 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Video Quality Enhancement for Video Conferencing: Datasets, Methods and Results
May 25, 2025This paper presents a comprehensive review of the 1st Challenge on Video Quality Enhancement for Video Conferencing held at the NTIRE workshop at CVPR 2025, and highlights the problem statement, datasets, proposed solutions, and results. The aim of this challenge was to design a Video Quality Enhancement (VQE) model to enhance video quality in video conferencing scenarios by (a) improving lighting, (b) enhancing colors, (c) reducing noise, and (d) enhancing sharpness - giving a professional studio-like effect. Participants were given a differentiable Video Quality Assessment (VQA) model, training, and test videos. A total of 91 participants registered for the challenge. We received 10 valid submissions that were evaluated in a crowdsourced framework.
Memory Guided Road Detection
Jun 27, 2021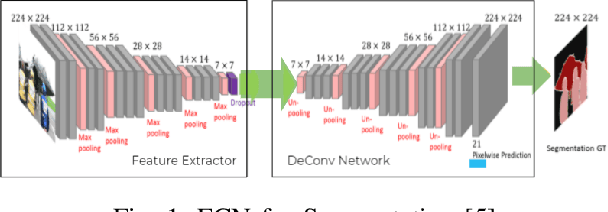


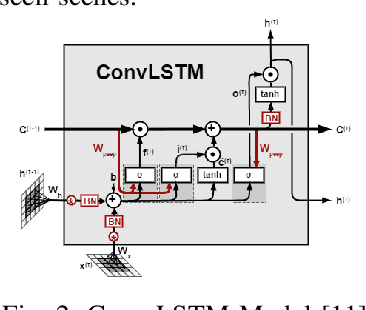
In self driving car applications, there is a requirement to predict the location of the lane given an input RGB front facing image. In this paper, we propose an architecture that allows us to increase the speed and robustness of road detection without a large hit in accuracy by introducing an underlying shared feature space that is propagated over time, which serves as a flowing dynamic memory. By utilizing the gist of previous frames, we train the network to predict the current road with a greater accuracy and lesser deviation from previous frames.
Synthetic Video Generation for Robust Hand Gesture Recognition in Augmented Reality Applications
Dec 06, 2019



Hand gestures are a natural means of interaction in Augmented Reality and Virtual Reality (AR/VR) applications. Recently, there has been an increased focus on removing the dependence of accurate hand gesture recognition on complex sensor setup found in expensive proprietary devices such as the Microsoft HoloLens, Daqri and Meta Glasses. Most such solutions either rely on multi-modal sensor data or deep neural networks that can benefit greatly from abundance of labelled data. Datasets are an integral part of any deep learning based research. They have been the principal reason for the substantial progress in this field, both, in terms of providing enough data for the training of these models, and, for benchmarking competing algorithms. However, it is becoming increasingly difficult to generate enough labelled data for complex tasks such as hand gesture recognition. The goal of this work is to introduce a framework capable of generating photo-realistic videos that have labelled hand bounding box and fingertip that can help in designing, training, and benchmarking models for hand-gesture recognition in AR/VR applications. We demonstrate the efficacy of our framework in generating videos with diverse backgrounds.
Learning Key-Value Store Design
Jul 11, 2019



We introduce the concept of design continuums for the data layout of key-value stores. A design continuum unifies major distinct data structure designs under the same model. The critical insight and potential long-term impact is that such unifying models 1) render what we consider up to now as fundamentally different data structures to be seen as views of the very same overall design space, and 2) allow seeing new data structure designs with performance properties that are not feasible by existing designs. The core intuition behind the construction of design continuums is that all data structures arise from the very same set of fundamental design principles, i.e., a small set of data layout design concepts out of which we can synthesize any design that exists in the literature as well as new ones. We show how to construct, evaluate, and expand, design continuums and we also present the first continuum that unifies major data structure designs, i.e., B+tree, B-epsilon-tree, LSM-tree, and LSH-table. The practical benefit of a design continuum is that it creates a fast inference engine for the design of data structures. For example, we can predict near instantly how a specific design change in the underlying storage of a data system would affect performance, or reversely what would be the optimal data structure (from a given set of designs) given workload characteristics and a memory budget. In turn, these properties allow us to envision a new class of self-designing key-value stores with a substantially improved ability to adapt to workload and hardware changes by transitioning between drastically different data structure designs to assume a diverse set of performance properties at will.
GestARLite: An On-Device Pointing Finger Based Gestural Interface for Smartphones and Video See-Through Head-Mounts
Apr 19, 2019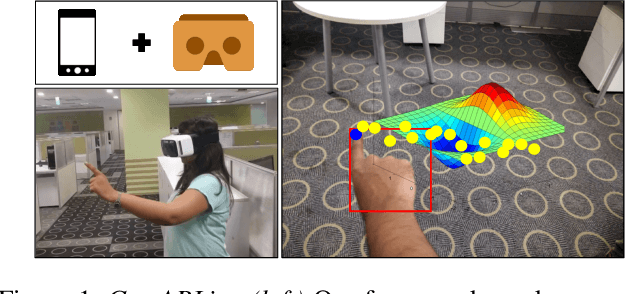
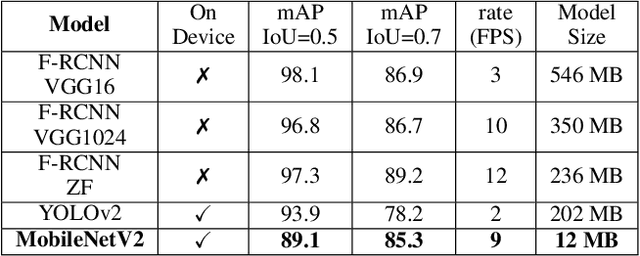
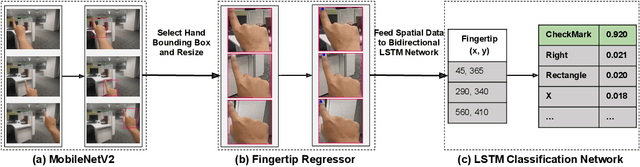
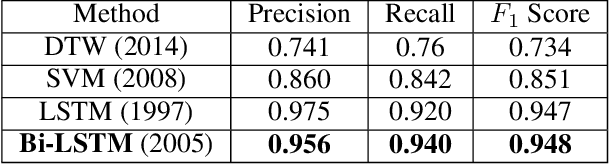
Hand gestures form an intuitive means of interaction in Mixed Reality (MR) applications. However, accurate gesture recognition can be achieved only through state-of-the-art deep learning models or with the use of expensive sensors. Despite the robustness of these deep learning models, they are generally computationally expensive and obtaining real-time performance on-device is still a challenge. To this end, we propose a novel lightweight hand gesture recognition framework that works in First Person View for wearable devices. The models are trained on a GPU machine and ported on an Android smartphone for its use with frugal wearable devices such as the Google Cardboard and VR Box. The proposed hand gesture recognition framework is driven by a cascade of state-of-the-art deep learning models: MobileNetV2 for hand localisation, our custom fingertip regression architecture followed by a Bi-LSTM model for gesture classification. We extensively evaluate the framework on our EgoGestAR dataset. The overall framework works in real-time on mobile devices and achieves a classification accuracy of 80% on EgoGestAR video dataset with an average latency of only 0.12 s.
sharpDARTS: Faster and More Accurate Differentiable Architecture Search
Mar 23, 2019
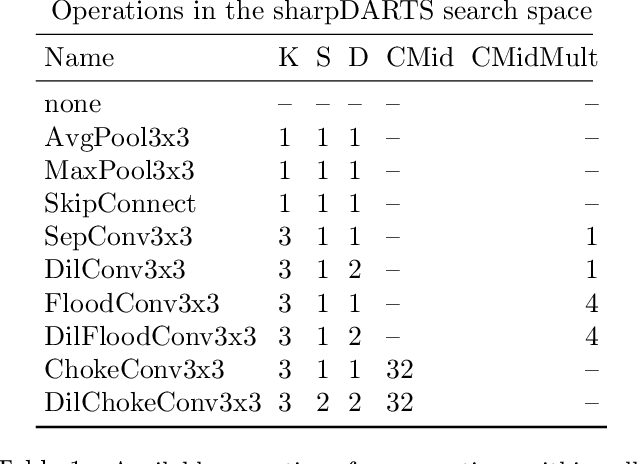
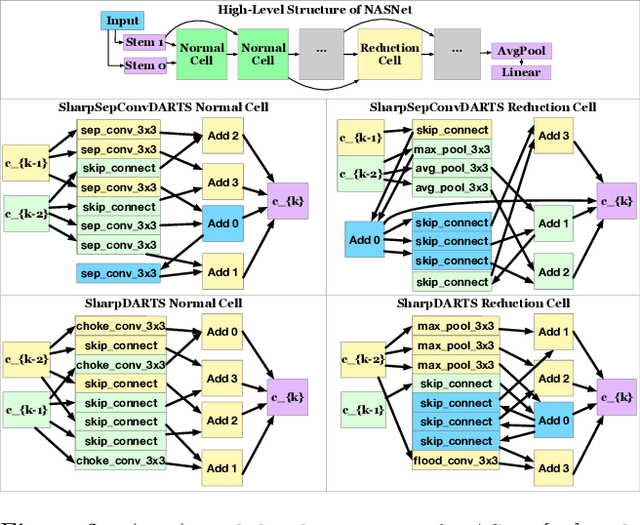
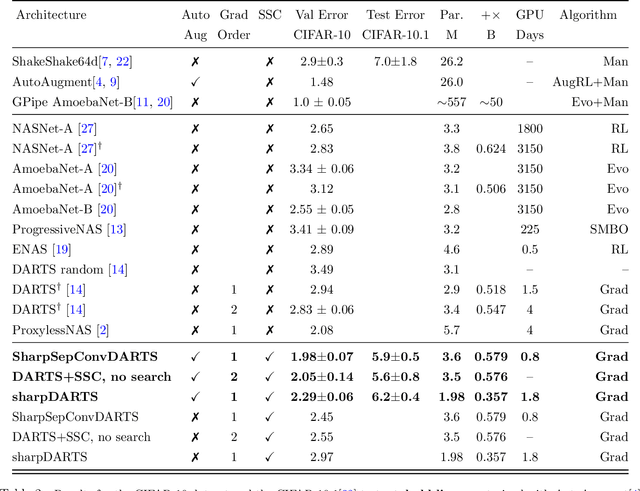
Neural Architecture Search (NAS) has been a source of dramatic improvements in neural network design, with recent results meeting or exceeding the performance of hand-tuned architectures. However, our understanding of how to represent the search space for neural net architectures and how to search that space efficiently are both still in their infancy. We have performed an in-depth analysis to identify limitations in a widely used search space and a recent architecture search method, Differentiable Architecture Search (DARTS). These findings led us to introduce novel network blocks with a more general, balanced, and consistent design; a better-optimized Cosine Power Annealing learning rate schedule; and other improvements. Our resulting sharpDARTS search is 50% faster with a 20-30% relative improvement in final model error on CIFAR-10 when compared to DARTS. Our best single model run has 1.93% (1.98+/-0.07) validation error on CIFAR-10 and 5.5% error (5.8+/-0.3) on the recently released CIFAR-10.1 test set. To our knowledge, both are state of the art for models of similar size. This model also generalizes competitively to ImageNet at 25.1% top-1 (7.8% top-5) error. We found improvements for existing search spaces but does DARTS generalize to new domains? We propose Differentiable Hyperparameter Grid Search and the HyperCuboid search space, which are representations designed to leverage DARTS for more general parameter optimization. Here we find that DARTS fails to generalize when compared against a human's one shot choice of models. We look back to the DARTS and sharpDARTS search spaces to understand why, and an ablation study reveals an unusual generalization gap. We finally propose Max-W regularization to solve this problem, which proves significantly better than the handmade design. Code will be made available.
The CoSTAR Block Stacking Dataset: Learning with Workspace Constraints
Mar 12, 2019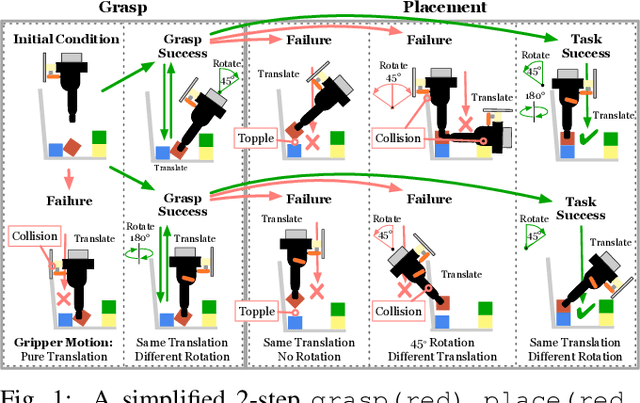

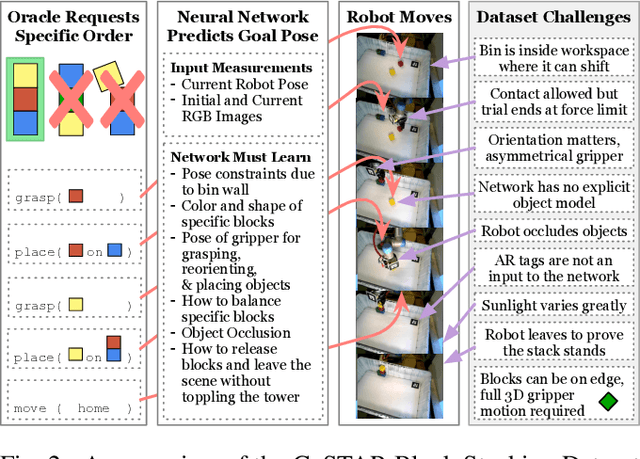

A robot can now grasp an object more effectively than ever before, but once it has the object what happens next? We show that a mild relaxation of the task and workspace constraints implicit in existing object grasping datasets can cause neural network based grasping algorithms to fail on even a simple block stacking task when executed under more realistic circumstances. To address this, we introduce the JHU CoSTAR Block Stacking Dataset (BSD), where a robot interacts with 5.1 cm colored blocks to complete an order-fulfillment style block stacking task. It contains dynamic scenes and real time-series data in a less constrained environment than comparable datasets. There are nearly 12,000 stacking attempts and over 2 million frames of real data. We discuss the ways in which this dataset provides a valuable resource for a broad range of other topics of investigation. We find that hand-designed neural networks that work on prior datasets do not generalize to this task. Thus, to establish a baseline for this dataset, we demonstrate an automated search of neural network based models using a novel multiple-input HyperTree MetaModel, and find a final model which makes reasonable 3D pose predictions for grasping and stacking on our dataset. The CoSTAR BSD, code, and instructions are available at https://sites.google.com/site/costardataset.