 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Orchestration of AI x DB Workloads
Mar 04, 2026AI-driven analytics are increasingly crucial to data-centric decision-making. The practice of exporting data to machine learning runtimes incurs high overhead, limits robustness to data drift, and expands the attack surface, especially in multi-tenant, heterogeneous data systems. Integrating AI directly into database engines, while offering clear benefits, introduces challenges in managing joint query processing and model execution, optimizing end-to-end performance, coordinating execution under resource contention, and enforcing strong security and access-control guarantees. This paper discusses the challenges of joint DB-AI, or AIxDB, data management and query processing within AI-powered data systems. It presents various challenges that need to be addressed carefully, such as query optimization, execution scheduling, and distributed execution over heterogeneous hardware. Database components such as transaction management and access control need to be re-examined to support AI lifecycle management, mitigate data drift, and protect sensitive data from unauthorized AI operations. We present a design and preliminary results to demonstrate what may be key to the performance for serving AIxDB queries.
OmniCT: Towards a Unified Slice-Volume LVLM for Comprehensive CT Analysis
Feb 18, 2026Computed Tomography (CT) is one of the most widely used and diagnostically information-dense imaging modalities, covering critical organs such as the heart, lungs, liver, and colon. Clinical interpretation relies on both slice-driven local features (e.g., sub-centimeter nodules, lesion boundaries) and volume-driven spatial representations (e.g., tumor infiltration, inter-organ anatomical relations). However, existing Large Vision-Language Models (LVLMs) remain fragmented in CT slice versus volumetric understanding: slice-driven LVLMs show strong generalization but lack cross-slice spatial consistency, while volume-driven LVLMs explicitly capture volumetric semantics but suffer from coarse granularity and poor compatibility with slice inputs. The absence of a unified modeling paradigm constitutes a major bottleneck for the clinical translation of medical LVLMs. We present OmniCT, a powerful unified slice-volume LVLM for CT scenarios, which makes three contributions: (i) Spatial Consistency Enhancement (SCE): volumetric slice composition combined with tri-axial positional embedding that introduces volumetric consistency, and an MoE hybrid projection enables efficient slice-volume adaptation; (ii) Organ-level Semantic Enhancement (OSE): segmentation and ROI localization explicitly align anatomical regions, emphasizing lesion- and organ-level semantics; (iii) MedEval-CT: the largest slice-volume CT dataset and hybrid benchmark integrates comprehensive metrics for unified evaluation. OmniCT consistently outperforms existing methods with a substantial margin across diverse clinical tasks and satisfies both micro-level detail sensitivity and macro-level spatial reasoning. More importantly, it establishes a new paradigm for cross-modal medical imaging understanding.
CtrlCoT: Dual-Granularity Chain-of-Thought Compression for Controllable Reasoning
Jan 28, 2026Chain-of-thought (CoT) prompting improves LLM reasoning but incurs high latency and memory cost due to verbose traces, motivating CoT compression with preserved correctness. Existing methods either shorten CoTs at the semantic level, which is often conservative, or prune tokens aggressively, which can miss task-critical cues and degrade accuracy. Moreover, combining the two is non-trivial due to sequential dependency, task-agnostic pruning, and distribution mismatch. We propose \textbf{CtrlCoT}, a dual-granularity CoT compression framework that harmonizes semantic abstraction and token-level pruning through three components: Hierarchical Reasoning Abstraction produces CoTs at multiple semantic granularities; Logic-Preserving Distillation trains a logic-aware pruner to retain indispensable reasoning cues (e.g., numbers and operators) across pruning ratios; and Distribution-Alignment Generation aligns compressed traces with fluent inference-time reasoning styles to avoid fragmentation. On MATH-500 with Qwen2.5-7B-Instruct, CtrlCoT uses 30.7\% fewer tokens while achieving 7.6 percentage points higher than the strongest baseline, demonstrating more efficient and reliable reasoning. Our code will be publicly available at https://github.com/fanzhenxuan/Ctrl-CoT.
CLEAR-Mamba:Towards Accurate, Adaptive and Trustworthy Multi-Sequence Ophthalmic Angiography Classification
Jan 28, 2026Medical image classification is a core task in computer-aided diagnosis (CAD), playing a pivotal role in early disease detection, treatment planning, and patient prognosis assessment. In ophthalmic practice, fluorescein fundus angiography (FFA) and indocyanine green angiography (ICGA) provide hemodynamic and lesion-structural information that conventional fundus photography cannot capture. However, due to the single-modality nature, subtle lesion patterns, and significant inter-device variability, existing methods still face limitations in generalization and high-confidence prediction. To address these challenges, we propose CLEAR-Mamba, an enhanced framework built upon MedMamba with optimizations in both architecture and training strategy. Architecturally, we introduce HaC, a hypernetwork-based adaptive conditioning layer that dynamically generates parameters according to input feature distributions, thereby improving cross-domain adaptability. From a training perspective, we develop RaP, a reliability-aware prediction scheme built upon evidential uncertainty learning, which encourages the model to emphasize low-confidence samples and improves overall stability and reliability. We further construct a large-scale ophthalmic angiography dataset covering both FFA and ICGA modalities, comprising multiple retinal disease categories for model training and evaluation. Experimental results demonstrate that CLEAR-Mamba consistently outperforms multiple baseline models, including the original MedMamba, across various metrics-showing particular advantages in multi-disease classification and reliability-aware prediction. This study provides an effective solution that balances generalizability and reliability for modality-specific medical image classification tasks.
Toward Robust Signed Graph Learning through Joint Input-Target Denoising
Oct 26, 2025Signed Graph Neural Networks (SGNNs) are widely adopted to analyze complex patterns in signed graphs with both positive and negative links. Given the noisy nature of real-world connections, the robustness of SGNN has also emerged as a pivotal research area. Under the supervision of empirical properties, graph structure learning has shown its robustness on signed graph representation learning, however, there remains a paucity of research investigating a robust SGNN with theoretical guidance. Inspired by the success of graph information bottleneck (GIB) in information extraction, we propose RIDGE, a novel framework for Robust sI gned graph learning through joint Denoising of Graph inputs and supervision targEts. Different from the basic GIB, we extend the GIB theory with the capability of target space denoising as the co-existence of noise in both input and target spaces. In instantiation, RIDGE effectively cleanses input data and supervision targets via a tractable objective function produced by reparameterization mechanism and variational approximation. We extensively validate our method on four prevalent signed graph datasets, and the results show that RIDGE clearly improves the robustness of popular SGNN models under various levels of noise.
Heartcare Suite: Multi-dimensional Understanding of ECG with Raw Multi-lead Signal Modeling
Jun 06, 2025We present Heartcare Suite, a multimodal comprehensive framework for finegrained electrocardiogram (ECG) understanding. It comprises three key components: (i) Heartcare-220K, a high-quality, structured, and comprehensive multimodal ECG dataset covering essential tasks such as disease diagnosis, waveform morphology analysis, and rhythm interpretation. (ii) Heartcare-Bench, a systematic and multi-dimensional benchmark designed to evaluate diagnostic intelligence and guide the optimization of Medical Multimodal Large Language Models (Med-MLLMs) in ECG scenarios. and (iii) HeartcareGPT with a tailored tokenizer Bidirectional ECG Abstract Tokenization (Beat), which compresses raw multi-lead signals into semantically rich discrete tokens via duallevel vector quantization and query-guided bidirectional diffusion mechanism. Built upon Heartcare-220K, HeartcareGPT achieves strong generalization and SoTA performance across multiple clinically meaningful tasks. Extensive experiments demonstrate that Heartcare Suite is highly effective in advancing ECGspecific multimodal understanding and evaluation. Our project is available at https://github.com/Wznnnnn/Heartcare-Suite .
HAKES: Scalable Vector Database for Embedding Search Service
May 18, 2025Modern deep learning models capture the semantics of complex data by transforming them into high-dimensional embedding vectors. Emerging applications, such as retrieval-augmented generation, use approximate nearest neighbor (ANN) search in the embedding vector space to find similar data. Existing vector databases provide indexes for efficient ANN searches, with graph-based indexes being the most popular due to their low latency and high recall in real-world high-dimensional datasets. However, these indexes are costly to build, suffer from significant contention under concurrent read-write workloads, and scale poorly to multiple servers. Our goal is to build a vector database that achieves high throughput and high recall under concurrent read-write workloads. To this end, we first propose an ANN index with an explicit two-stage design combining a fast filter stage with highly compressed vectors and a refine stage to ensure recall, and we devise a novel lightweight machine learning technique to fine-tune the index parameters. We introduce an early termination check to dynamically adapt the search process for each query. Next, we add support for writes while maintaining search performance by decoupling the management of the learned parameters. Finally, we design HAKES, a distributed vector database that serves the new index in a disaggregated architecture. We evaluate our index and system against 12 state-of-the-art indexes and three distributed vector databases, using high-dimensional embedding datasets generated by deep learning models. The experimental results show that our index outperforms index baselines in the high recall region and under concurrent read-write workloads. Furthermore, \namesys{} is scalable and achieves up to $16\times$ higher throughputs than the baselines. The HAKES project is open-sourced at https://www.comp.nus.edu.sg/~dbsystem/hakes/.
In-Context Adaptation to Concept Drift for Learned Database Operations
May 07, 2025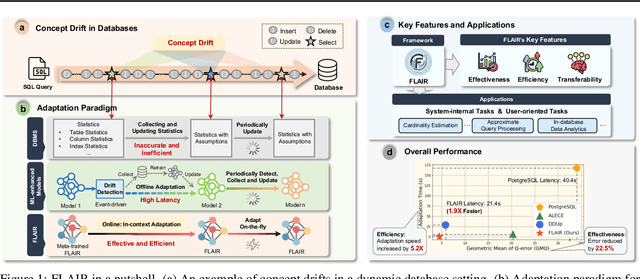
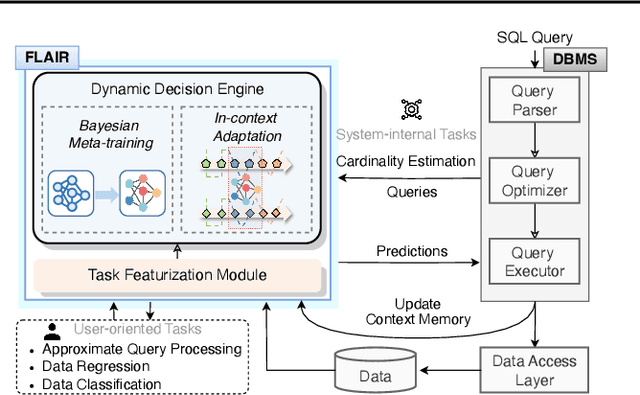
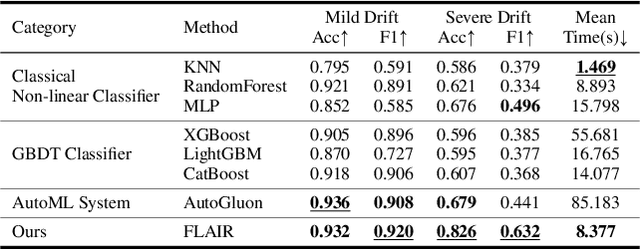
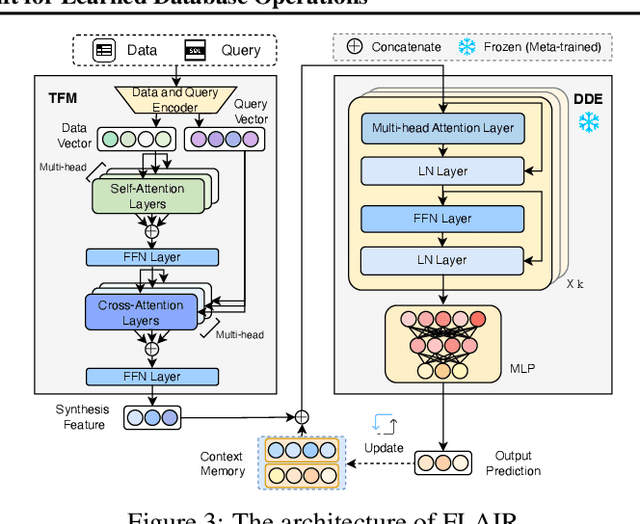
Machine learning has demonstrated transformative potential for database operations, such as query optimization and in-database data analytics. However, dynamic database environments, characterized by frequent updates and evolving data distributions, introduce concept drift, which leads to performance degradation for learned models and limits their practical applicability. Addressing this challenge requires efficient frameworks capable of adapting to shifting concepts while minimizing the overhead of retraining or fine-tuning. In this paper, we propose FLAIR, an online adaptation framework that introduces a new paradigm called \textit{in-context adaptation} for learned database operations. FLAIR leverages the inherent property of data systems, i.e., immediate availability of execution results for predictions, to enable dynamic context construction. By formalizing adaptation as $f:(\mathbf{x} \,| \,\mathcal{C}_t) \to \mathbf{y}$, with $\mathcal{C}_t$ representing a dynamic context memory, FLAIR delivers predictions aligned with the current concept, eliminating the need for runtime parameter optimization. To achieve this, FLAIR integrates two key modules: a Task Featurization Module for encoding task-specific features into standardized representations, and a Dynamic Decision Engine, pre-trained via Bayesian meta-training, to adapt seamlessly using contextual information at runtime. Extensive experiments across key database tasks demonstrate that FLAIR outperforms state-of-the-art baselines, achieving up to 5.2x faster adaptation and reducing error by 22.5% for cardinality estimation.
EyecareGPT: Boosting Comprehensive Ophthalmology Understanding with Tailored Dataset, Benchmark and Model
Apr 18, 2025Medical Large Vision-Language Models (Med-LVLMs) demonstrate significant potential in healthcare, but their reliance on general medical data and coarse-grained global visual understanding limits them in intelligent ophthalmic diagnosis. Currently, intelligent ophthalmic diagnosis faces three major challenges: (i) Data. The lack of deeply annotated, high-quality, multi-modal ophthalmic visual instruction data; (ii) Benchmark. The absence of a comprehensive and systematic benchmark for evaluating diagnostic performance; (iii) Model. The difficulty of adapting holistic visual architectures to fine-grained, region-specific ophthalmic lesion identification. In this paper, we propose the Eyecare Kit, which systematically tackles the aforementioned three key challenges with the tailored dataset, benchmark and model: First, we construct a multi-agent data engine with real-life ophthalmology data to produce Eyecare-100K, a high-quality ophthalmic visual instruction dataset. Subsequently, we design Eyecare-Bench, a benchmark that comprehensively evaluates the overall performance of LVLMs on intelligent ophthalmic diagnosis tasks across multiple dimensions. Finally, we develop the EyecareGPT, optimized for fine-grained ophthalmic visual understanding thoroughly, which incorporates an adaptive resolution mechanism and a layer-wise dense connector. Extensive experimental results indicate that the EyecareGPT achieves state-of-the-art performance in a range of ophthalmic tasks, underscoring its significant potential for the advancement of open research in intelligent ophthalmic diagnosis. Our project is available at https://github.com/DCDmllm/EyecareGPT.
Distribution-aware Online Continual Learning for Urban Spatio-Temporal Forecasting
Nov 24, 2024



Urban spatio-temporal (ST) forecasting is crucial for various urban applications such as intelligent scheduling and trip planning. Previous studies focus on modeling ST correlations among urban locations in offline settings, which often neglect the non-stationary nature of urban ST data, particularly, distribution shifts over time. This oversight can lead to degraded performance in real-world scenarios. In this paper, we first analyze the distribution shifts in urban ST data, and then introduce DOST, a novel online continual learning framework tailored for ST data characteristics. DOST employs an adaptive ST network equipped with a variable-independent adapter to address the unique distribution shifts at each urban location dynamically. Further, to accommodate the gradual nature of these shifts, we also develop an awake-hibernate learning strategy that intermittently fine-tunes the adapter during the online phase to reduce computational overhead. This strategy integrates a streaming memory update mechanism designed for urban ST sequential data, enabling effective network adaptation to new patterns while preventing catastrophic forgetting. Experimental results confirm DOST's superiority over state-of-the-art models on four real-world datasets, providing online forecasts within an average of 0.1 seconds and achieving a 12.89% reduction in forecast errors compared to baseline models.