 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Structured Memory for Dynamic Multi-modal In-Context Learning
Jun 10, 2026Multi-modal large language models (MLLMs) depend on in-context learning (ICL) for rapid task adaptation, but their scalability is severely limited by finite context windows and the growing cost of key-value (KV) caches in long multi-modal sequences. Existing memory compression approaches typically rely on rigid token removal or sample-dependent importance estimation, which introduces bias, disrupts semantic structure, particularly for visual representations, and yields static memories that cannot adapt to new queries. We introduce TASM (Task-Aware Structured Memory), a training-free framework that addresses these limitations through task-aware, structure-preserving, and dynamically accessible memory construction. TASM employs task-vector guided compression to replace sample-specific signals with a task-level direction that captures shared relevance across demonstrations. To preserve the underlying manifold, it applies semantics-aware token merging via bipartite graph matching, aggregating tokens without destructive pruning. Finally, TASM structures memory into a hierarchy comprising a compact Core Memory and a Latent Bank, facilitating query-adaptive dynamic retrieval. Evaluations confirm TASM maintains high performance under heavy compression, effectively balancing efficiency with adaptability.
Learning from Contrasts: Synthesizing Reasoning Paths from Diverse Search Trajectories
Apr 13, 2026Monte Carlo Tree Search (MCTS) has been widely used for automated reasoning data exploration, but current supervision extraction methods remain inefficient. Standard approaches retain only the single highest-reward trajectory, discarding the comparative signals present in the many explored paths. Here we introduce \textbf{Contrastive Reasoning Path Synthesis (CRPS)}, a framework that transforms supervision extraction from a filtering process into a synthesis procedure. CRPS uses a structured reflective process to analyze the differences between high- and low-quality search trajectories, extracting explicit information about strategic pivots and local failure modes. These insights guide the synthesis of reasoning chains that incorporate success patterns while avoiding identified pitfalls. We show empirically that models fine-tuned on just 60K CRPS-synthesized examples match or exceed the performance of baselines trained on 590K examples derived from standard rejection sampling, a 20$\times$ reduction in dataset size. Furthermore, CRPS improves generalization on out-of-domain benchmarks, demonstrating that learning from the contrast between success and failure produces more transferable reasoning capabilities than learning from success alone.
StructKV: Preserving the Structural Skeleton for Scalable Long-Context Inference
Apr 08, 2026As Large Language Models (LLMs) scale to support context windows exceeding one million tokens, the linear growth of Key-Value (KV) cache imposes severe memory capacity and bandwidth bottlenecks, constraining the efficiency of long-context inference. Existing compression approaches typically prioritize tokens based on local saliency metrics to decouple prefill computation from decoding memory. However, these methods often rely on local saliency snapshots at a specific layer, thereby systematically discarding tokens that act as global information hubs across the network depth but appear temporarily dormant at the specific layer selected for pruning. To address this limitation, we propose StructKV, a structure-aware KV cache compression framework that introduces three core innovations: First, Global In-Degree Centrality aggregates attention patterns across the network depth to identify global information hubs. Second, Dynamic Pivot Detection utilizes information-theoretic metrics to adaptively locate the optimal layer for compression. Finally, Structural Propagation and Decoupling separates the computational budget from the memory storage budget. Experimental results on the LongBench and RULER benchmarks demonstrate that StructKV effectively preserves long-range dependencies and retrieval robustness.
Words or Vision: Do Vision-Language Models Have Blind Faith in Text?
Mar 04, 2025Vision-Language Models (VLMs) excel in integrating visual and textual information for vision-centric tasks, but their handling of inconsistencies between modalities is underexplored. We investigate VLMs' modality preferences when faced with visual data and varied textual inputs in vision-centered settings. By introducing textual variations to four vision-centric tasks and evaluating ten Vision-Language Models (VLMs), we discover a \emph{``blind faith in text''} phenomenon: VLMs disproportionately trust textual data over visual data when inconsistencies arise, leading to significant performance drops under corrupted text and raising safety concerns. We analyze factors influencing this text bias, including instruction prompts, language model size, text relevance, token order, and the interplay between visual and textual certainty. While certain factors, such as scaling up the language model size, slightly mitigate text bias, others like token order can exacerbate it due to positional biases inherited from language models. To address this issue, we explore supervised fine-tuning with text augmentation and demonstrate its effectiveness in reducing text bias. Additionally, we provide a theoretical analysis suggesting that the blind faith in text phenomenon may stem from an imbalance of pure text and multi-modal data during training. Our findings highlight the need for balanced training and careful consideration of modality interactions in VLMs to enhance their robustness and reliability in handling multi-modal data inconsistencies.
Optimal Multi-Objective Best Arm Identification with Fixed Confidence
Jan 23, 2025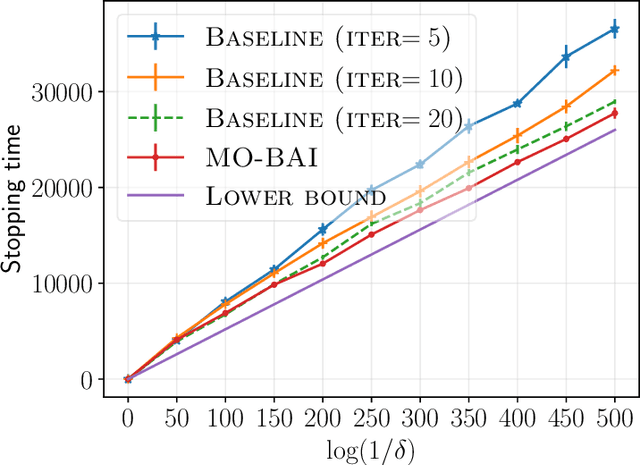

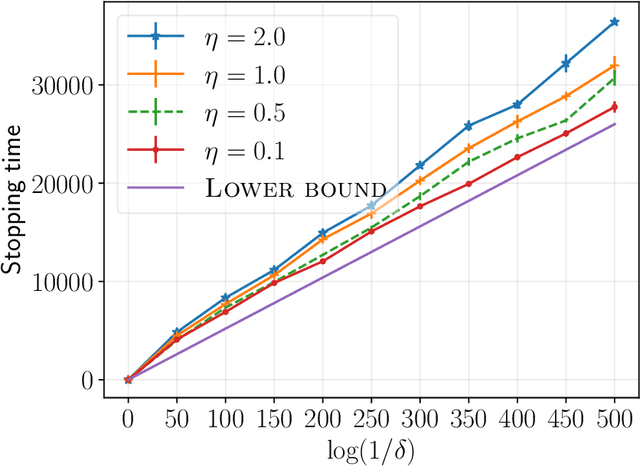

We consider a multi-armed bandit setting with finitely many arms, in which each arm yields an $M$-dimensional vector reward upon selection. We assume that the reward of each dimension (a.k.a. {\em objective}) is generated independently of the others. The best arm of any given objective is the arm with the largest component of mean corresponding to the objective. The end goal is to identify the best arm of {\em every} objective in the shortest (expected) time subject to an upper bound on the probability of error (i.e., fixed-confidence regime). We establish a problem-dependent lower bound on the limiting growth rate of the expected stopping time, in the limit of vanishing error probabilities. This lower bound, we show, is characterised by a max-min optimisation problem that is computationally expensive to solve at each time step. We propose an algorithm that uses the novel idea of {\em surrogate proportions} to sample the arms at each time step, eliminating the need to solve the max-min optimisation problem at each step. We demonstrate theoretically that our algorithm is asymptotically optimal. In addition, we provide extensive empirical studies to substantiate the efficiency of our algorithm. While existing works on pure exploration with multi-objective multi-armed bandits predominantly focus on {\em Pareto frontier identification}, our work fills the gap in the literature by conducting a formal investigation of the multi-objective best arm identification problem.
Order-Optimal Instance-Dependent Bounds for Offline Reinforcement Learning with Preference Feedback
Jun 18, 2024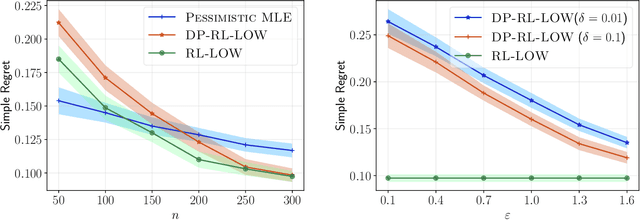
We consider offline reinforcement learning (RL) with preference feedback in which the implicit reward is a linear function of an unknown parameter. Given an offline dataset, our objective consists in ascertaining the optimal action for each state, with the ultimate goal of minimizing the {\em simple regret}. We propose an algorithm, \underline{RL} with \underline{L}ocally \underline{O}ptimal \underline{W}eights or {\sc RL-LOW}, which yields a simple regret of $\exp ( - \Omega(n/H) )$ where $n$ is the number of data samples and $H$ denotes an instance-dependent hardness quantity that depends explicitly on the suboptimality gap of each action. Furthermore, we derive a first-of-its-kind instance-dependent lower bound in offline RL with preference feedback. Interestingly, we observe that the lower and upper bounds on the simple regret match order-wise in the exponent, demonstrating order-wise optimality of {\sc RL-LOW}. In view of privacy considerations in practical applications, we also extend {\sc RL-LOW} to the setting of $(\varepsilon,\delta)$-differential privacy and show, somewhat surprisingly, that the hardness parameter $H$ is unchanged in the asymptotic regime as $n$ tends to infinity; this underscores the inherent efficiency of {\sc RL-LOW} in terms of preserving the privacy of the observed rewards. Given our focus on establishing instance-dependent bounds, our work stands in stark contrast to previous works that focus on establishing worst-case regrets for offline RL with preference feedback.
A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
Mar 21, 2024Neural Code Intelligence -- leveraging deep learning to understand, generate, and optimize code -- holds immense potential for transformative impacts on the whole society. Bridging the gap between Natural Language and Programming Language, this domain has drawn significant attention from researchers in both research communities over the past few years. This survey presents a systematic and chronological review of the advancements in code intelligence, encompassing over 50 representative models and their variants, more than 20 categories of tasks, and an extensive coverage of over 680 related works. We follow the historical progression to trace the paradigm shifts across different research phases (e.g., from modeling code with recurrent neural networks to the era of Large Language Models). Concurrently, we highlight the major technical transitions in models, tasks, and evaluations spanning through different stages. For applications, we also observe a co-evolving shift. It spans from initial endeavors to tackling specific scenarios, through exploring a diverse array of tasks during its rapid expansion, to currently focusing on tackling increasingly complex and varied real-world challenges. Building on our examination of the developmental trajectories, we further investigate the emerging synergies between code intelligence and broader machine intelligence, uncovering new cross-domain opportunities and illustrating the substantial influence of code intelligence across various domains. Finally, we delve into both the opportunities and challenges associated with this field, alongside elucidating our insights on the most promising research directions. An ongoing, dynamically updated project and resources associated with this survey have been released at https://github.com/QiushiSun/NCISurvey.
Seeing is Believing: Mitigating Hallucination in Large Vision-Language Models via CLIP-Guided Decoding
Feb 23, 2024Large Vision-Language Models (LVLMs) are susceptible to object hallucinations, an issue in which their generated text contains non-existent objects, greatly limiting their reliability and practicality. Current approaches often rely on the model's token likelihoods or other internal information, instruction tuning on additional datasets, or incorporating complex external tools. We first perform empirical analysis on sentence-level LVLM hallucination, finding that CLIP similarity to the image acts as a stronger and more robust indicator of hallucination compared to token likelihoods. Motivated by this, we introduce our CLIP-Guided Decoding (CGD) approach, a straightforward but effective training-free approach to reduce object hallucination at decoding time. CGD uses CLIP to guide the model's decoding process by enhancing visual grounding of generated text with the image. Experiments demonstrate that CGD effectively mitigates object hallucination across multiple LVLM families while preserving the utility of text generation.
Fixed-Budget Differentially Private Best Arm Identification
Jan 17, 2024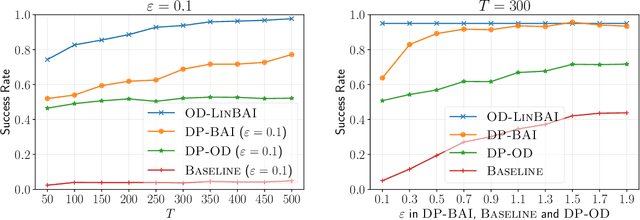

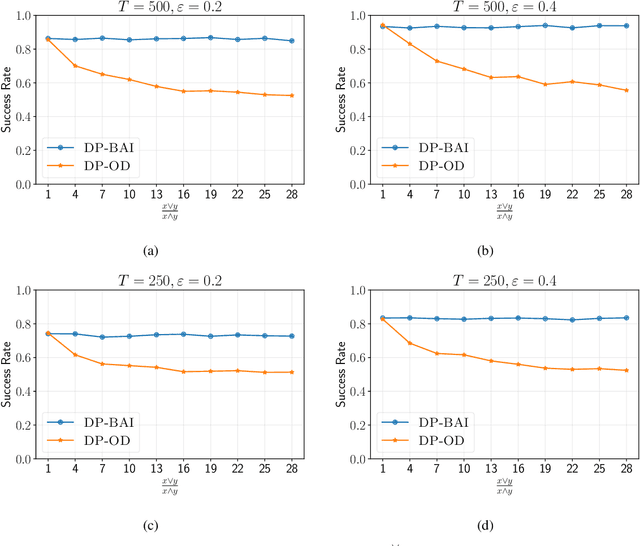
We study best arm identification (BAI) in linear bandits in the fixed-budget regime under differential privacy constraints, when the arm rewards are supported on the unit interval. Given a finite budget $T$ and a privacy parameter $\varepsilon>0$, the goal is to minimise the error probability in finding the arm with the largest mean after $T$ sampling rounds, subject to the constraint that the policy of the decision maker satisfies a certain {\em $\varepsilon$-differential privacy} ($\varepsilon$-DP) constraint. We construct a policy satisfying the $\varepsilon$-DP constraint (called {\sc DP-BAI}) by proposing the principle of {\em maximum absolute determinants}, and derive an upper bound on its error probability. Furthermore, we derive a minimax lower bound on the error probability, and demonstrate that the lower and the upper bounds decay exponentially in $T$, with exponents in the two bounds matching order-wise in (a) the sub-optimality gaps of the arms, (b) $\varepsilon$, and (c) the problem complexity that is expressible as the sum of two terms, one characterising the complexity of standard fixed-budget BAI (without privacy constraints), and the other accounting for the $\varepsilon$-DP constraint. Additionally, we present some auxiliary results that contribute to the derivation of the lower bound on the error probability. These results, we posit, may be of independent interest and could prove instrumental in proving lower bounds on error probabilities in several other bandit problems. Whereas prior works provide results for BAI in the fixed-budget regime without privacy constraints or in the fixed-confidence regime with privacy constraints, our work fills the gap in the literature by providing the results for BAI in the fixed-budget regime under the $\varepsilon$-DP constraint.
Trust, but Verify: Using Self-Supervised Probing to Improve Trustworthiness
Feb 06, 2023Trustworthy machine learning is of primary importance to the practical deployment of deep learning models. While state-of-the-art models achieve astonishingly good performance in terms of accuracy, recent literature reveals that their predictive confidence scores unfortunately cannot be trusted: e.g., they are often overconfident when wrong predictions are made, or so even for obvious outliers. In this paper, we introduce a new approach of self-supervised probing, which enables us to check and mitigate the overconfidence issue for a trained model, thereby improving its trustworthiness. We provide a simple yet effective framework, which can be flexibly applied to existing trustworthiness-related methods in a plug-and-play manner. Extensive experiments on three trustworthiness-related tasks (misclassification detection, calibration and out-of-distribution detection) across various benchmarks verify the effectiveness of our proposed probing framework.