 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Autoencoders are Capable LLM Jailbreak Mitigators
Feb 12, 2026Jailbreak attacks remain a persistent threat to large language model safety. We propose Context-Conditioned Delta Steering (CC-Delta), an SAE-based defense that identifies jailbreak-relevant sparse features by comparing token-level representations of the same harmful request with and without jailbreak context. Using paired harmful/jailbreak prompts, CC-Delta selects features via statistical testing and applies inference-time mean-shift steering in SAE latent space. Across four aligned instruction-tuned models and twelve jailbreak attacks, CC-Delta achieves comparable or better safety-utility tradeoffs than baseline defenses operating in dense latent space. In particular, our method clearly outperforms dense mean-shift steering on all four models, and particularly against out-of-distribution attacks, showing that steering in sparse SAE feature space offers advantages over steering in dense activation space for jailbreak mitigation. Our results suggest off-the-shelf SAEs trained for interpretability can be repurposed as practical jailbreak defenses without task-specific training.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Doubly robust identification of treatment effects from multiple environments
Mar 18, 2025Practical and ethical constraints often require the use of observational data for causal inference, particularly in medicine and social sciences. Yet, observational datasets are prone to confounding, potentially compromising the validity of causal conclusions. While it is possible to correct for biases if the underlying causal graph is known, this is rarely a feasible ask in practical scenarios. A common strategy is to adjust for all available covariates, yet this approach can yield biased treatment effect estimates, especially when post-treatment or unobserved variables are present. We propose RAMEN, an algorithm that produces unbiased treatment effect estimates by leveraging the heterogeneity of multiple data sources without the need to know or learn the underlying causal graph. Notably, RAMEN achieves doubly robust identification: it can identify the treatment effect whenever the causal parents of the treatment or those of the outcome are observed, and the node whose parents are observed satisfies an invariance assumption. Empirical evaluations on synthetic and real-world datasets show that our approach outperforms existing methods.
Efficient Randomized Experiments Using Foundation Models
Feb 06, 2025



Randomized experiments are the preferred approach for evaluating the effects of interventions, but they are costly and often yield estimates with substantial uncertainty. On the other hand, in silico experiments leveraging foundation models offer a cost-effective alternative that can potentially attain higher statistical precision. However, the benefits of in silico experiments come with a significant risk: statistical inferences are not valid if the models fail to accurately predict experimental responses to interventions. In this paper, we propose a novel approach that integrates the predictions from multiple foundation models with experimental data while preserving valid statistical inference. Our estimator is consistent and asymptotically normal, with asymptotic variance no larger than the standard estimator based on experimental data alone. Importantly, these statistical properties hold even when model predictions are arbitrarily biased. Empirical results across several randomized experiments show that our estimator offers substantial precision gains, equivalent to a reduction of up to 20% in the sample size needed to match the same precision as the standard estimator based on experimental data alone.
Copyright-Protected Language Generation via Adaptive Model Fusion
Dec 09, 2024The risk of language models reproducing copyrighted material from their training data has led to the development of various protective measures. Among these, inference-time strategies that impose constraints via post-processing have shown promise in addressing the complexities of copyright regulation. However, they often incur prohibitive computational costs or suffer from performance trade-offs. To overcome these limitations, we introduce Copyright-Protecting Model Fusion (CP-Fuse), a novel approach that combines models trained on disjoint sets of copyrighted material during inference. In particular, CP-Fuse adaptively aggregates the model outputs to minimize the reproduction of copyrighted content, adhering to a crucial balancing property that prevents the regurgitation of memorized data. Through extensive experiments, we show that CP-Fuse significantly reduces the reproduction of protected material without compromising the quality of text and code generation. Moreover, its post-hoc nature allows seamless integration with other protective measures, further enhancing copyright safeguards. Lastly, we show that CP-Fuse is robust against common techniques for extracting training data.
Strong Copyright Protection for Language Models via Adaptive Model Fusion
Jul 29, 2024The risk of language models unintentionally reproducing copyrighted material from their training data has led to the development of various protective measures. In this paper, we propose model fusion as an effective solution to safeguard against copyright infringement. In particular, we introduce Copyright-Protecting Fusion (CP-Fuse), an algorithm that adaptively combines language models to minimize the reproduction of protected materials. CP-Fuse is inspired by the recently proposed Near-Access Free (NAF) framework and additionally incorporates a desirable balancing property that we demonstrate prevents the reproduction of memorized training data. Our results show that CP-Fuse significantly reduces the memorization of copyrighted content while maintaining high-quality text and code generation. Furthermore, we demonstrate how CP-Fuse can be integrated with other techniques for enhanced protection.
Detecting critical treatment effect bias in small subgroups
Apr 29, 2024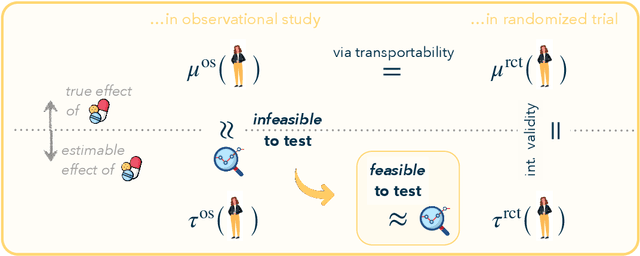

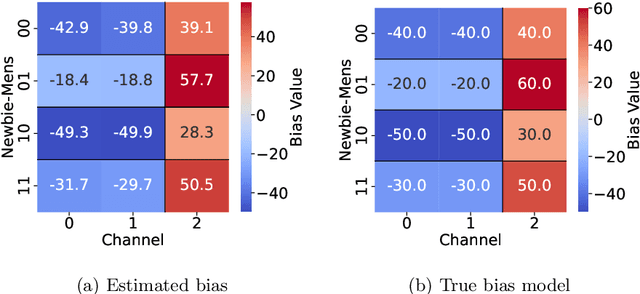

Randomized trials are considered the gold standard for making informed decisions in medicine, yet they often lack generalizability to the patient populations in clinical practice. Observational studies, on the other hand, cover a broader patient population but are prone to various biases. Thus, before using an observational study for decision-making, it is crucial to benchmark its treatment effect estimates against those derived from a randomized trial. We propose a novel strategy to benchmark observational studies beyond the average treatment effect. First, we design a statistical test for the null hypothesis that the treatment effects estimated from the two studies, conditioned on a set of relevant features, differ up to some tolerance. We then estimate an asymptotically valid lower bound on the maximum bias strength for any subgroup in the observational study. Finally, we validate our benchmarking strategy in a real-world setting and show that it leads to conclusions that align with established medical knowledge.
Privacy-preserving data release leveraging optimal transport and particle gradient descent
Jan 31, 2024



We present a novel approach for differentially private data synthesis of protected tabular datasets, a relevant task in highly sensitive domains such as healthcare and government. Current state-of-the-art methods predominantly use marginal-based approaches, where a dataset is generated from private estimates of the marginals. In this paper, we introduce PrivPGD, a new generation method for marginal-based private data synthesis, leveraging tools from optimal transport and particle gradient descent. Our algorithm outperforms existing methods on a large range of datasets while being highly scalable and offering the flexibility to incorporate additional domain-specific constraints.
Hidden yet quantifiable: A lower bound for confounding strength using randomized trials
Dec 06, 2023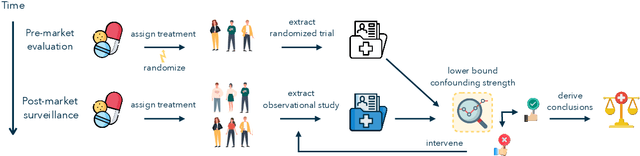
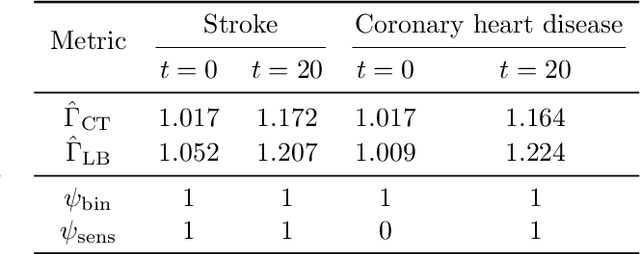
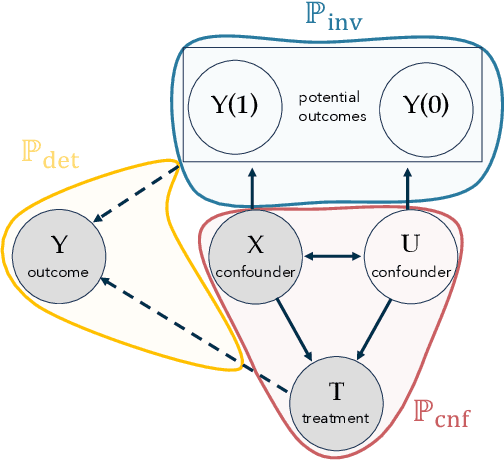
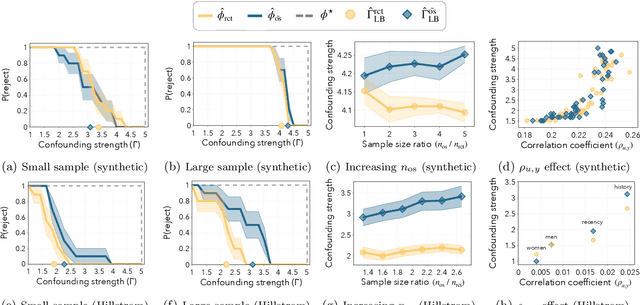
In the era of fast-paced precision medicine, observational studies play a major role in properly evaluating new treatments in clinical practice. Yet, unobserved confounding can significantly compromise causal conclusions drawn from non-randomized data. We propose a novel strategy that leverages randomized trials to quantify unobserved confounding. First, we design a statistical test to detect unobserved confounding with strength above a given threshold. Then, we use the test to estimate an asymptotically valid lower bound on the unobserved confounding strength. We evaluate the power and validity of our statistical test on several synthetic and semi-synthetic datasets. Further, we show how our lower bound can correctly identify the absence and presence of unobserved confounding in a real-world setting.