 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder-Optimal Instance-Dependent Bounds for Offline Reinforcement Learning with Preference Feedback
Paper and Code
Jun 18, 2024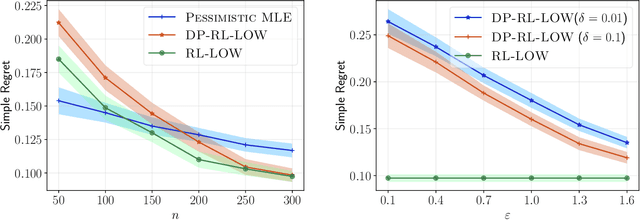
We consider offline reinforcement learning (RL) with preference feedback in which the implicit reward is a linear function of an unknown parameter. Given an offline dataset, our objective consists in ascertaining the optimal action for each state, with the ultimate goal of minimizing the {\em simple regret}. We propose an algorithm, \underline{RL} with \underline{L}ocally \underline{O}ptimal \underline{W}eights or {\sc RL-LOW}, which yields a simple regret of $\exp ( - \Omega(n/H) )$ where $n$ is the number of data samples and $H$ denotes an instance-dependent hardness quantity that depends explicitly on the suboptimality gap of each action. Furthermore, we derive a first-of-its-kind instance-dependent lower bound in offline RL with preference feedback. Interestingly, we observe that the lower and upper bounds on the simple regret match order-wise in the exponent, demonstrating order-wise optimality of {\sc RL-LOW}. In view of privacy considerations in practical applications, we also extend {\sc RL-LOW} to the setting of $(\varepsilon,\delta)$-differential privacy and show, somewhat surprisingly, that the hardness parameter $H$ is unchanged in the asymptotic regime as $n$ tends to infinity; this underscores the inherent efficiency of {\sc RL-LOW} in terms of preserving the privacy of the observed rewards. Given our focus on establishing instance-dependent bounds, our work stands in stark contrast to previous works that focus on establishing worst-case regrets for offline RL with preference feedback.