) criterion, making them highly sensitive to measurement outliers and prone to severe performance degradation. To overcome this limitation, this paper proposes a novel outlier-robust ALS algorithm, termed ALS-IRLS, based on the iteratively reweighted least squares (IRLS) framework. Specifically, the proposed approach introduces a two-tier robustification strategy. First, an innovation-level adaptive thresholding mechanism is employed to filter out heavily contaminated data. Second, the outlier-contaminated autocovariance is formulated using an $ε$-contamination model, where the standard LMS criterion is replaced by the Huber cost function. The IRLS method is then utilized to iteratively adjust data weights based on estimation deviations, effectively mitigating the influence of residual outliers. Comparative simulations demonstrate that ALS-IRLS reduces the root-mean-square error (RMSE) of noise covariance estimates by over two orders of magnitude compared to standard ALS. Furthermore, it significantly enhances downstream state estimation accuracy, outperforming existing outlier-robust Kalman filters and achieving performance nearly equivalent to the ideal Oracle lower bound in the presence of noisy and anomalous data.
Two-Way Garment Transfer: Unified Diffusion Framework for Dressing and Undressing Synthesis
Aug 06, 2025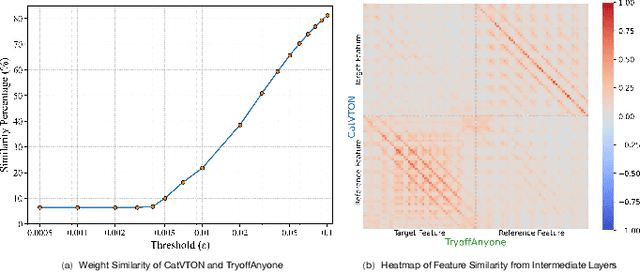
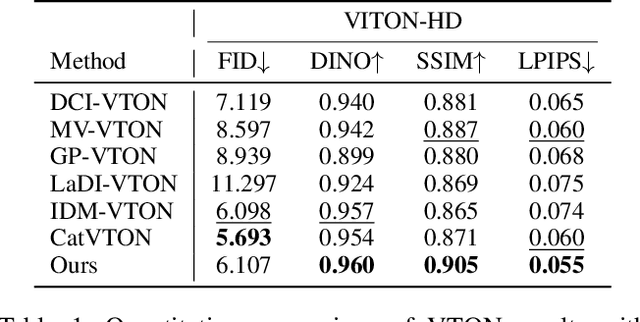
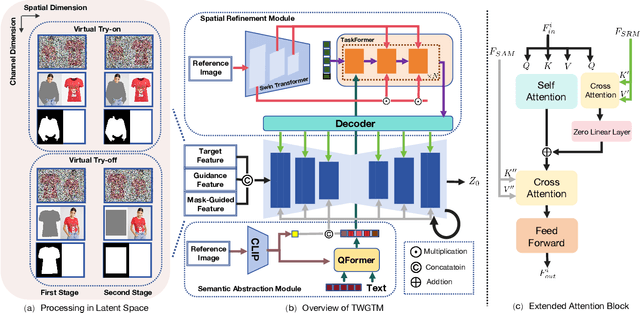

While recent advances in virtual try-on (VTON) have achieved realistic garment transfer to human subjects, its inverse task, virtual try-off (VTOFF), which aims to reconstruct canonical garment templates from dressed humans, remains critically underexplored and lacks systematic investigation. Existing works predominantly treat them as isolated tasks: VTON focuses on garment dressing while VTOFF addresses garment extraction, thereby neglecting their complementary symmetry. To bridge this fundamental gap, we propose the Two-Way Garment Transfer Model (TWGTM), to the best of our knowledge, the first unified framework for joint clothing-centric image synthesis that simultaneously resolves both mask-guided VTON and mask-free VTOFF through bidirectional feature disentanglement. Specifically, our framework employs dual-conditioned guidance from both latent and pixel spaces of reference images to seamlessly bridge the dual tasks. On the other hand, to resolve the inherent mask dependency asymmetry between mask-guided VTON and mask-free VTOFF, we devise a phased training paradigm that progressively bridges this modality gap. Extensive qualitative and quantitative experiments conducted across the DressCode and VITON-HD datasets validate the efficacy and competitive edge of our proposed approach.
In-Context Adaptation to Concept Drift for Learned Database Operations
May 07, 2025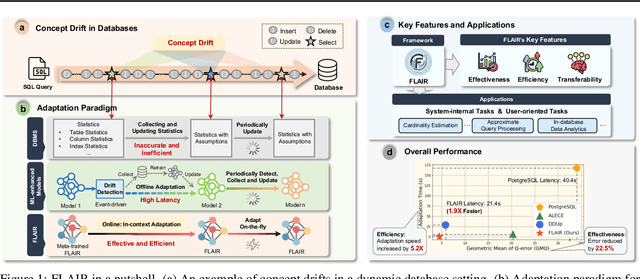
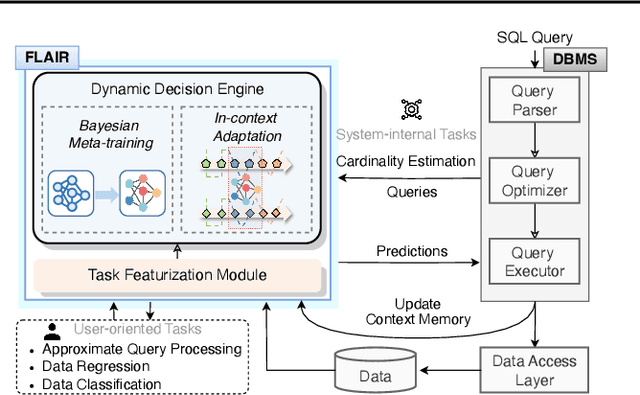
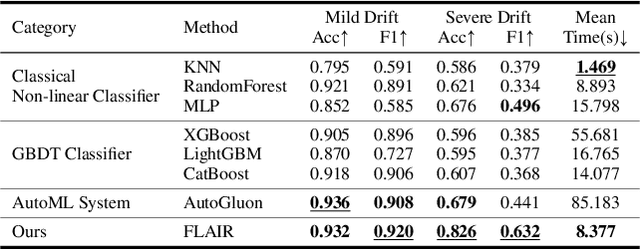
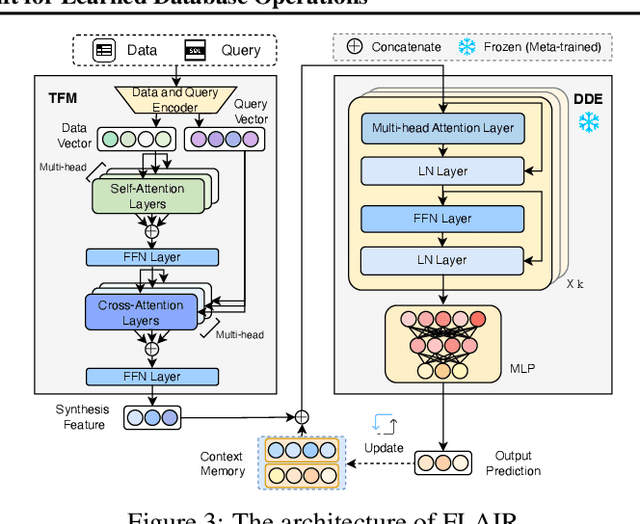
Machine learning has demonstrated transformative potential for database operations, such as query optimization and in-database data analytics. However, dynamic database environments, characterized by frequent updates and evolving data distributions, introduce concept drift, which leads to performance degradation for learned models and limits their practical applicability. Addressing this challenge requires efficient frameworks capable of adapting to shifting concepts while minimizing the overhead of retraining or fine-tuning. In this paper, we propose FLAIR, an online adaptation framework that introduces a new paradigm called \textit{in-context adaptation} for learned database operations. FLAIR leverages the inherent property of data systems, i.e., immediate availability of execution results for predictions, to enable dynamic context construction. By formalizing adaptation as $f:(\mathbf{x} \,| \,\mathcal{C}_t) \to \mathbf{y}$, with $\mathcal{C}_t$ representing a dynamic context memory, FLAIR delivers predictions aligned with the current concept, eliminating the need for runtime parameter optimization. To achieve this, FLAIR integrates two key modules: a Task Featurization Module for encoding task-specific features into standardized representations, and a Dynamic Decision Engine, pre-trained via Bayesian meta-training, to adapt seamlessly using contextual information at runtime. Extensive experiments across key database tasks demonstrate that FLAIR outperforms state-of-the-art baselines, achieving up to 5.2x faster adaptation and reducing error by 22.5% for cardinality estimation.
Optimal Output Feedback Learning Control for Discrete-Time Linear Quadratic Regulation
Mar 08, 2025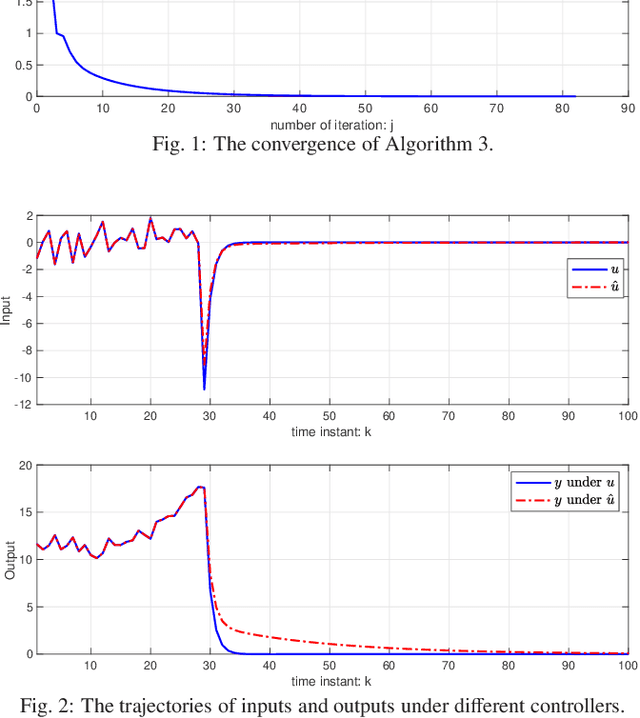
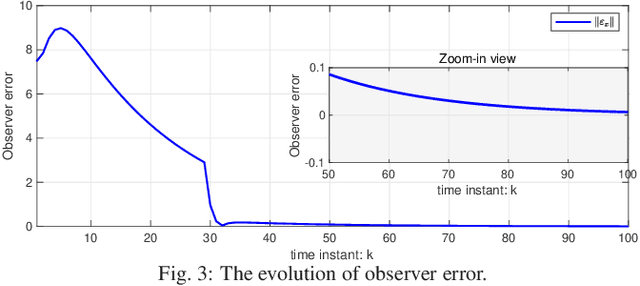
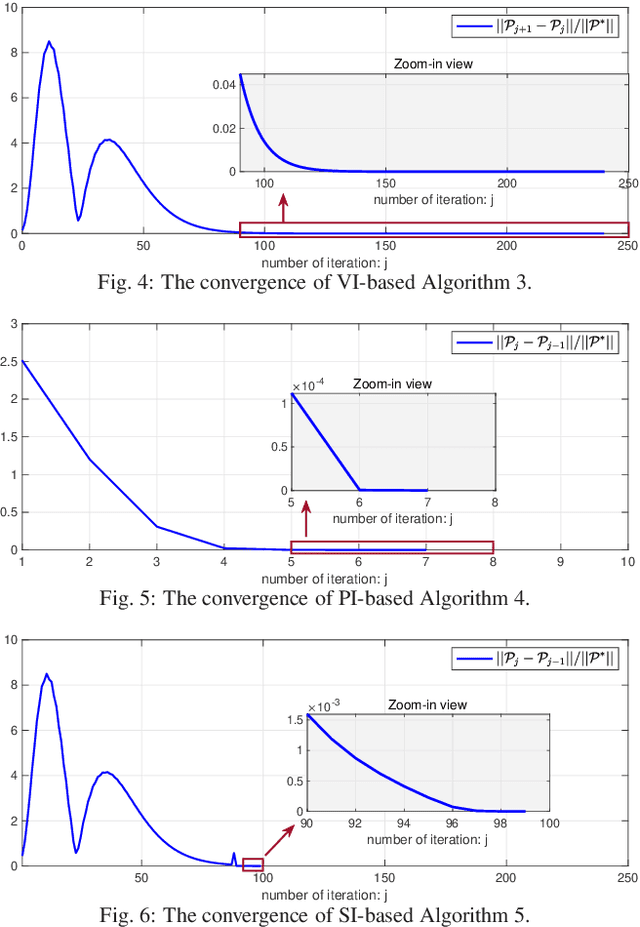
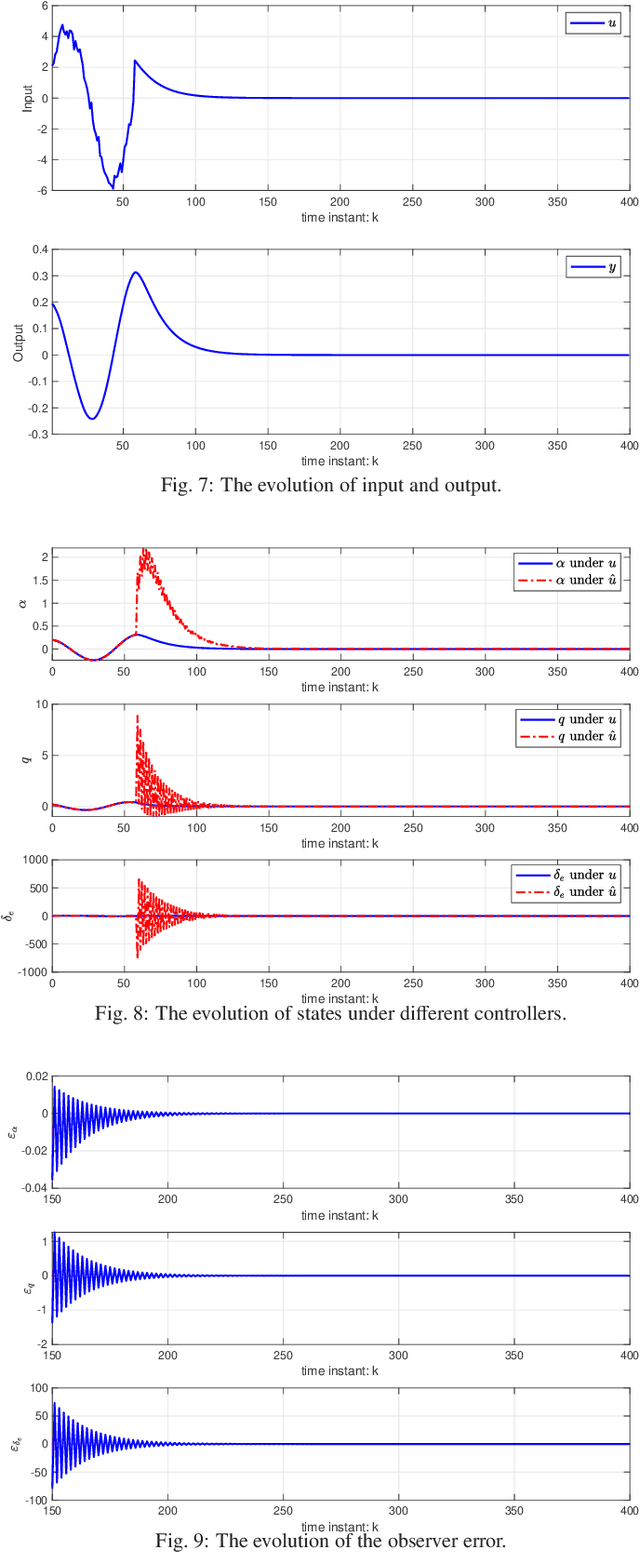
This paper studies the linear quadratic regulation (LQR) problem of unknown discrete-time systems via dynamic output feedback learning control. In contrast to the state feedback, the optimality of the dynamic output feedback control for solving the LQR problem requires an implicit condition on the convergence of the state observer. Moreover, due to unknown system matrices and the existence of observer error, it is difficult to analyze the convergence and stability of most existing output feedback learning-based control methods. To tackle these issues, we propose a generalized dynamic output feedback learning control approach with guaranteed convergence, stability, and optimality performance for solving the LQR problem of unknown discrete-time linear systems. In particular, a dynamic output feedback controller is designed to be equivalent to a state feedback controller. This equivalence relationship is an inherent property without requiring convergence of the estimated state by the state observer, which plays a key role in establishing the off-policy learning control approaches. By value iteration and policy iteration schemes, the adaptive dynamic programming based learning control approaches are developed to estimate the optimal feedback control gain. In addition, a model-free stability criterion is provided by finding a nonsingular parameterization matrix, which contributes to establishing a switched iteration scheme. Furthermore, the convergence, stability, and optimality analyses of the proposed output feedback learning control approaches are given. Finally, the theoretical results are validated by two numerical examples.
Scalable Hierarchical Reinforcement Learning for Hyper Scale Multi-Robot Task Planning
Dec 27, 2024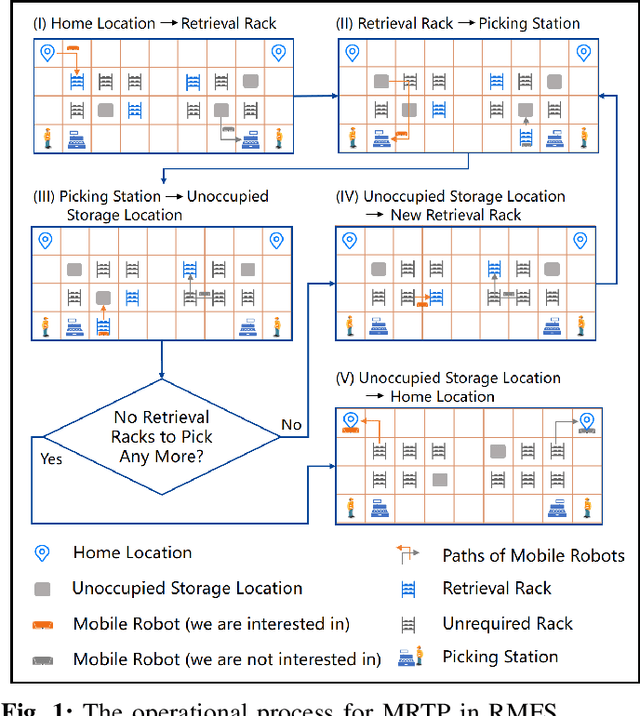
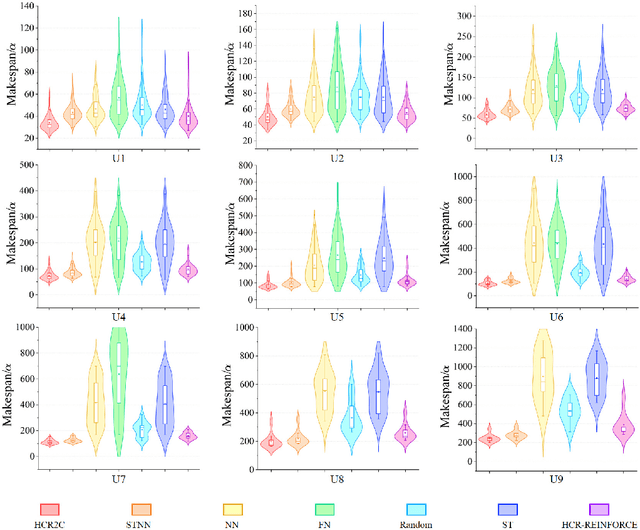
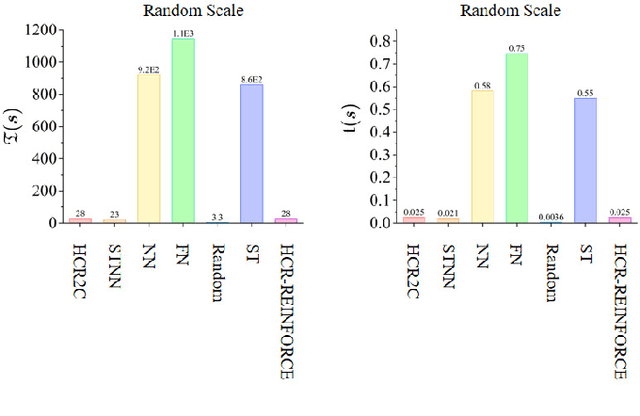

To improve the efficiency of warehousing system and meet huge customer orders, we aim to solve the challenges of dimension disaster and dynamic properties in hyper scale multi-robot task planning (MRTP) for robotic mobile fulfillment system (RMFS). Existing research indicates that hierarchical reinforcement learning (HRL) is an effective method to reduce these challenges. Based on that, we construct an efficient multi-stage HRL-based multi-robot task planner for hyper scale MRTP in RMFS, and the planning process is represented with a special temporal graph topology. To ensure optimality, the planner is designed with a centralized architecture, but it also brings the challenges of scaling up and generalization that require policies to maintain performance for various unlearned scales and maps. To tackle these difficulties, we first construct a hierarchical temporal attention network (HTAN) to ensure basic ability of handling inputs with unfixed lengths, and then design multi-stage curricula for hierarchical policy learning to further improve the scaling up and generalization ability while avoiding catastrophic forgetting. Additionally, we notice that policies with hierarchical structure suffer from unfair credit assignment that is similar to that in multi-agent reinforcement learning, inspired of which, we propose a hierarchical reinforcement learning algorithm with counterfactual rollout baseline to improve learning performance. Experimental results demonstrate that our planner outperform other state-of-the-art methods on various MRTP instances in both simulated and real-world RMFS. Also, our planner can successfully scale up to hyper scale MRTP instances in RMFS with up to 200 robots and 1000 retrieval racks on unlearned maps while keeping superior performance over other methods.
Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection
Apr 15, 2024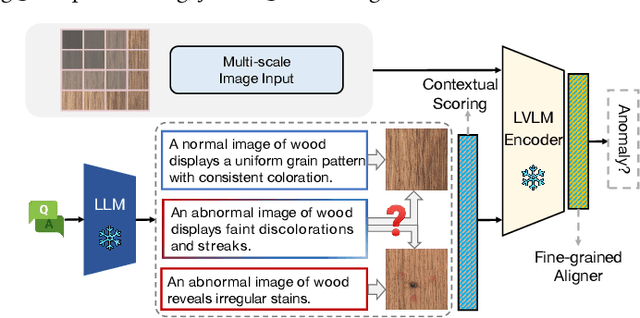
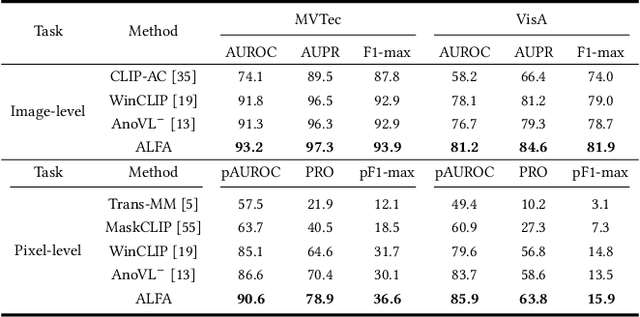
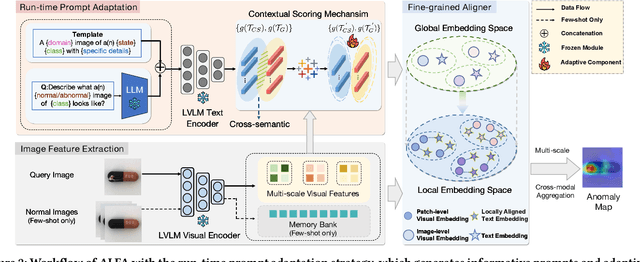
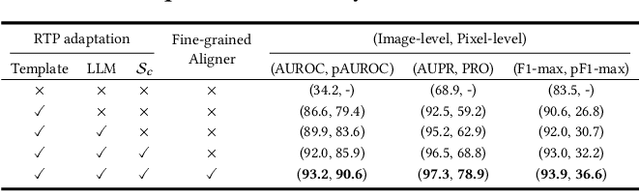
Large vision-language models (LVLMs) are markedly proficient in deriving visual representations guided by natural language. Recent explorations have utilized LVLMs to tackle zero-shot visual anomaly detection (VAD) challenges by pairing images with textual descriptions indicative of normal and abnormal conditions, referred to as anomaly prompts. However, existing approaches depend on static anomaly prompts that are prone to cross-semantic ambiguity, and prioritize global image-level representations over crucial local pixel-level image-to-text alignment that is necessary for accurate anomaly localization. In this paper, we present ALFA, a training-free approach designed to address these challenges via a unified model. We propose a run-time prompt adaptation strategy, which first generates informative anomaly prompts to leverage the capabilities of a large language model (LLM). This strategy is enhanced by a contextual scoring mechanism for per-image anomaly prompt adaptation and cross-semantic ambiguity mitigation. We further introduce a novel fine-grained aligner to fuse local pixel-level semantics for precise anomaly localization, by projecting the image-text alignment from global to local semantic spaces. Extensive evaluations on the challenging MVTec and VisA datasets confirm ALFA's effectiveness in harnessing the language potential for zero-shot VAD, achieving significant PRO improvements of 12.1% on MVTec AD and 8.9% on VisA compared to state-of-the-art zero-shot VAD approaches.
METER: A Dynamic Concept Adaptation Framework for Online Anomaly Detection
Dec 28, 2023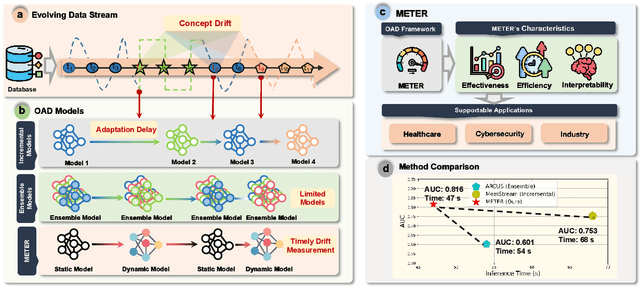
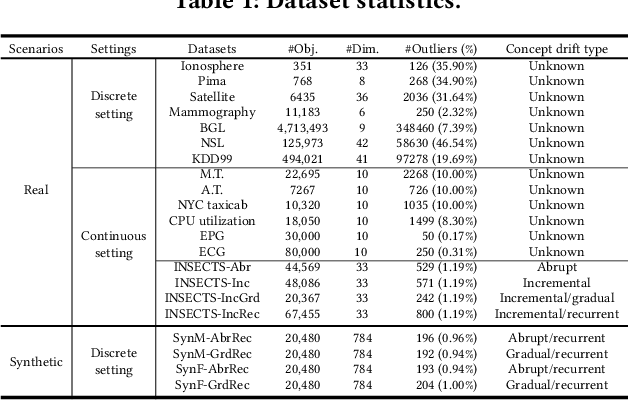
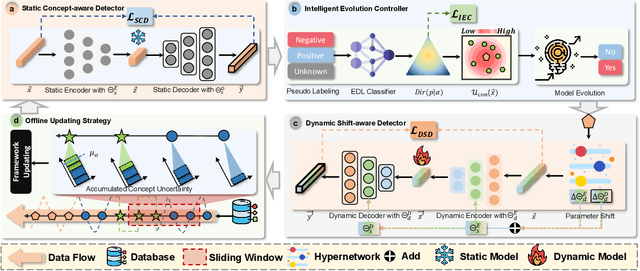
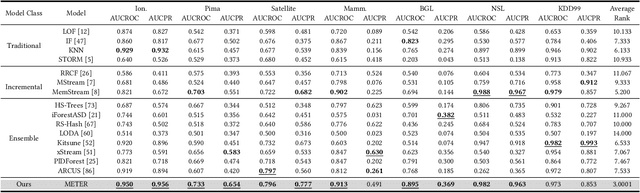
Real-time analytics and decision-making require online anomaly detection (OAD) to handle drifts in data streams efficiently and effectively. Unfortunately, existing approaches are often constrained by their limited detection capacity and slow adaptation to evolving data streams, inhibiting their efficacy and efficiency in handling concept drift, which is a major challenge in evolving data streams. In this paper, we introduce METER, a novel dynamic concept adaptation framework that introduces a new paradigm for OAD. METER addresses concept drift by first training a base detection model on historical data to capture recurring central concepts, and then learning to dynamically adapt to new concepts in data streams upon detecting concept drift. Particularly, METER employs a novel dynamic concept adaptation technique that leverages a hypernetwork to dynamically generate the parameter shift of the base detection model, providing a more effective and efficient solution than conventional retraining or fine-tuning approaches. Further, METER incorporates a lightweight drift detection controller, underpinned by evidential deep learning, to support robust and interpretable concept drift detection. We conduct an extensive experimental evaluation, and the results show that METER significantly outperforms existing OAD approaches in various application scenarios.
Flexible Job Shop Scheduling via Dual Attention Network Based Reinforcement Learning
May 09, 2023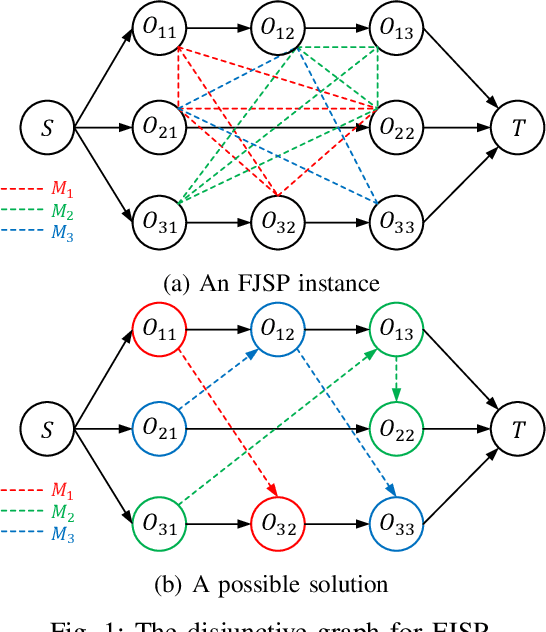
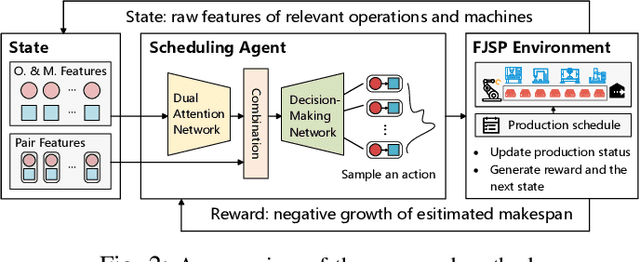
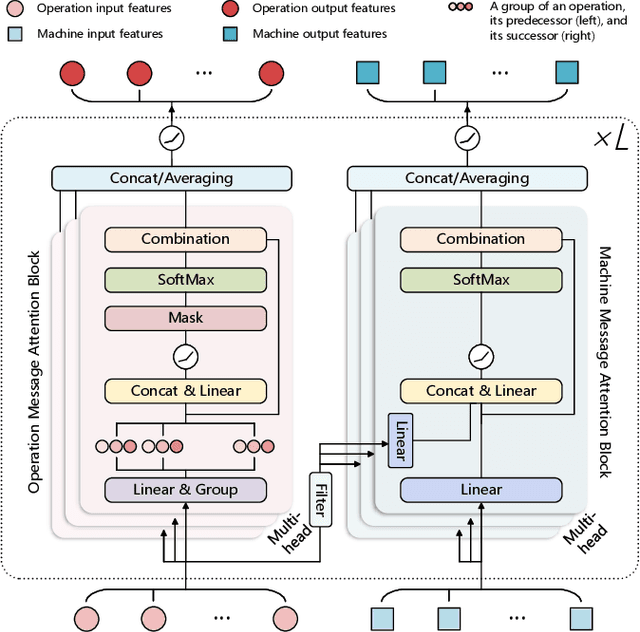
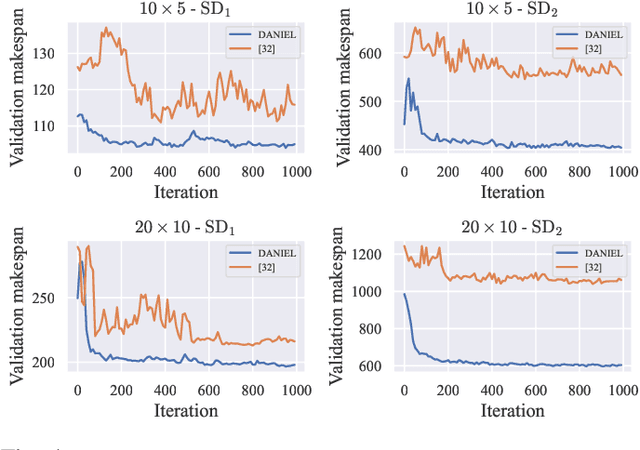
Flexible manufacturing has given rise to complex scheduling problems such as the flexible job shop scheduling problem (FJSP). In FJSP, operations can be processed on multiple machines, leading to intricate relationships between operations and machines. Recent works have employed deep reinforcement learning (DRL) to learn priority dispatching rules (PDRs) for solving FJSP. However, the quality of solutions still has room for improvement relative to that by the exact methods such as OR-Tools. To address this issue, this paper presents a novel end-to-end learning framework that weds the merits of self-attention models for deep feature extraction and DRL for scalable decision-making. The complex relationships between operations and machines are represented precisely and concisely, for which a dual-attention network (DAN) comprising several interconnected operation message attention blocks and machine message attention blocks is proposed. The DAN exploits the complicated relationships to construct production-adaptive operation and machine features to support high-quality decisionmaking. Experimental results using synthetic data as well as public benchmarks corroborate that the proposed approach outperforms both traditional PDRs and the state-of-the-art DRL method. Moreover, it achieves results comparable to exact methods in certain cases and demonstrates favorable generalization ability to large-scale and real-world unseen FJSP tasks.
End-to-End Code-Switching ASR for Low-Resourced Language Pairs
Sep 30, 2019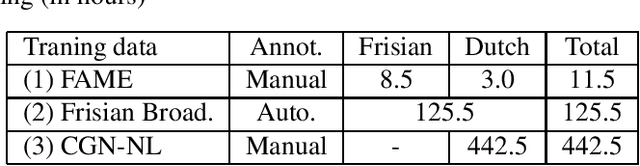
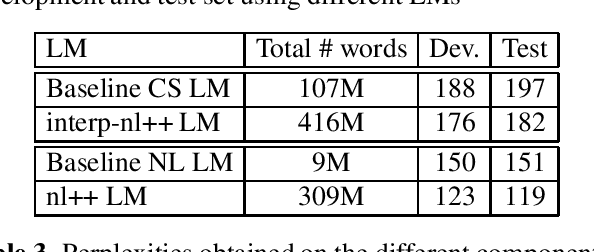
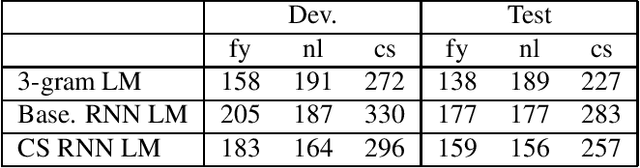
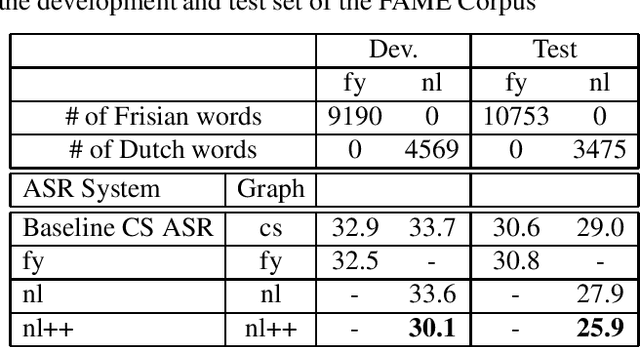
Despite the significant progress in end-to-end (E2E) automatic speech recognition (ASR), E2E ASR for low resourced code-switching (CS) speech has not been well studied. In this work, we describe an E2E ASR pipeline for the recognition of CS speech in which a low-resourced language is mixed with a high resourced language. Low-resourcedness in acoustic data hinders the performance of E2E ASR systems more severely than the conventional ASR systems.~To mitigate this problem in the transcription of archives with code-switching Frisian-Dutch speech, we integrate a designated decoding scheme and perform rescoring with neural network-based language models to enable better utilization of the available textual resources. We first incorporate a multi-graph decoding approach which creates parallel search spaces for each monolingual and mixed recognition tasks to maximize the utilization of the textual resources from each language. Further, language model rescoring is performed using a recurrent neural network pre-trained with cross-lingual embedding and further adapted with the limited amount of in-domain CS text. The ASR experiments demonstrate the effectiveness of the described techniques in improving the recognition performance of an E2E CS ASR system in a low-resourced scenario.