 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesharpDARTS: Faster and More Accurate Differentiable Architecture Search
Paper and Code
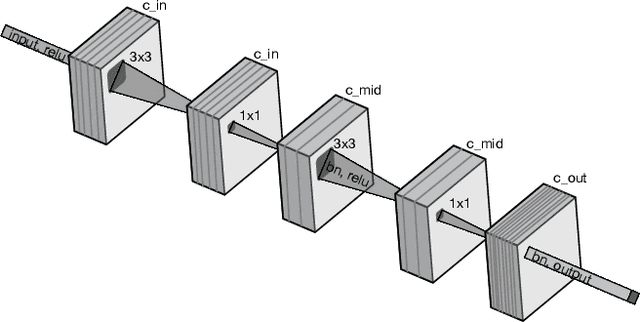
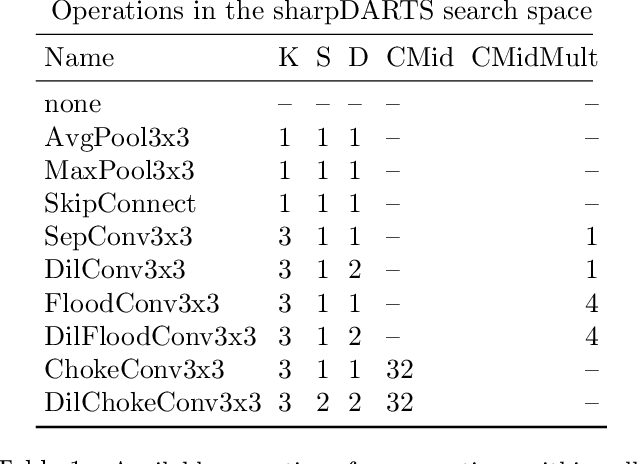
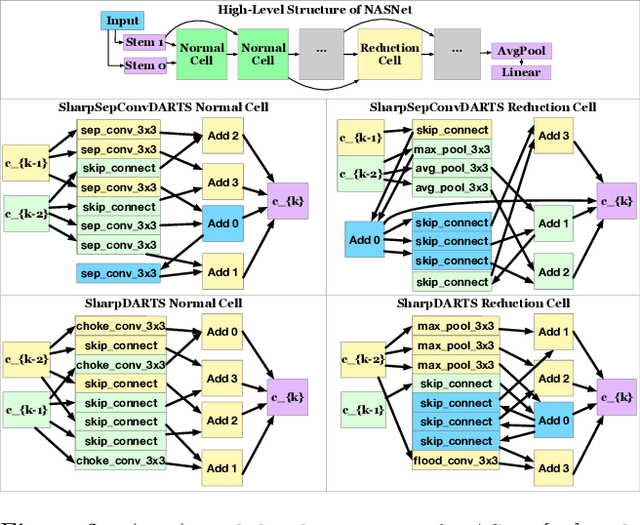
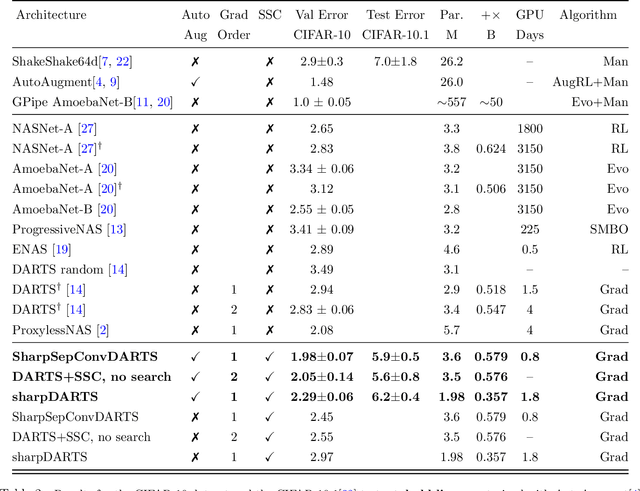
Neural Architecture Search (NAS) has been a source of dramatic improvements in neural network design, with recent results meeting or exceeding the performance of hand-tuned architectures. However, our understanding of how to represent the search space for neural net architectures and how to search that space efficiently are both still in their infancy. We have performed an in-depth analysis to identify limitations in a widely used search space and a recent architecture search method, Differentiable Architecture Search (DARTS). These findings led us to introduce novel network blocks with a more general, balanced, and consistent design; a better-optimized Cosine Power Annealing learning rate schedule; and other improvements. Our resulting sharpDARTS search is 50% faster with a 20-30% relative improvement in final model error on CIFAR-10 when compared to DARTS. Our best single model run has 1.93% (1.98+/-0.07) validation error on CIFAR-10 and 5.5% error (5.8+/-0.3) on the recently released CIFAR-10.1 test set. To our knowledge, both are state of the art for models of similar size. This model also generalizes competitively to ImageNet at 25.1% top-1 (7.8% top-5) error. We found improvements for existing search spaces but does DARTS generalize to new domains? We propose Differentiable Hyperparameter Grid Search and the HyperCuboid search space, which are representations designed to leverage DARTS for more general parameter optimization. Here we find that DARTS fails to generalize when compared against a human's one shot choice of models. We look back to the DARTS and sharpDARTS search spaces to understand why, and an ablation study reveals an unusual generalization gap. We finally propose Max-W regularization to solve this problem, which proves significantly better than the handmade design. Code will be made available.