 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mixture of Experts Vision Transformer for High-Fidelity Surface Code Decoding
Jan 18, 2026Quantum error correction is a key ingredient for large scale quantum computation, protecting logical information from physical noise by encoding it into many physical qubits. Topological stabilizer codes are particularly appealing due to their geometric locality and practical relevance. In these codes, stabilizer measurements yield a syndrome that must be decoded into a recovery operation, making decoding a central bottleneck for scalable real time operation. Existing decoders are commonly classified into two categories. Classical algorithmic decoders provide strong and well established baselines, but may incur substantial computational overhead at large code distances or under stringent latency constraints. Machine learning based decoders offer fast GPU inference and flexible function approximation, yet many approaches do not explicitly exploit the lattice geometry and local structure of topological codes, which can limit performance. In this work, we propose QuantumSMoE, a quantum vision transformer based decoder that incorporates code structure through plus shaped embeddings and adaptive masking to capture local interactions and lattice connectivity, and improves scalability via a mixture of experts layer with a novel auxiliary loss. Experiments on the toric code demonstrate that QuantumSMoE outperforms state-of-the-art machine learning decoders as well as widely used classical baselines.
Optimal Multi-Objective Best Arm Identification with Fixed Confidence
Jan 23, 2025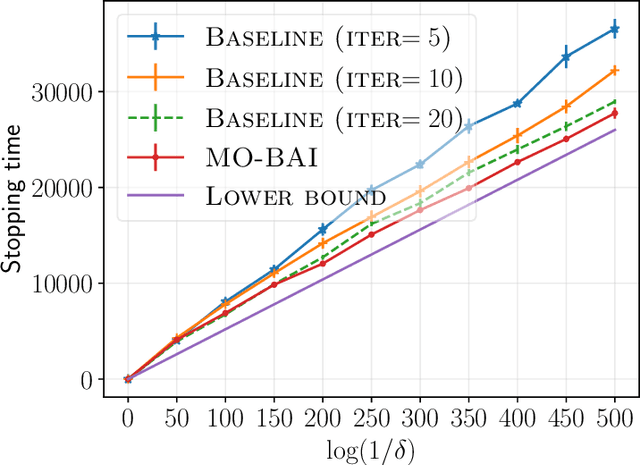

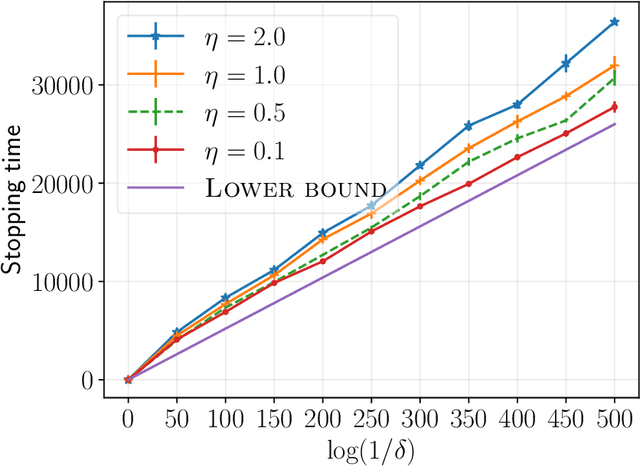

We consider a multi-armed bandit setting with finitely many arms, in which each arm yields an $M$-dimensional vector reward upon selection. We assume that the reward of each dimension (a.k.a. {\em objective}) is generated independently of the others. The best arm of any given objective is the arm with the largest component of mean corresponding to the objective. The end goal is to identify the best arm of {\em every} objective in the shortest (expected) time subject to an upper bound on the probability of error (i.e., fixed-confidence regime). We establish a problem-dependent lower bound on the limiting growth rate of the expected stopping time, in the limit of vanishing error probabilities. This lower bound, we show, is characterised by a max-min optimisation problem that is computationally expensive to solve at each time step. We propose an algorithm that uses the novel idea of {\em surrogate proportions} to sample the arms at each time step, eliminating the need to solve the max-min optimisation problem at each step. We demonstrate theoretically that our algorithm is asymptotically optimal. In addition, we provide extensive empirical studies to substantiate the efficiency of our algorithm. While existing works on pure exploration with multi-objective multi-armed bandits predominantly focus on {\em Pareto frontier identification}, our work fills the gap in the literature by conducting a formal investigation of the multi-objective best arm identification problem.
Fixed-Budget Differentially Private Best Arm Identification
Jan 17, 2024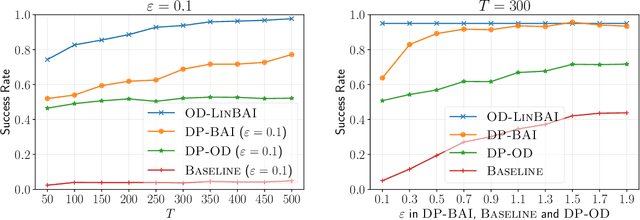

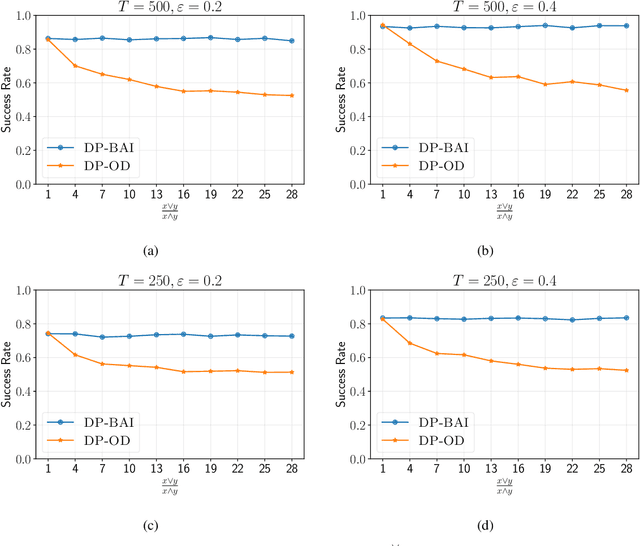
We study best arm identification (BAI) in linear bandits in the fixed-budget regime under differential privacy constraints, when the arm rewards are supported on the unit interval. Given a finite budget $T$ and a privacy parameter $\varepsilon>0$, the goal is to minimise the error probability in finding the arm with the largest mean after $T$ sampling rounds, subject to the constraint that the policy of the decision maker satisfies a certain {\em $\varepsilon$-differential privacy} ($\varepsilon$-DP) constraint. We construct a policy satisfying the $\varepsilon$-DP constraint (called {\sc DP-BAI}) by proposing the principle of {\em maximum absolute determinants}, and derive an upper bound on its error probability. Furthermore, we derive a minimax lower bound on the error probability, and demonstrate that the lower and the upper bounds decay exponentially in $T$, with exponents in the two bounds matching order-wise in (a) the sub-optimality gaps of the arms, (b) $\varepsilon$, and (c) the problem complexity that is expressible as the sum of two terms, one characterising the complexity of standard fixed-budget BAI (without privacy constraints), and the other accounting for the $\varepsilon$-DP constraint. Additionally, we present some auxiliary results that contribute to the derivation of the lower bound on the error probability. These results, we posit, may be of independent interest and could prove instrumental in proving lower bounds on error probabilities in several other bandit problems. Whereas prior works provide results for BAI in the fixed-budget regime without privacy constraints or in the fixed-confidence regime with privacy constraints, our work fills the gap in the literature by providing the results for BAI in the fixed-budget regime under the $\varepsilon$-DP constraint.
Learning to Search Feasible and Infeasible Regions of Routing Problems with Flexible Neural k-Opt
Oct 27, 2023In this paper, we present Neural k-Opt (NeuOpt), a novel learning-to-search (L2S) solver for routing problems. It learns to perform flexible k-opt exchanges based on a tailored action factorization method and a customized recurrent dual-stream decoder. As a pioneering work to circumvent the pure feasibility masking scheme and enable the autonomous exploration of both feasible and infeasible regions, we then propose the Guided Infeasible Region Exploration (GIRE) scheme, which supplements the NeuOpt policy network with feasibility-related features and leverages reward shaping to steer reinforcement learning more effectively. Additionally, we equip NeuOpt with Dynamic Data Augmentation (D2A) for more diverse searches during inference. Extensive experiments on the Traveling Salesman Problem (TSP) and Capacitated Vehicle Routing Problem (CVRP) demonstrate that our NeuOpt not only significantly outstrips existing (masking-based) L2S solvers, but also showcases superiority over the learning-to-construct (L2C) and learning-to-predict (L2P) solvers. Notably, we offer fresh perspectives on how neural solvers can handle VRP constraints. Our code is available: https://github.com/yining043/NeuOpt.
FLAC: A Robust Failure-Aware Atomic Commit Protocol for Distributed Transactions
Mar 02, 2023



In distributed transaction processing, atomic commit protocol (ACP) is used to ensure database consistency. With the use of commodity compute nodes and networks, failures such as system crashes and network partitioning are common. It is therefore important for ACP to dynamically adapt to the operating condition for efficiency while ensuring the consistency of the database. Existing ACPs often assume stable operating conditions, hence, they are either non-generalizable to different environments or slow in practice. In this paper, we propose a novel and practical ACP, called Failure-Aware Atomic Commit (FLAC). In essence, FLAC includes three protocols, which are specifically designed for three different environments: (i) no failure occurs, (ii) participant nodes might crash but there is no delayed connection, or (iii) both crashed nodes and delayed connection can occur. It models these environments as the failure-free, crash-failure, and network-failure robustness levels. During its operation, FLAC can monitor if any failure occurs and dynamically switch to operate the most suitable protocol, using a robustness level state machine, whose parameters are fine-tuned by reinforcement learning. Consequently, it improves both the response time and throughput, and effectively handles nodes distributed across the Internet where crash and network failures might occur. We implement FLAC in a distributed transactional key-value storage system based on Google Percolator and evaluate its performance with both a micro benchmark and a macro benchmark of real workload. The results show that FLAC achieves up to 2.22x throughput improvement and 2.82x latency speedup, compared to existing ACPs for high-contention workloads.
Federated Best Arm Identification with Heterogeneous Clients
Oct 17, 2022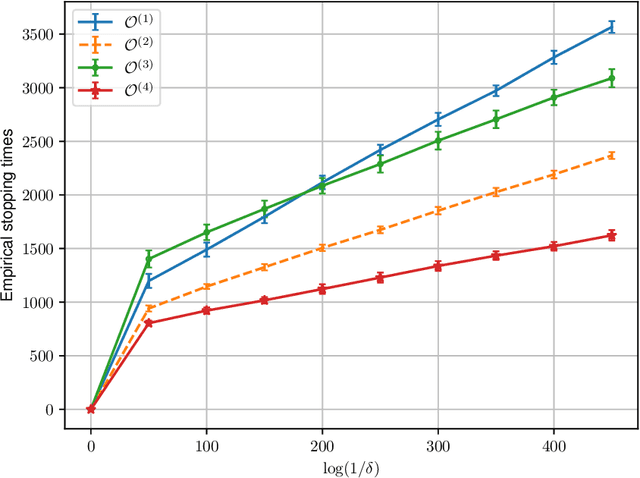
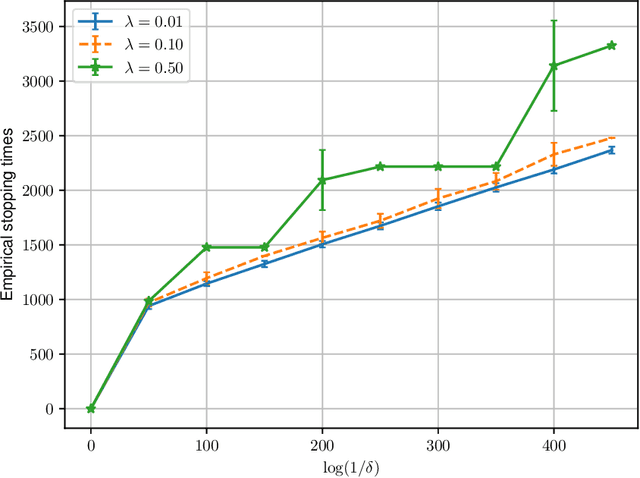
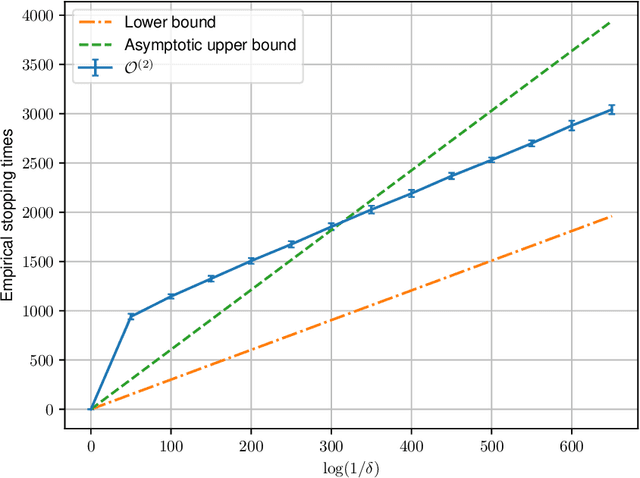
We study best arm identification in a federated multi-armed bandit setting with a central server and multiple clients, when each client has access to a {\em subset} of arms and each arm yields independent Gaussian observations. The {\em reward} from an arm at any given time is defined as the average of the observations generated at this time across all the clients that have access to the arm. The end goal is to identify the best arm (the arm with the largest mean reward) of each client with the least expected stopping time, subject to an upper bound on the error probability (i.e., the {\em fixed-confidence regime}). We provide a lower bound on the growth rate of the expected time to find the best arm of each client. Furthermore, we show that for any algorithm whose upper bound on the expected time to find the best arms matches with the lower bound up to a multiplicative constant, the ratio of any two consecutive communication time instants must be bounded, a result that is of independent interest. We then provide the first-known lower bound on the expected number of {\em communication rounds} required to find the best arms. We propose a novel algorithm based on the well-known {\em Track-and-Stop} strategy that communicates only at exponential time instants, and derive asymptotic upper bounds on its expected time to find the best arms and the expected number of communication rounds, where the asymptotics is one of vanishing error probabilities.
Learning Generalizable Models for Vehicle Routing Problems via Knowledge Distillation
Oct 14, 2022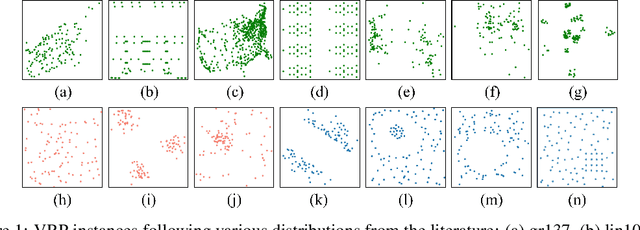
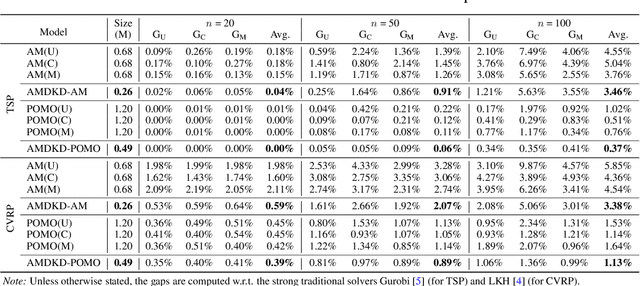
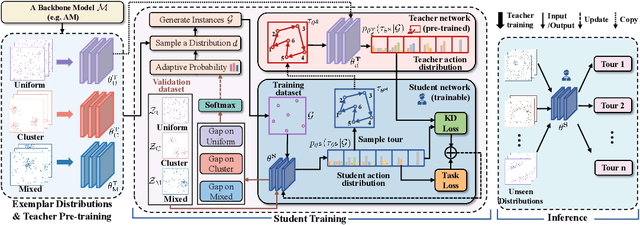
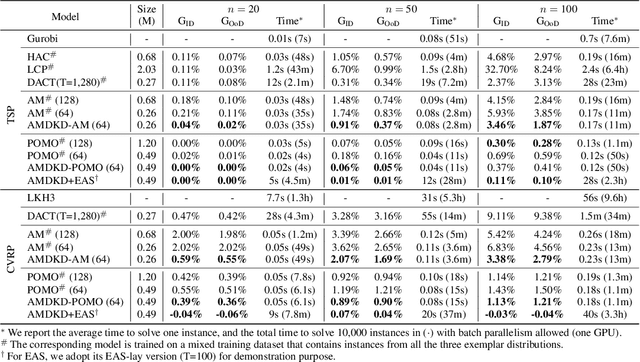
Recent neural methods for vehicle routing problems always train and test the deep models on the same instance distribution (i.e., uniform). To tackle the consequent cross-distribution generalization concerns, we bring the knowledge distillation to this field and propose an Adaptive Multi-Distribution Knowledge Distillation (AMDKD) scheme for learning more generalizable deep models. Particularly, our AMDKD leverages various knowledge from multiple teachers trained on exemplar distributions to yield a light-weight yet generalist student model. Meanwhile, we equip AMDKD with an adaptive strategy that allows the student to concentrate on difficult distributions, so as to absorb hard-to-master knowledge more effectively. Extensive experimental results show that, compared with the baseline neural methods, our AMDKD is able to achieve competitive results on both unseen in-distribution and out-of-distribution instances, which are either randomly synthesized or adopted from benchmark datasets (i.e., TSPLIB and CVRPLIB). Notably, our AMDKD is generic, and consumes less computational resources for inference.
Neural Network Decoders for Permutation Codes Correcting Different Errors
Jun 07, 2022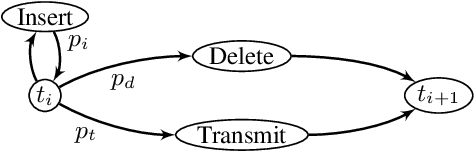
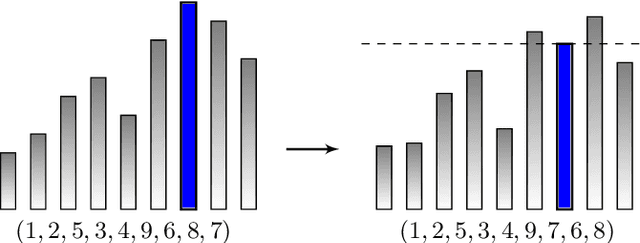
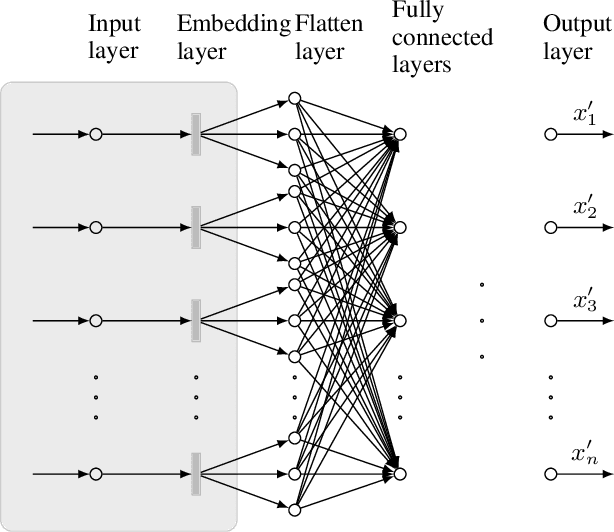
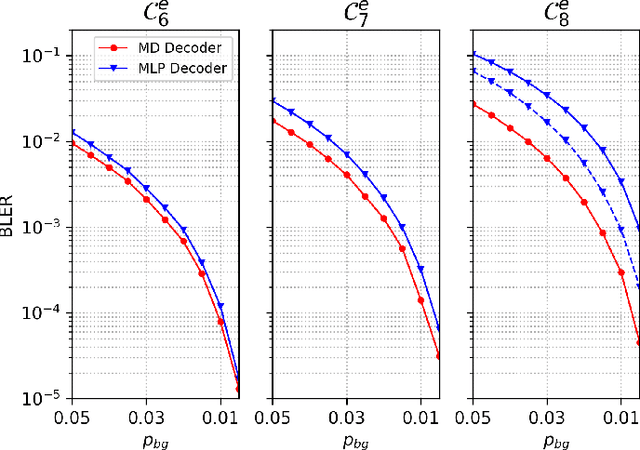
Permutation codes were extensively studied in order to correct different types of errors for the applications on power line communication and rank modulation for flash memory. In this paper, we introduce the neural network decoders for permutation codes to correct these errors with one-shot decoding, which treat the decoding as $n$ classification tasks for non-binary symbols for a code of length $n$. These are actually the first general decoders introduced to deal with any error type for these two applications. The performance of the decoders is evaluated by simulations with different error models.
Primitive3D: 3D Object Dataset Synthesis from Randomly Assembled Primitives
May 25, 2022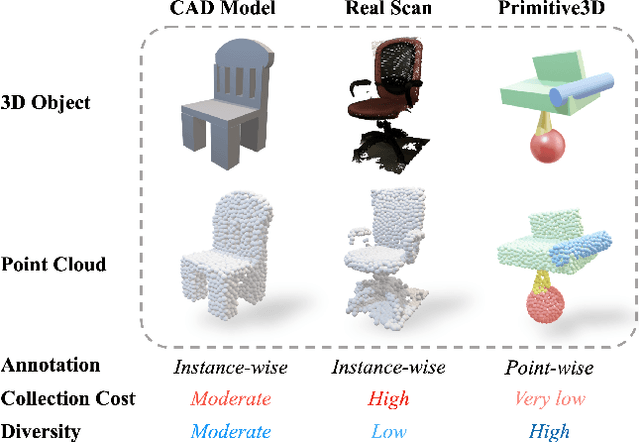

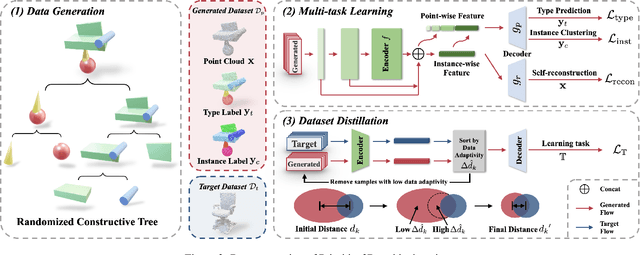
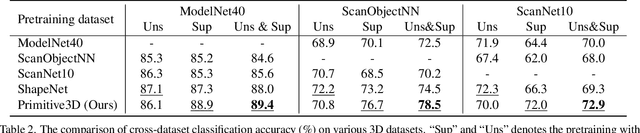
Numerous advancements in deep learning can be attributed to the access to large-scale and well-annotated datasets. However, such a dataset is prohibitively expensive in 3D computer vision due to the substantial collection cost. To alleviate this issue, we propose a cost-effective method for automatically generating a large amount of 3D objects with annotations. In particular, we synthesize objects simply by assembling multiple random primitives. These objects are thus auto-annotated with part labels originating from primitives. This allows us to perform multi-task learning by combining the supervised segmentation with unsupervised reconstruction. Considering the large overhead of learning on the generated dataset, we further propose a dataset distillation strategy to remove redundant samples regarding a target dataset. We conduct extensive experiments for the downstream tasks of 3D object classification. The results indicate that our dataset, together with multi-task pretraining on its annotations, achieves the best performance compared to other commonly used datasets. Further study suggests that our strategy can improve the model performance by pretraining and fine-tuning scheme, especially for the dataset with a small scale. In addition, pretraining with the proposed dataset distillation method can save 86\% of the pretraining time with negligible performance degradation. We expect that our attempt provides a new data-centric perspective for training 3D deep models.
Efficient Neural Neighborhood Search for Pickup and Delivery Problems
Apr 25, 2022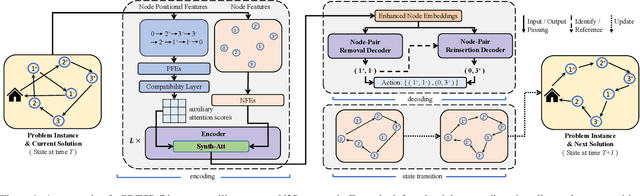



We present an efficient Neural Neighborhood Search (N2S) approach for pickup and delivery problems (PDPs). In specific, we design a powerful Synthesis Attention that allows the vanilla self-attention to synthesize various types of features regarding a route solution. We also exploit two customized decoders that automatically learn to perform removal and reinsertion of a pickup-delivery node pair to tackle the precedence constraint. Additionally, a diversity enhancement scheme is leveraged to further ameliorate the performance. Our N2S is generic, and extensive experiments on two canonical PDP variants show that it can produce state-of-the-art results among existing neural methods. Moreover, it even outstrips the well-known LKH3 solver on the more constrained PDP variant. Our implementation for N2S is available online.