 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Useful is Causal Invariance for Domain Adaptation in Finite-Sample Settings?
Jun 10, 2026Machine learning models often degrade when they are deployed on a target distribution that differs from the source distributions they were trained on. Recent work in causality-based domain generalization has shown how shared causal structure between domains can induce invariant predictors, e.g., models on a subset of features which have stable risk across structured domain shifts. However, the extent to which such population-level causal invariances can lead to gains in finite-sample settings remains underexplored. In particular, in practice we often have access to a few labeled target samples, a setting called supervised domain adaptation (sDA). In this paper, we explore when (full or partial) causal knowledge can provably improve supervised domain adaptation. As a first step, we study linear regression, where full or partial causal knowledge specifies a collection of invariant or possibly invariant feature subsets, each yielding a source-trained candidate predictor. We derive matching upper and lower bounds showing that finite-sample gains are governed by the target-risk margins separating the candidates, together with the finite-source estimation error. When these margins are sufficiently large relative to $n_Q$, an adaptive aggregation procedure can match the best candidate predictor while avoiding negative transfer relative to target-only learning. On the other hand, when the margins are too small, no algorithm can reliably exploit the candidate collection to obtain faster finite-sample rates. We further connect these margins to structural shift magnitude in linear SCMs and validate the theory on real-world causal benchmarks.
Cutting LLM Evaluation Costs with SySRs: A Bandit Algorithm that Provably Exploits Model Similarity
Jun 05, 2026Large Language Models are typically benchmarked by evaluating every model on every test query. For practitioners seeking the best model to deploy, this is often wasteful: if a model clearly performs worse than others, there is no need to precisely estimate its performance. Best-arm identification algorithms can be naturally applied to drastically reduce costs by adaptively allocating evaluation budget. Further, language models often respond similarly to the same prompt-a property previous work has tried to leverage with mixed success. We propose Synchronized Successive Rejects (SySRs), augmenting the classical Successive Rejects algorithm with paired comparisons. Unlike prior attempts to leverage model similarity in best-model identification, our approach is hyperparameter-free and enjoys performance guarantees that improve with the degree of similarity between evaluated models. Empirically, our method outperforms all baselines in terms of average error rate across 15 standard benchmarks, and in terms of worst-case budget for reliably identifying the best model.
Fast Unlearning at Scale via Margin Self-Correction
Jun 01, 2026Language-model unlearning updates a trained model to behave as if it had not seen selected training examples, while preserving utility and avoiding costly retraining. Existing approaches typically fine-tune the pretrained model with a fixed training budget and select the final model afterwards by evaluating several saved checkpoints on downstream validation data. Two sources of unnecessary computation limit scalability: training beyond the desired forget-retain trade-off, and checkpoint selection that requires extra storage and repeated evaluations. To address these limitations, we introduce MArgin Self-Correction (MASC), an efficient unlearning method with an online stopping rule that does not require downstream evaluation. Given a text sequence to be forgotten, MASC actively reduces the logit gap between the original next token and the most likely alternatives. It outputs a final model once this gap is small on average over a sufficiently large proportion of token positions across all forget sequences. On TOFU, MUSE News, and MUSE Books, MASC achieves a competitive forget-retain trade-off at a fraction of the computational cost of existing baselines. We further observe that as we increase model size (a.k.a. number of parameters), the trade-offs improve for both MASC and SimNPO -- the forget metrics remain comparable while retain utility increases.
Hedging on the Frontier: Learning New Tasks with Few Samples
May 29, 2026When a learner faces a new task with few samples, it must leverage any available side information. In practice, this often comes in the form of model evaluations on related tasks in public benchmarks. A key question then is how to model task relatedness such that it is both realistic and the benchmark evaluations lead to provable gains. Empirically, we observe that weak monotonicity is often approximately satisfied: if a model dominates another on many benchmarks, it also tends to outperform on the new task. We explore the statistical complexity of learning under (approximate) weak monotonicity, leveraging it within two learning paradigms: transfer learning and model selection aggregation. We show that not only can we prune the model class based on monotonicity, but we can also further adapt to the geometry of the available trade-offs by hedging on the frontier.
WavFlow: Audio Generation in Waveform Space
May 18, 2026Modern audio generation predominantly relies on latent-space compression, introducing additional complexity and potential information loss. In this work, we challenge this paradigm with WavFlow, a framework that generates high-fidelity audio directly in raw waveform space without intermediate representations. To overcome the inherent difficulties of modeling high-dimensional and low-energy signals, we reshape audio into 2D token grids through waveform patchify and introduce amplitude lifting to align signal scales, enabling stable optimization via direct x-prediction in flow matching. To capture complex semantic alignment and temporal synchronization, we leverage an automated data pipeline to curate 5 million high-quality video-text-audio triplets, allowing the model to learn fine-grained acoustic patterns from scratch. Experimental results show that WavFlow achieves competitive performance on the video-to-audio benchmark VGGSound (FD_PaSST: 59.98, IS_PANNs: 17.40, DeSync: 0.44) and the text-to-audio benchmark AudioCaps (FD_PANNs: 10.63, IS_PANNs: 12.62), matching or exceeding the performance of established latent-based methods. Our work demonstrates that intermediate compression is not a prerequisite for high-quality synthesis, offering a simpler and more scalable alternative for multimodal audio generation.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
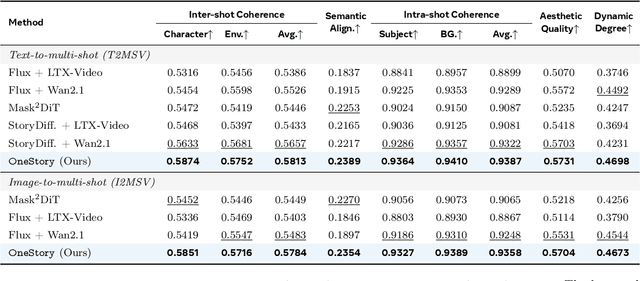
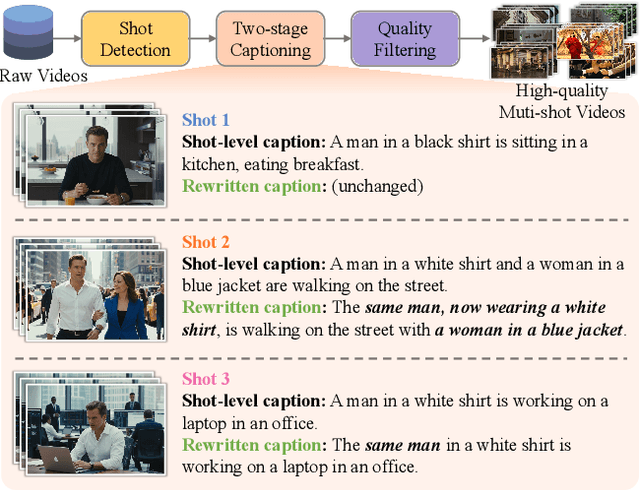

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
On the sample complexity of semi-supervised multi-objective learning
Aug 23, 2025In multi-objective learning (MOL), several possibly competing prediction tasks must be solved jointly by a single model. Achieving good trade-offs may require a model class $\mathcal{G}$ with larger capacity than what is necessary for solving the individual tasks. This, in turn, increases the statistical cost, as reflected in known MOL bounds that depend on the complexity of $\mathcal{G}$. We show that this cost is unavoidable for some losses, even in an idealized semi-supervised setting, where the learner has access to the Bayes-optimal solutions for the individual tasks as well as the marginal distributions over the covariates. On the other hand, for objectives defined with Bregman losses, we prove that the complexity of $\mathcal{G}$ may come into play only in terms of unlabeled data. Concretely, we establish sample complexity upper bounds, showing precisely when and how unlabeled data can significantly alleviate the need for labeled data. These rates are achieved by a simple, semi-supervised algorithm via pseudo-labeling.
ROC-n-reroll: How verifier imperfection affects test-time scaling
Jul 16, 2025Test-time scaling aims to improve language model performance by leveraging additional compute during inference. While many works have empirically studied techniques like Best-of-N (BoN) and rejection sampling that make use of a verifier to enable test-time scaling, there is little theoretical understanding of how verifier imperfection affects performance. In this work, we address this gap. Specifically, we prove how instance-level accuracy of these methods is precisely characterized by the geometry of the verifier's ROC curve. Interestingly, while scaling is determined by the local geometry of the ROC curve for rejection sampling, it depends on global properties of the ROC curve for BoN. As a consequence when the ROC curve is unknown, it is impossible to extrapolate the performance of rejection sampling based on the low-compute regime. Furthermore, while rejection sampling outperforms BoN for fixed compute, in the infinite-compute limit both methods converge to the same level of accuracy, determined by the slope of the ROC curve near the origin. Our theoretical results are confirmed by experiments on GSM8K using different versions of Llama and Qwen to generate and verify solutions.
Doubly robust identification of treatment effects from multiple environments
Mar 18, 2025Practical and ethical constraints often require the use of observational data for causal inference, particularly in medicine and social sciences. Yet, observational datasets are prone to confounding, potentially compromising the validity of causal conclusions. While it is possible to correct for biases if the underlying causal graph is known, this is rarely a feasible ask in practical scenarios. A common strategy is to adjust for all available covariates, yet this approach can yield biased treatment effect estimates, especially when post-treatment or unobserved variables are present. We propose RAMEN, an algorithm that produces unbiased treatment effect estimates by leveraging the heterogeneity of multiple data sources without the need to know or learn the underlying causal graph. Notably, RAMEN achieves doubly robust identification: it can identify the treatment effect whenever the causal parents of the treatment or those of the outcome are observed, and the node whose parents are observed satisfies an invariance assumption. Empirical evaluations on synthetic and real-world datasets show that our approach outperforms existing methods.
Learning Pareto manifolds in high dimensions: How can regularization help?
Mar 11, 2025Simultaneously addressing multiple objectives is becoming increasingly important in modern machine learning. At the same time, data is often high-dimensional and costly to label. For a single objective such as prediction risk, conventional regularization techniques are known to improve generalization when the data exhibits low-dimensional structure like sparsity. However, it is largely unexplored how to leverage this structure in the context of multi-objective learning (MOL) with multiple competing objectives. In this work, we discuss how the application of vanilla regularization approaches can fail, and propose a two-stage MOL framework that can successfully leverage low-dimensional structure. We demonstrate its effectiveness experimentally for multi-distribution learning and fairness-risk trade-offs.