 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Free Generative Editing from One Visual Example
Mar 26, 2026Text-guided diffusion models have advanced image editing by enabling intuitive control through language. However, despite their strong capabilities, we surprisingly find that SOTA methods struggle with simple, everyday transformations such as rain or blur. We attribute this limitation to weak and inconsistent textual supervision during training, which leads to poor alignment between language and vision. Existing solutions often rely on extra finetuning or stronger text conditioning, but suffer from high data and computational requirements. We argue that diffusion-based editing capabilities aren't lost but merely hidden from text. The door to cost-efficient visual editing remains open, and the key lies in a vision-centric paradigm that perceives and reasons about visual change as humans do, beyond words. Inspired by this, we introduce Visual Diffusion Conditioning (VDC), a training-free framework that learns conditioning signals directly from visual examples for precise, language-free image editing. Given a paired example -one image with and one without the target effect- VDC derives a visual condition that captures the transformation and steers generation through a novel condition-steering mechanism. An accompanying inversion-correction step mitigates reconstruction errors during DDIM inversion, preserving fine detail and realism. Across diverse tasks, VDC outperforms both training-free and fully fine-tuned text-based editing methods. The code and models are open-sourced at https://omaralezaby.github.io/vdc/
Video Understanding: From Geometry and Semantics to Unified Models
Mar 18, 2026Video understanding aims to enable models to perceive, reason about, and interact with the dynamic visual world. In contrast to image understanding, video understanding inherently requires modeling temporal dynamics and evolving visual context, placing stronger demands on spatiotemporal reasoning and making it a foundational problem in computer vision. In this survey, we present a structured overview of video understanding by organizing the literature into three complementary perspectives: low-level video geometry understanding, high-level semantic understanding, and unified video understanding models. We further highlight a broader shift from isolated, task-specific pipelines toward unified modeling paradigms that can be adapted to diverse downstream objectives, enabling a more systematic view of recent progress. By consolidating these perspectives, this survey provides a coherent map of the evolving video understanding landscape, summarizes key modeling trends and design principles, and outlines open challenges toward building robust, scalable, and unified video foundation models.
* A comprehensive survey of video understanding, spanning low-level geometry, high-level semantics, and unified understanding models
DiTVR: Zero-Shot Diffusion Transformer for Video Restoration
Aug 11, 2025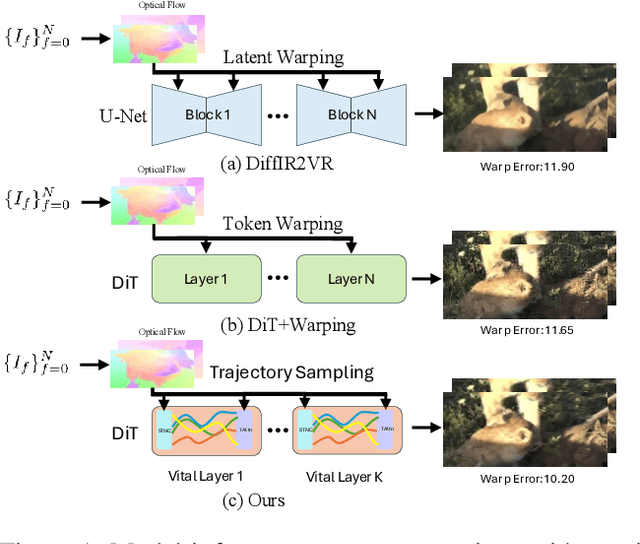


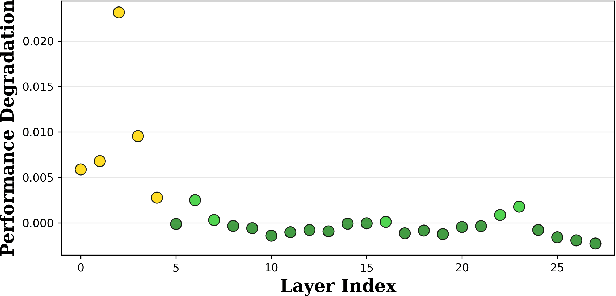
Video restoration aims to reconstruct high quality video sequences from low quality inputs, addressing tasks such as super resolution, denoising, and deblurring. Traditional regression based methods often produce unrealistic details and require extensive paired datasets, while recent generative diffusion models face challenges in ensuring temporal consistency. We introduce DiTVR, a zero shot video restoration framework that couples a diffusion transformer with trajectory aware attention and a wavelet guided, flow consistent sampler. Unlike prior 3D convolutional or frame wise diffusion approaches, our attention mechanism aligns tokens along optical flow trajectories, with particular emphasis on vital layers that exhibit the highest sensitivity to temporal dynamics. A spatiotemporal neighbour cache dynamically selects relevant tokens based on motion correspondences across frames. The flow guided sampler injects data consistency only into low-frequency bands, preserving high frequency priors while accelerating convergence. DiTVR establishes a new zero shot state of the art on video restoration benchmarks, demonstrating superior temporal consistency and detail preservation while remaining robust to flow noise and occlusions.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
LeMoRe: Learn More Details for Lightweight Semantic Segmentation
May 29, 2025



Lightweight semantic segmentation is essential for many downstream vision tasks. Unfortunately, existing methods often struggle to balance efficiency and performance due to the complexity of feature modeling. Many of these existing approaches are constrained by rigid architectures and implicit representation learning, often characterized by parameter-heavy designs and a reliance on computationally intensive Vision Transformer-based frameworks. In this work, we introduce an efficient paradigm by synergizing explicit and implicit modeling to balance computational efficiency with representational fidelity. Our method combines well-defined Cartesian directions with explicitly modeled views and implicitly inferred intermediate representations, efficiently capturing global dependencies through a nested attention mechanism. Extensive experiments on challenging datasets, including ADE20K, CityScapes, Pascal Context, and COCO-Stuff, demonstrate that LeMoRe strikes an effective balance between performance and efficiency.
NTIRE 2025 Challenge on Video Quality Enhancement for Video Conferencing: Datasets, Methods and Results
May 25, 2025This paper presents a comprehensive review of the 1st Challenge on Video Quality Enhancement for Video Conferencing held at the NTIRE workshop at CVPR 2025, and highlights the problem statement, datasets, proposed solutions, and results. The aim of this challenge was to design a Video Quality Enhancement (VQE) model to enhance video quality in video conferencing scenarios by (a) improving lighting, (b) enhancing colors, (c) reducing noise, and (d) enhancing sharpness - giving a professional studio-like effect. Participants were given a differentiable Video Quality Assessment (VQA) model, training, and test videos. A total of 91 participants registered for the challenge. We received 10 valid submissions that were evaluated in a crowdsourced framework.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025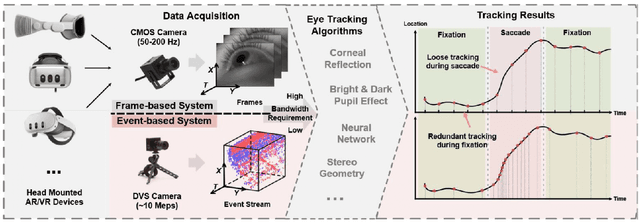
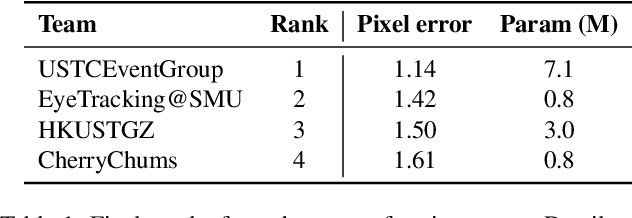

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Any Image Restoration via Efficient Spatial-Frequency Degradation Adaptation
Apr 19, 2025



Restoring any degraded image efficiently via just one model has become increasingly significant and impactful, especially with the proliferation of mobile devices. Traditional solutions typically involve training dedicated models per degradation, resulting in inefficiency and redundancy. More recent approaches either introduce additional modules to learn visual prompts, significantly increasing model size, or incorporate cross-modal transfer from large language models trained on vast datasets, adding complexity to the system architecture. In contrast, our approach, termed AnyIR, takes a unified path that leverages inherent similarity across various degradations to enable both efficient and comprehensive restoration through a joint embedding mechanism, without scaling up the model or relying on large language models.Specifically, we examine the sub-latent space of each input, identifying key components and reweighting them first in a gated manner. To fuse the intrinsic degradation awareness and the contextualized attention, a spatial-frequency parallel fusion strategy is proposed for enhancing spatial-aware local-global interactions and enriching the restoration details from the frequency perspective. Extensive benchmarking in the all-in-one restoration setting confirms AnyIR's SOTA performance, reducing model complexity by around 82\% in parameters and 85\% in FLOPs. Our code will be available at our Project page (https://amazingren.github.io/AnyIR/)