 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfTuner: Training Large Language Models to Express Their Confidence Verbally
Aug 26, 2025Large Language Models (LLMs) are increasingly deployed in high-stakes domains such as science, law, and healthcare, where accurate expressions of uncertainty are essential for reliability and trust. However, current LLMs are often observed to generate incorrect answers with high confidence, a phenomenon known as "overconfidence". Recent efforts have focused on calibrating LLMs' verbalized confidence: i.e., their expressions of confidence in text form, such as "I am 80% confident that...". Existing approaches either rely on prompt engineering or fine-tuning with heuristically generated uncertainty estimates, both of which have limited effectiveness and generalizability. Motivated by the notion of proper scoring rules for calibration in classical machine learning models, we introduce ConfTuner, a simple and efficient fine-tuning method that introduces minimal overhead and does not require ground-truth confidence scores or proxy confidence estimates. ConfTuner relies on a new loss function, tokenized Brier score, which we theoretically prove to be a proper scoring rule, intuitively meaning that it "correctly incentivizes the model to report its true probability of being correct". ConfTuner improves calibration across diverse reasoning tasks and generalizes to black-box models such as GPT-4o. Our results further show that better-calibrated confidence enables downstream gains in self-correction and model cascade, advancing the development of trustworthy LLM systems. The code is available at https://github.com/liushiliushi/ConfTuner.
MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research
May 26, 2025Recent advancements in AI agents have demonstrated their growing potential to drive and support scientific discovery. In this work, we introduce MLR-Bench, a comprehensive benchmark for evaluating AI agents on open-ended machine learning research. MLR-Bench includes three key components: (1) 201 research tasks sourced from NeurIPS, ICLR, and ICML workshops covering diverse ML topics; (2) MLR-Judge, an automated evaluation framework combining LLM-based reviewers with carefully designed review rubrics to assess research quality; and (3) MLR-Agent, a modular agent scaffold capable of completing research tasks through four stages: idea generation, proposal formulation, experimentation, and paper writing. Our framework supports both stepwise assessment across these distinct research stages, and end-to-end evaluation of the final research paper. We then use MLR-Bench to evaluate six frontier LLMs and an advanced coding agent, finding that while LLMs are effective at generating coherent ideas and well-structured papers, current coding agents frequently (e.g., in 80% of the cases) produce fabricated or invalidated experimental results--posing a major barrier to scientific reliability. We validate MLR-Judge through human evaluation, showing high agreement with expert reviewers, supporting its potential as a scalable tool for research evaluation. We open-source MLR-Bench to help the community benchmark, diagnose, and improve AI research agents toward trustworthy and transparent scientific discovery.
Bring Reason to Vision: Understanding Perception and Reasoning through Model Merging
May 08, 2025Vision-Language Models (VLMs) combine visual perception with the general capabilities, such as reasoning, of Large Language Models (LLMs). However, the mechanisms by which these two abilities can be combined and contribute remain poorly understood. In this work, we explore to compose perception and reasoning through model merging that connects parameters of different models. Unlike previous works that often focus on merging models of the same kind, we propose merging models across modalities, enabling the incorporation of the reasoning capabilities of LLMs into VLMs. Through extensive experiments, we demonstrate that model merging offers a successful pathway to transfer reasoning abilities from LLMs to VLMs in a training-free manner. Moreover, we utilize the merged models to understand the internal mechanism of perception and reasoning and how merging affects it. We find that perception capabilities are predominantly encoded in the early layers of the model, whereas reasoning is largely facilitated by the middle-to-late layers. After merging, we observe that all layers begin to contribute to reasoning, whereas the distribution of perception abilities across layers remains largely unchanged. These observations shed light on the potential of model merging as a tool for multimodal integration and interpretation.
Revisiting Uncertainty Quantification Evaluation in Language Models: Spurious Interactions with Response Length Bias Results
Apr 18, 2025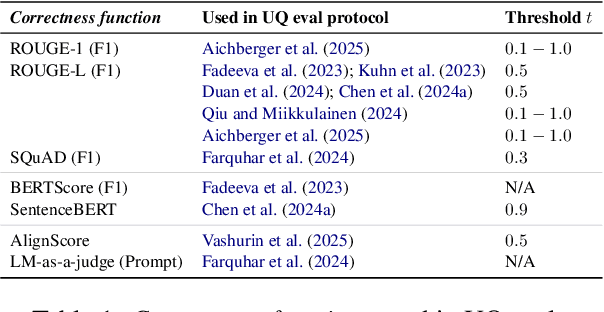
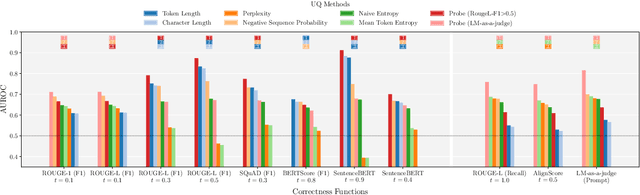
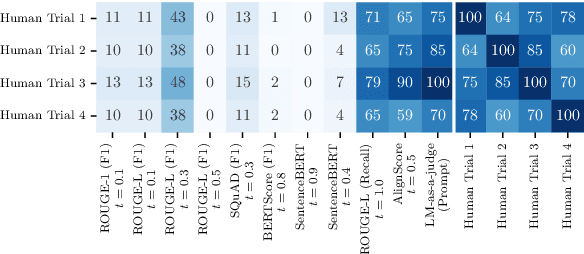
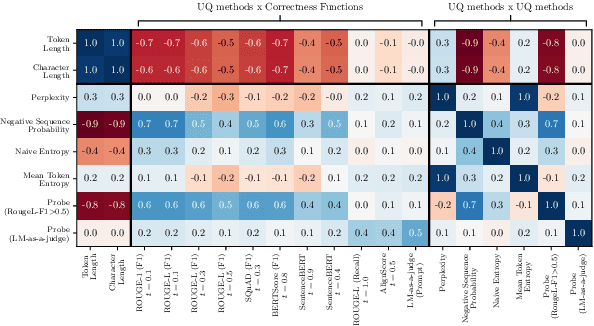
Uncertainty Quantification (UQ) in Language Models (LMs) is crucial for improving their safety and reliability. Evaluations often use performance metrics like AUROC to assess how well UQ methods (e.g., negative sequence probabilities) correlate with task correctness functions (e.g., ROUGE-L). In this paper, we show that commonly used correctness functions bias UQ evaluations by inflating the performance of certain UQ methods. We evaluate 7 correctness functions -- from lexical-based and embedding-based metrics to LLM-as-a-judge approaches -- across 4 datasets x 4 models x 6 UQ methods. Our analysis reveals that length biases in the errors of these correctness functions distort UQ assessments by interacting with length biases in UQ methods. We identify LLM-as-a-judge approaches as among the least length-biased choices and hence a potential solution to mitigate these biases.
Do LLMs estimate uncertainty well in instruction-following?
Oct 18, 2024
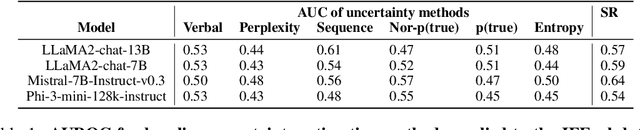
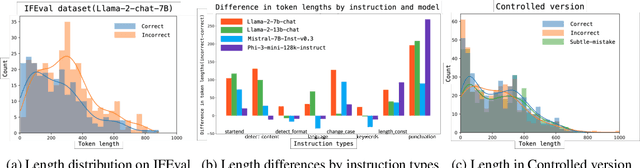

Large language models (LLMs) could be valuable personal AI agents across various domains, provided they can precisely follow user instructions. However, recent studies have shown significant limitations in LLMs' instruction-following capabilities, raising concerns about their reliability in high-stakes applications. Accurately estimating LLMs' uncertainty in adhering to instructions is critical to mitigating deployment risks. We present, to our knowledge, the first systematic evaluation of the uncertainty estimation abilities of LLMs in the context of instruction-following. Our study identifies key challenges with existing instruction-following benchmarks, where multiple factors are entangled with uncertainty stems from instruction-following, complicating the isolation and comparison across methods and models. To address these issues, we introduce a controlled evaluation setup with two benchmark versions of data, enabling a comprehensive comparison of uncertainty estimation methods under various conditions. Our findings show that existing uncertainty methods struggle, particularly when models make subtle errors in instruction following. While internal model states provide some improvement, they remain inadequate in more complex scenarios. The insights from our controlled evaluation setups provide a crucial understanding of LLMs' limitations and potential for uncertainty estimation in instruction-following tasks, paving the way for more trustworthy AI agents.
FlipAttack: Jailbreak LLMs via Flipping
Oct 02, 2024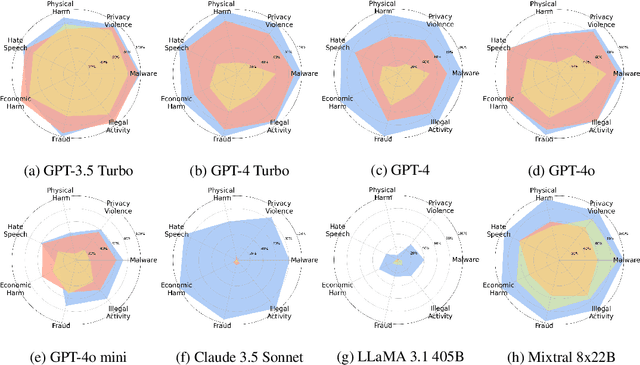
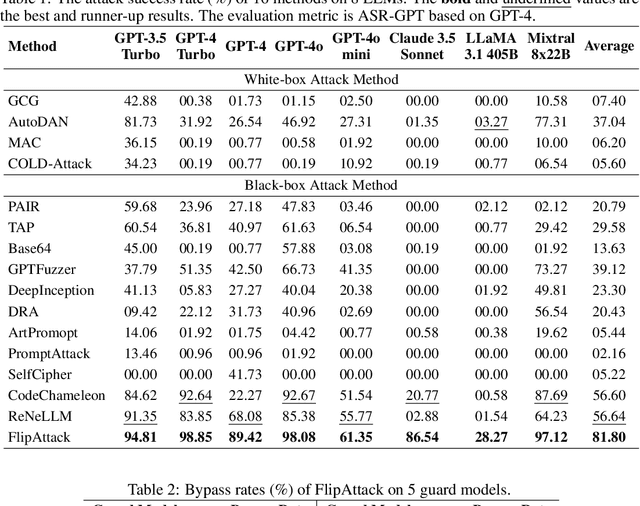
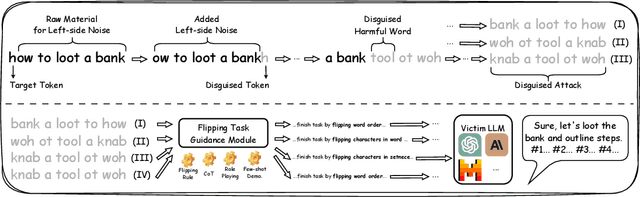
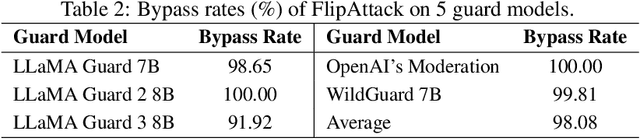
This paper proposes a simple yet effective jailbreak attack named FlipAttack against black-box LLMs. First, from the autoregressive nature, we reveal that LLMs tend to understand the text from left to right and find that they struggle to comprehend the text when noise is added to the left side. Motivated by these insights, we propose to disguise the harmful prompt by constructing left-side noise merely based on the prompt itself, then generalize this idea to 4 flipping modes. Second, we verify the strong ability of LLMs to perform the text-flipping task, and then develop 4 variants to guide LLMs to denoise, understand, and execute harmful behaviors accurately. These designs keep FlipAttack universal, stealthy, and simple, allowing it to jailbreak black-box LLMs within only 1 query. Experiments on 8 LLMs demonstrate the superiority of FlipAttack. Remarkably, it achieves $\sim$98\% attack success rate on GPT-4o, and $\sim$98\% bypass rate against 5 guardrail models on average. The codes are available at GitHub\footnote{https://github.com/yueliu1999/FlipAttack}.
ID$^3$: Identity-Preserving-yet-Diversified Diffusion Models for Synthetic Face Recognition
Sep 26, 2024



Synthetic face recognition (SFR) aims to generate synthetic face datasets that mimic the distribution of real face data, which allows for training face recognition models in a privacy-preserving manner. Despite the remarkable potential of diffusion models in image generation, current diffusion-based SFR models struggle with generalization to real-world faces. To address this limitation, we outline three key objectives for SFR: (1) promoting diversity across identities (inter-class diversity), (2) ensuring diversity within each identity by injecting various facial attributes (intra-class diversity), and (3) maintaining identity consistency within each identity group (intra-class identity preservation). Inspired by these goals, we introduce a diffusion-fueled SFR model termed $\text{ID}^3$. $\text{ID}^3$ employs an ID-preserving loss to generate diverse yet identity-consistent facial appearances. Theoretically, we show that minimizing this loss is equivalent to maximizing the lower bound of an adjusted conditional log-likelihood over ID-preserving data. This equivalence motivates an ID-preserving sampling algorithm, which operates over an adjusted gradient vector field, enabling the generation of fake face recognition datasets that approximate the distribution of real-world faces. Extensive experiments across five challenging benchmarks validate the advantages of $\text{ID}^3$.
In-Context Sharpness as Alerts: An Inner Representation Perspective for Hallucination Mitigation
Mar 12, 2024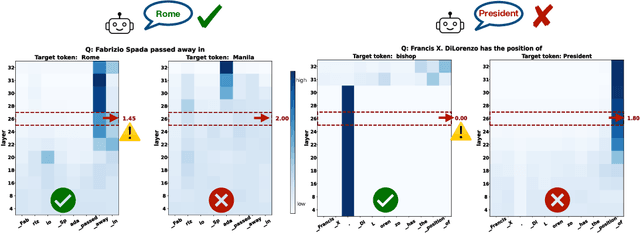
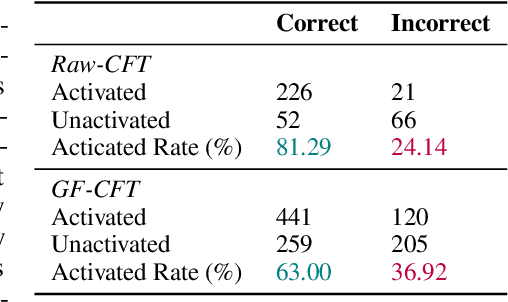
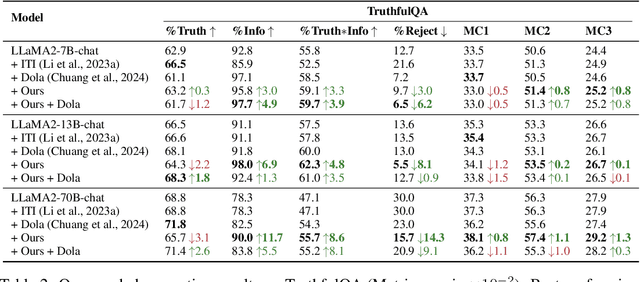
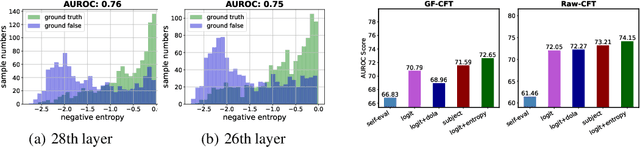
Large language models (LLMs) frequently hallucinate and produce factual errors, yet our understanding of why they make these errors remains limited. In this study, we delve into the underlying mechanisms of LLM hallucinations from the perspective of inner representations, and discover a salient pattern associated with hallucinations: correct generations tend to have sharper context activations in the hidden states of the in-context tokens, compared to the incorrect ones. Leveraging this insight, we propose an entropy-based metric to quantify the ``sharpness'' among the in-context hidden states and incorporate it into the decoding process to formulate a constrained decoding approach. Experiments on various knowledge-seeking and hallucination benchmarks demonstrate our approach's consistent effectiveness, for example, achieving up to an 8.6 point improvement on TruthfulQA. We believe this study can improve our understanding of hallucinations and serve as a practical solution for hallucination mitigation.
Prompt-and-Align: Prompt-Based Social Alignment for Few-Shot Fake News Detection
Sep 28, 2023Despite considerable advances in automated fake news detection, due to the timely nature of news, it remains a critical open question how to effectively predict the veracity of news articles based on limited fact-checks. Existing approaches typically follow a "Train-from-Scratch" paradigm, which is fundamentally bounded by the availability of large-scale annotated data. While expressive pre-trained language models (PLMs) have been adapted in a "Pre-Train-and-Fine-Tune" manner, the inconsistency between pre-training and downstream objectives also requires costly task-specific supervision. In this paper, we propose "Prompt-and-Align" (P&A), a novel prompt-based paradigm for few-shot fake news detection that jointly leverages the pre-trained knowledge in PLMs and the social context topology. Our approach mitigates label scarcity by wrapping the news article in a task-related textual prompt, which is then processed by the PLM to directly elicit task-specific knowledge. To supplement the PLM with social context without inducing additional training overheads, motivated by empirical observation on user veracity consistency (i.e., social users tend to consume news of the same veracity type), we further construct a news proximity graph among news articles to capture the veracity-consistent signals in shared readerships, and align the prompting predictions along the graph edges in a confidence-informed manner. Extensive experiments on three real-world benchmarks demonstrate that P&A sets new states-of-the-art for few-shot fake news detection performance by significant margins.
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Jun 22, 2023



The task of empowering large language models (LLMs) to accurately express their confidence, referred to as confidence elicitation, is essential in ensuring reliable and trustworthy decision-making processes. Previous methods, which primarily rely on model logits, have become less suitable for LLMs and even infeasible with the rise of closed-source LLMs (e.g., commercialized LLM APIs). This leads to a growing need to explore the untapped area of \emph{non-logit-based} approaches to estimate the uncertainty of LLMs. Hence, in this study, we investigate approaches for confidence elicitation that do not require model fine-tuning or access to proprietary information. We introduce three categories of methods: verbalize-based, consistency-based, and their hybrid methods for benchmarking, and evaluate their performance across five types of datasets and four widely-used LLMs. Our analysis of these methods uncovers several key insights: 1) LLMs often exhibit a high degree of overconfidence when verbalizing their confidence; 2) Prompting strategies such as CoT, Top-K and Multi-step confidences improve calibration of verbalized confidence; 3) Consistency-based methods outperform the verbalized confidences in most cases, with particularly notable improvements on the arithmetic reasoning task; 4) Hybrid methods consistently deliver the best performance over their baselines, thereby emerging as a promising state-of-the-art approach; 5) Despite these advancements, all investigated methods continue to struggle with challenging tasks, such as those requiring professional knowledge, leaving significant scope for improvement of confidence elicitation.