 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-causal domain generalization: Leveraging unlabeled data
Feb 19, 2026The problem of domain generalization concerns learning predictive models that are robust to distribution shifts when deployed in new, previously unseen environments. Existing methods typically require labeled data from multiple training environments, limiting their applicability when labeled data are scarce. In this work, we study domain generalization in an anti-causal setting, where the outcome causes the observed covariates. Under this structure, environment perturbations that affect the covariates do not propagate to the outcome, which motivates regularizing the model's sensitivity to these perturbations. Crucially, estimating these perturbation directions does not require labels, enabling us to leverage unlabeled data from multiple environments. We propose two methods that penalize the model's sensitivity to variations in the mean and covariance of the covariates across environments, respectively, and prove that these methods have worst-case optimality guarantees under certain classes of environments. Finally, we demonstrate the empirical performance of our approach on a controlled physical system and a physiological signal dataset.
Hybrid Modeling of Photoplethysmography for Non-invasive Monitoring of Cardiovascular Parameters
Nov 18, 2025Continuous cardiovascular monitoring can play a key role in precision health. However, some fundamental cardiac biomarkers of interest, including stroke volume and cardiac output, require invasive measurements, e.g., arterial pressure waveforms (APW). As a non-invasive alternative, photoplethysmography (PPG) measurements are routinely collected in hospital settings. Unfortunately, the prediction of key cardiac biomarkers from PPG instead of APW remains an open challenge, further complicated by the scarcity of annotated PPG measurements. As a solution, we propose a hybrid approach that uses hemodynamic simulations and unlabeled clinical data to estimate cardiovascular biomarkers directly from PPG signals. Our hybrid model combines a conditional variational autoencoder trained on paired PPG-APW data with a conditional density estimator of cardiac biomarkers trained on labeled simulated APW segments. As a key result, our experiments demonstrate that the proposed approach can detect fluctuations of cardiac output and stroke volume and outperform a supervised baseline in monitoring temporal changes in these biomarkers.
Considerations for Distribution Shift Robustness of Diagnostic Models in Healthcare
Oct 25, 2024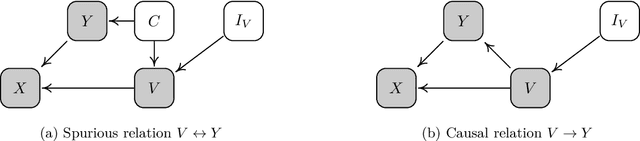
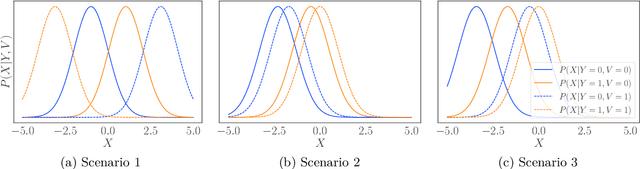
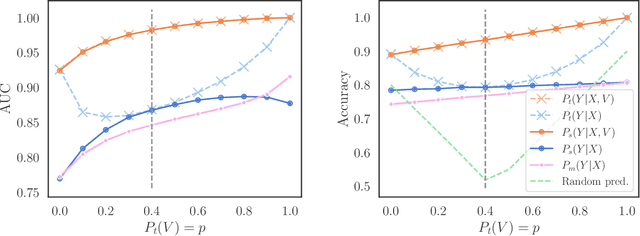
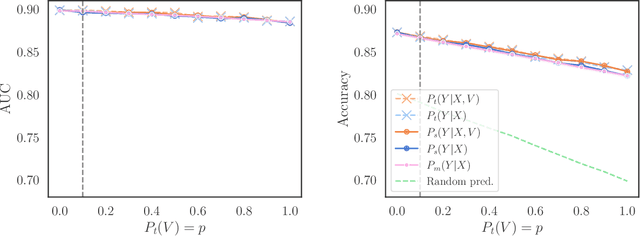
We consider robustness to distribution shifts in the context of diagnostic models in healthcare, where the prediction target $Y$, e.g., the presence of a disease, is causally upstream of the observations $X$, e.g., a biomarker. Distribution shifts may occur, for instance, when the training data is collected in a domain with patients having particular demographic characteristics while the model is deployed on patients from a different demographic group. In the domain of applied ML for health, it is common to predict $Y$ from $X$ without considering further information about the patient. However, beyond the direct influence of the disease $Y$ on biomarker $X$, a predictive model may learn to exploit confounding dependencies (or shortcuts) between $X$ and $Y$ that are unstable under certain distribution shifts. In this work, we highlight a data generating mechanism common to healthcare settings and discuss how recent theoretical results from the causality literature can be applied to build robust predictive models. We theoretically show why ignoring covariates as well as common invariant learning approaches will in general not yield robust predictors in the studied setting, while including certain covariates into the prediction model will. In an extensive simulation study, we showcase the robustness (or lack thereof) of different predictors under various data generating processes. Lastly, we analyze the performance of the different approaches using the PTB-XL dataset, a public dataset of annotated ECG recordings.
Do LLMs "know" internally when they follow instructions?
Oct 22, 2024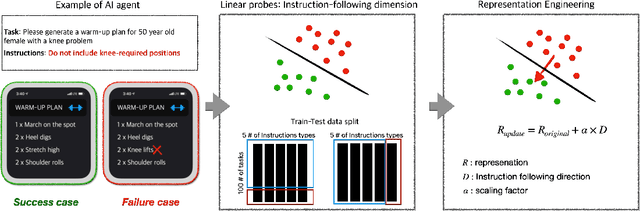


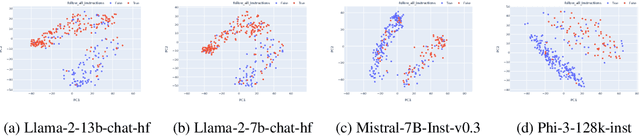
Instruction-following is crucial for building AI agents with large language models (LLMs), as these models must adhere strictly to user-provided constraints and guidelines. However, LLMs often fail to follow even simple and clear instructions. To improve instruction-following behavior and prevent undesirable outputs, a deeper understanding of how LLMs' internal states relate to these outcomes is required. Our analysis of LLM internal states reveal a dimension in the input embedding space linked to successful instruction-following. We demonstrate that modifying representations along this dimension improves instruction-following success rates compared to random changes, without compromising response quality. Further investigation reveals that this dimension is more closely related to the phrasing of prompts rather than the inherent difficulty of the task or instructions. This discovery also suggests explanations for why LLMs sometimes fail to follow clear instructions and why prompt engineering is often effective, even when the content remains largely unchanged. This work provides insight into the internal workings of LLMs' instruction-following, paving the way for reliable LLM agents.
Do LLMs estimate uncertainty well in instruction-following?
Oct 18, 2024
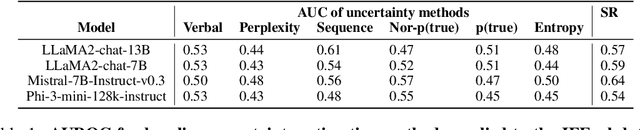
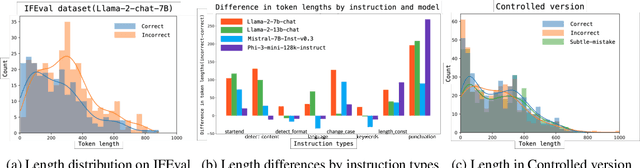

Large language models (LLMs) could be valuable personal AI agents across various domains, provided they can precisely follow user instructions. However, recent studies have shown significant limitations in LLMs' instruction-following capabilities, raising concerns about their reliability in high-stakes applications. Accurately estimating LLMs' uncertainty in adhering to instructions is critical to mitigating deployment risks. We present, to our knowledge, the first systematic evaluation of the uncertainty estimation abilities of LLMs in the context of instruction-following. Our study identifies key challenges with existing instruction-following benchmarks, where multiple factors are entangled with uncertainty stems from instruction-following, complicating the isolation and comparison across methods and models. To address these issues, we introduce a controlled evaluation setup with two benchmark versions of data, enabling a comprehensive comparison of uncertainty estimation methods under various conditions. Our findings show that existing uncertainty methods struggle, particularly when models make subtle errors in instruction following. While internal model states provide some improvement, they remain inadequate in more complex scenarios. The insights from our controlled evaluation setups provide a crucial understanding of LLMs' limitations and potential for uncertainty estimation in instruction-following tasks, paving the way for more trustworthy AI agents.
Characterization and Greedy Learning of Gaussian Structural Causal Models under Unknown Interventions
Dec 22, 2022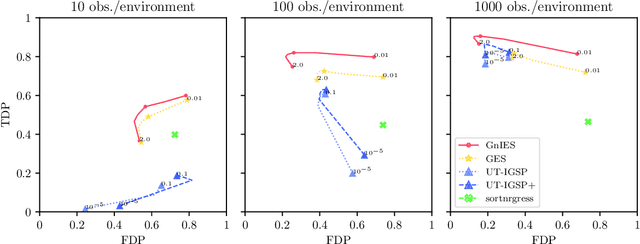


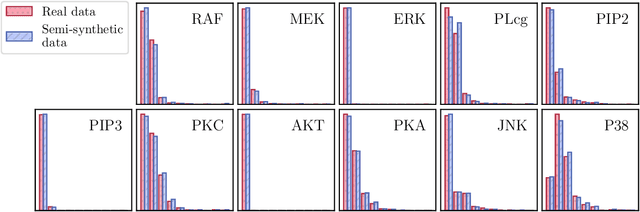
We consider the problem of recovering the causal structure underlying observations from different experimental conditions when the targets of the interventions in each experiment are unknown. We assume a linear structural causal model with additive Gaussian noise and consider interventions that perturb their targets while maintaining the causal relationships in the system. Different models may entail the same distributions, offering competing causal explanations for the given observations. We fully characterize this equivalence class and offer identifiability results, which we use to derive a greedy algorithm called GnIES to recover the equivalence class of the data-generating model without knowledge of the intervention targets. In addition, we develop a novel procedure to generate semi-synthetic data sets with known causal ground truth but distributions closely resembling those of a real data set of choice. We leverage this procedure and evaluate the performance of GnIES on synthetic, real, and semi-synthetic data sets. Despite the strong Gaussian distributional assumption, GnIES is robust to an array of model violations and competitive in recovering the causal structure in small- to large-sample settings. We provide, in the Python packages "gnies" and "sempler", implementations of GnIES and our semi-synthetic data generation procedure.
Think before you act: A simple baseline for compositional generalization
Oct 01, 2020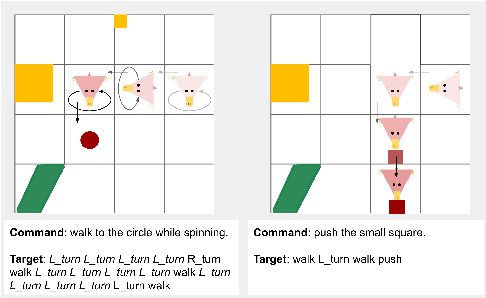



Contrarily to humans who have the ability to recombine familiar expressions to create novel ones, modern neural networks struggle to do so. This has been emphasized recently with the introduction of the benchmark dataset "gSCAN" (Ruis et al. 2020), aiming to evaluate models' performance at compositional generalization in grounded language understanding. In this work, we challenge the gSCAN benchmark by proposing a simple model that achieves surprisingly good performance on two of the gSCAN test splits. Our model is based on the observation that, to succeed on gSCAN tasks, the agent must (i) identify the target object (think) before (ii) navigating to it successfully (act). Concretely, we propose an attention-inspired modification of the baseline model from (Ruis et al. 2020), together with an auxiliary loss, that takes into account the sequential nature of steps (i) and (ii). While two compositional tasks are trivially solved with our approach, we also find that the other tasks remain unsolved, validating the relevance of gSCAN as a benchmark for evaluating models' compositional abilities.
Active Invariant Causal Prediction: Experiment Selection through Stability
Jun 10, 2020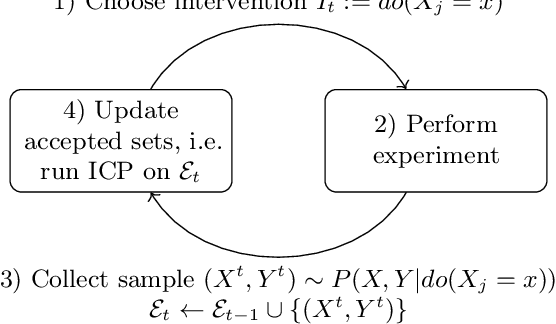
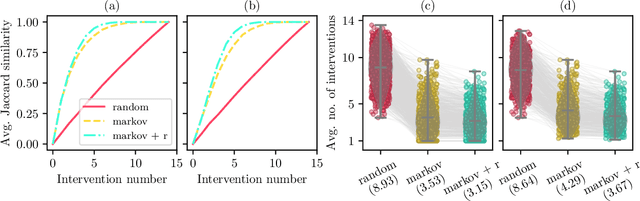

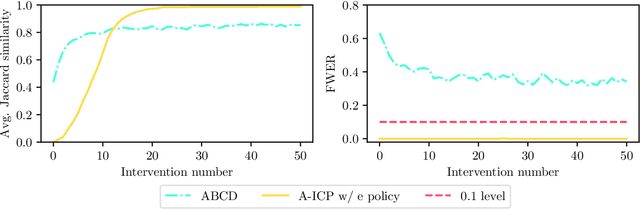
A fundamental difficulty of causal learning is that causal models can generally not be fully identified based on observational data only. Interventional data, that is, data originating from different experimental environments, improves identifiability. However, the improvement depends critically on the target and nature of the interventions carried out in each experiment. Since in real applications experiments tend to be costly, there is a need to perform the right interventions such that as few as possible are required. In this work we propose a new active learning (i.e. experiment selection) framework (A-ICP) based on Invariant Causal Prediction (ICP) (Peters et al., 2016). For general structural causal models, we characterize the effect of interventions on so-called stable sets, a notion introduced by (Pfister et al., 2019). We leverage these results to propose several intervention selection policies for A-ICP which quickly reveal the direct causes of a response variable in the causal graph while maintaining the error control inherent in ICP. Empirically, we analyze the performance of the proposed policies in both population and finite-regime experiments.
Invariance-inducing regularization using worst-case transformations suffices to boost accuracy and spatial robustness
Jun 26, 2019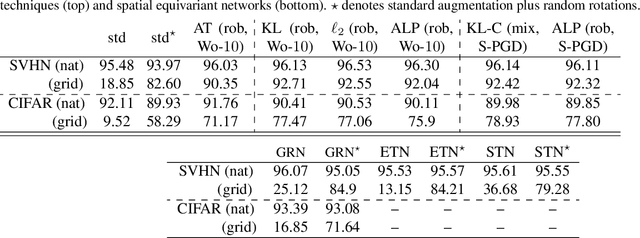

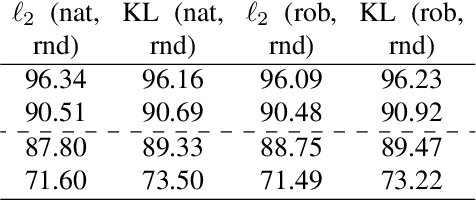
This work provides theoretical and empirical evidence that invariance-inducing regularizers can increase predictive accuracy for worst-case spatial transformations (spatial robustness). Evaluated on these adversarially transformed examples, we demonstrate that adding regularization on top of standard or adversarial training reduces the relative error by 20% for CIFAR10 without increasing the computational cost. This outperforms handcrafted networks that were explicitly designed to be spatial-equivariant. Furthermore, we observe for SVHN, known to have inherent variance in orientation, that robust training also improves standard accuracy on the test set. We prove that this no-trade-off phenomenon holds for adversarial examples from transformation groups in the infinite data limit.
Conditional Variance Penalties and Domain Shift Robustness
May 08, 2018
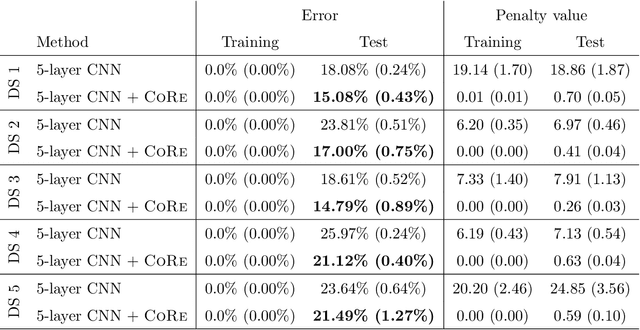


When training a deep network for image classification, one can broadly distinguish between two types of latent features of images that will drive the classification. Following the notation of Gong et al. (2016), we can divide latent features into (i) "core" features $X^\text{core}$ whose distribution $X^\text{core}\vert Y$ does not change substantially across domains and (ii) "style" features $X^{\text{style}}$ whose distribution $X^{\text{style}}\vert Y$ can change substantially across domains. These latter orthogonal features would generally include features such as rotation, image quality or brightness but also more complex ones like hair color or posture for images of persons. Guarding against future adversarial domain shifts implies that the influence of the second type of style features in the prediction has to be limited. We assume that the domain itself is not observed and hence a latent variable. We do assume, however, that we can sometimes observe a typically discrete identifier or $\mathrm{ID}$ variable. We know in some applications, for example, that two images show the same person, and $\mathrm{ID}$ then refers to the identity of the person. The method requires only a small fraction of images to have an $\mathrm{ID}$ variable. We group data samples if they share the same class and identifier $(Y,\mathrm{ID})=(y,\mathrm{id})$ and penalize the conditional variance of the prediction if we condition on $(Y,\mathrm{ID})$. Using this approach is shown to protect against shifts in the distribution of the style variables for both regression and classification models. Specifically, the conditional variance penalty CoRe is shown to be equivalent to minimizing the risk under noise interventions in a regression setting and is shown to lead to adversarial risk consistency in a partially linear classification setting.