 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurDB: On the Design and Implementation of an AI-powered Autonomous Database
Aug 06, 2024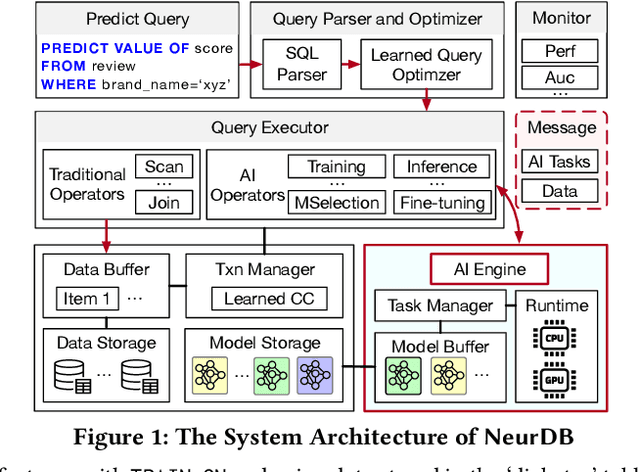
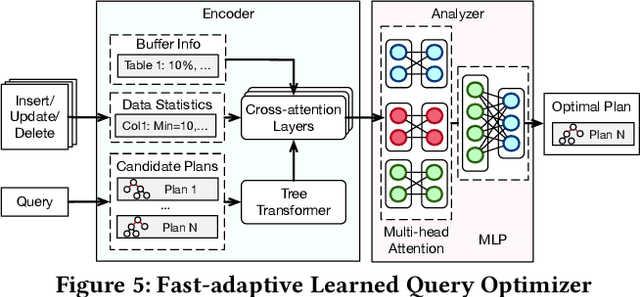
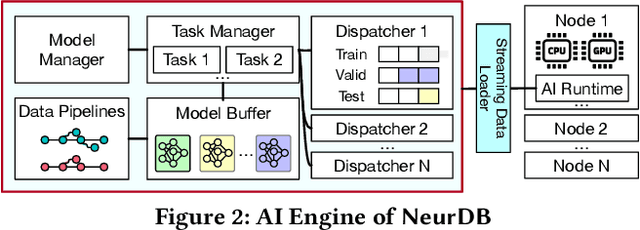
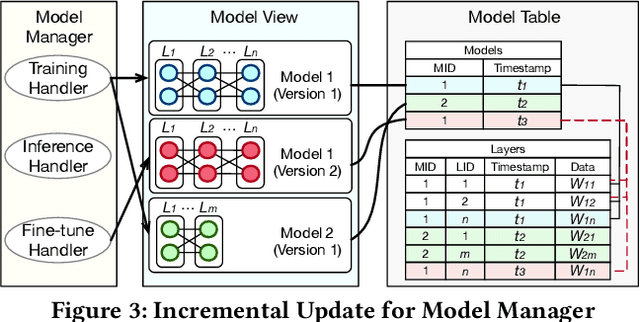
Databases are increasingly embracing AI to provide autonomous system optimization and intelligent in-database analytics, aiming to relieve end-user burdens across various industry sectors. Nonetheless, most existing approaches fail to account for the dynamic nature of databases, which renders them ineffective for real-world applications characterized by evolving data and workloads. This paper introduces NeurDB, an AI-powered autonomous database that deepens the fusion of AI and databases with adaptability to data and workload drift. NeurDB establishes a new in-database AI ecosystem that seamlessly integrates AI workflows within the database. This integration enables efficient and effective in-database AI analytics and fast-adaptive learned system components. Empirical evaluations demonstrate that NeurDB substantially outperforms existing solutions in managing AI analytics tasks, with the proposed learned components more effectively handling environmental dynamism than state-of-the-art approaches.
FLAC: A Robust Failure-Aware Atomic Commit Protocol for Distributed Transactions
Mar 02, 2023



In distributed transaction processing, atomic commit protocol (ACP) is used to ensure database consistency. With the use of commodity compute nodes and networks, failures such as system crashes and network partitioning are common. It is therefore important for ACP to dynamically adapt to the operating condition for efficiency while ensuring the consistency of the database. Existing ACPs often assume stable operating conditions, hence, they are either non-generalizable to different environments or slow in practice. In this paper, we propose a novel and practical ACP, called Failure-Aware Atomic Commit (FLAC). In essence, FLAC includes three protocols, which are specifically designed for three different environments: (i) no failure occurs, (ii) participant nodes might crash but there is no delayed connection, or (iii) both crashed nodes and delayed connection can occur. It models these environments as the failure-free, crash-failure, and network-failure robustness levels. During its operation, FLAC can monitor if any failure occurs and dynamically switch to operate the most suitable protocol, using a robustness level state machine, whose parameters are fine-tuned by reinforcement learning. Consequently, it improves both the response time and throughput, and effectively handles nodes distributed across the Internet where crash and network failures might occur. We implement FLAC in a distributed transactional key-value storage system based on Google Percolator and evaluate its performance with both a micro benchmark and a macro benchmark of real workload. The results show that FLAC achieves up to 2.22x throughput improvement and 2.82x latency speedup, compared to existing ACPs for high-contention workloads.