 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinal Report, Center for Computer-Integrated Computer-Integrated Surgical Systems and Technology, NSF ERC Cooperative Agreement EEC9731748, Volume 1
Apr 07, 2026In the last ten years, medical robotics has moved from the margins to the mainstream. Since the Engineering Research Center for Computer-Integrated Surgical Systems and Technology was Launched in 1998 with National Science Foundation funding, medical robots have been promoted from handling routine tasks to performing highly sophisticated interventions and related assignments. The CISST ERC has played a significant role in this transformation. And thanks to NSF support, the ERC has built the professional infrastructure that will continue our mission: bringing data and technology together in clinical systems that will dramatically change how surgery and other procedures are done. The enhancements we envision touch virtually every aspect of the delivery of care: - More accurate procedures - More consistent, predictable results from one patient to the next - Improved clinical outcomes - Greater patient safety - Reduced liability for healthcare providers - Lower costs for everyone - patients, facilities, insurers, government - Easier, faster recovery for patients - Effective new ways to treat health problems - Healthier patients, and a healthier system The basic science and engineering the ERC is developing now will yield profound benefits for all concerned about health care - from government agencies to insurers, from clinicians to patients to the general public. All will experience the healing touch of medical robotics, thanks in no small part to the work of the CISST ERC and its successors.
Investigating a Policy-Based Formulation for Endoscopic Camera Pose Recovery
Mar 20, 2026In endoscopic surgery, surgeons continuously locate the endoscopic view relative to the anatomy by interpreting the evolving visual appearance of the intraoperative scene in the context of their prior knowledge. Vision-based navigation systems seek to replicate this capability by recovering camera pose directly from endoscopic video, but most approaches do not embody the same principles of reasoning about new frames that makes surgeons successful. Instead, they remain grounded in feature matching and geometric optimization over keyframes, an approach that has been shown to degrade under the challenging conditions of endoscopic imaging like low texture and rapid illumination changes. Here, we pursue an alternative approach and investigate a policy-based formulation of endoscopic camera pose recovery that seeks to imitate experts in estimating trajectories conditioned on the previous camera state. Our approach directly predicts short-horizon relative motions without maintaining an explicit geometric representation at inference time. It thus addresses, by design, some of the notorious challenges of geometry-based approaches, such as brittle correspondence matching, instability in texture-sparse regions, and limited pose coverage due to reconstruction failure. We evaluate the proposed formulation on cadaveric sinus endoscopy. Under oracle state conditioning, we compare short-horizon motion prediction quality to geometric baselines achieving lowest mean translation error and competitive rotational accuracy. We analyze robustness by grouping prediction windows according to texture richness and illumination change indicating reduced sensitivity to low-texture conditions. These findings suggest that a learned motion policy offers a viable alternative formulation for endoscopic camera pose recovery.
Domain Adaptation of Visual Policies with a Single Demonstration
Jul 23, 2024


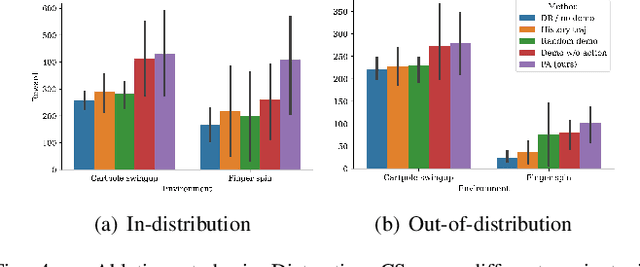
Deploying machine learning algorithms for robot tasks in real-world applications presents a core challenge: overcoming the domain gap between the training and the deployment environment. This is particularly difficult for visuomotor policies that utilize high-dimensional images as input, particularly when those images are generated via simulation. A common method to tackle this issue is through domain randomization, which aims to broaden the span of the training distribution to cover the test-time distribution. However, this approach is only effective when the domain randomization encompasses the actual shifts in the test-time distribution. We take a different approach, where we make use of a single demonstration (a prompt) to learn policy that adapts to the testing target environment. Our proposed framework, PromptAdapt, leverages the Transformer architecture's capacity to model sequential data to learn demonstration-conditioned visual policies, allowing for in-context adaptation to a target domain that is distinct from training. Our experiments in both simulation and real-world settings show that PromptAdapt is a strong domain-adapting policy that outperforms baseline methods by a large margin under a range of domain shifts, including variations in lighting, color, texture, and camera pose. Videos and more information can be viewed at project webpage: https://sites.google.com/view/promptadapt.
Adapting Image-based RL Policies via Predicted Rewards
Jul 23, 2024Image-based reinforcement learning (RL) faces significant challenges in generalization when the visual environment undergoes substantial changes between training and deployment. Under such circumstances, learned policies may not perform well leading to degraded results. Previous approaches to this problem have largely focused on broadening the training observation distribution, employing techniques like data augmentation and domain randomization. However, given the sequential nature of the RL decision-making problem, it is often the case that residual errors are propagated by the learned policy model and accumulate throughout the trajectory, resulting in highly degraded performance. In this paper, we leverage the observation that predicted rewards under domain shift, even though imperfect, can still be a useful signal to guide fine-tuning. We exploit this property to fine-tune a policy using reward prediction in the target domain. We have found that, even under significant domain shift, the predicted reward can still provide meaningful signal and fine-tuning substantially improves the original policy. Our approach, termed Predicted Reward Fine-tuning (PRFT), improves performance across diverse tasks in both simulated benchmarks and real-world experiments. More information is available at project web page: https://sites.google.com/view/prft.
VIHE: Virtual In-Hand Eye Transformer for 3D Robotic Manipulation
Mar 19, 2024In this work, we introduce the Virtual In-Hand Eye Transformer (VIHE), a novel method designed to enhance 3D manipulation capabilities through action-aware view rendering. VIHE autoregressively refines actions in multiple stages by conditioning on rendered views posed from action predictions in the earlier stages. These virtual in-hand views provide a strong inductive bias for effectively recognizing the correct pose for the hand, especially for challenging high-precision tasks such as peg insertion. On 18 manipulation tasks in RLBench simulated environments, VIHE achieves a new state-of-the-art, with a 12% absolute improvement, increasing from 65% to 77% over the existing state-of-the-art model using 100 demonstrations per task. In real-world scenarios, VIHE can learn manipulation tasks with just a handful of demonstrations, highlighting its practical utility. Videos and code implementation can be found at our project site: https://vihe-3d.github.io.
The Quiet Eye Phenomenon in Minimally Invasive Surgery
Sep 06, 2023In this paper, we report our discovery of a gaze behavior called Quiet Eye (QE) in minimally invasive surgery. The QE behavior has been extensively studied in sports training and has been associated with higher level of expertise in multiple sports. We investigated the QE behavior in two independently collected data sets of surgeons performing tasks in a sinus surgery setting and a robotic surgery setting, respectively. Our results show that the QE behavior is more likely to occur in successful task executions and in performances of surgeons of high level of expertise. These results open the door to use the QE behavior in both training and skill assessment in minimally invasive surgery.
SAGE: SLAM with Appearance and Geometry Prior for Endoscopy
Feb 22, 2022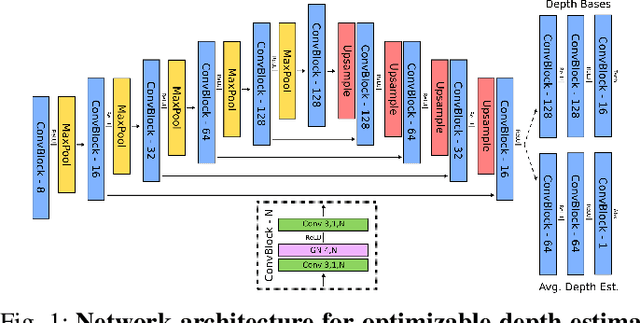
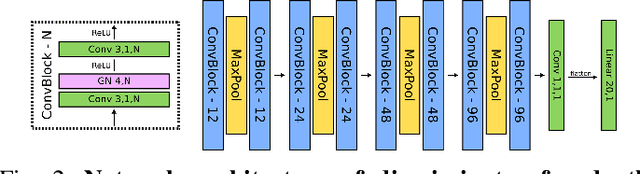
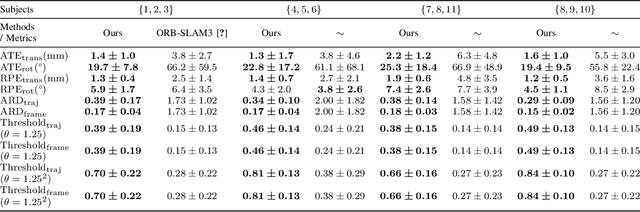
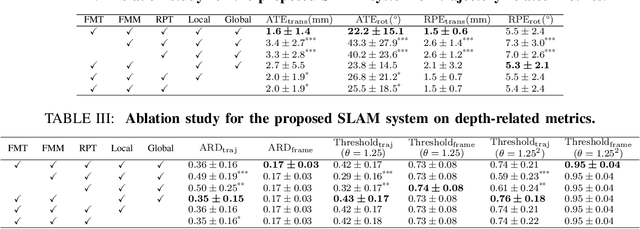
In endoscopy, many applications (e.g., surgical navigation) would benefit from a real-time method that can simultaneously track the endoscope and reconstruct the dense 3D geometry of the observed anatomy from a monocular endoscopic video. To this end, we develop a Simultaneous Localization and Mapping system by combining the learning-based appearance and optimizable geometry priors and factor graph optimization. The appearance and geometry priors are explicitly learned in an end-to-end differentiable training pipeline to master the task of pair-wise image alignment, one of the core components of the SLAM system. In our experiments, the proposed SLAM system is shown to robustly handle the challenges of texture scarceness and illumination variation that are commonly seen in endoscopy. The system generalizes well to unseen endoscopes and subjects and performs favorably compared with a state-of-the-art feature-based SLAM system. The code repository is available at https://github.com/lppllppl920/SAGE-SLAM.git.
Learn Proportional Derivative Controllable Latent Space from Pixels
Oct 15, 2021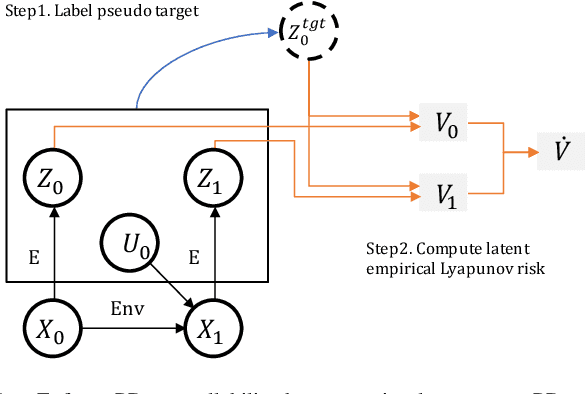
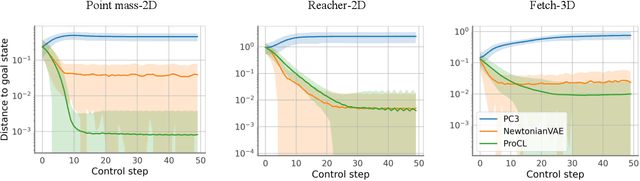
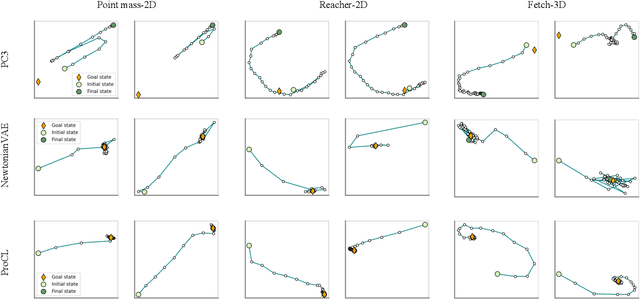
Recent advances in latent space dynamics model from pixels show promising progress in vision-based model predictive control (MPC). However, executing MPC in real time can be challenging due to its intensive computational cost in each timestep. We propose to introduce additional learning objectives to enforce that the learned latent space is proportional derivative controllable. In execution time, the simple PD-controller can be applied directly to the latent space encoded from pixels, to produce simple and effective control to systems with visual observations. We show that our method outperforms baseline methods to produce robust goal reaching and trajectory tracking in various environments.
Localization and Control of Magnetic Suture Needles in Cluttered Surgical Site with Blood and Tissue
May 20, 2021
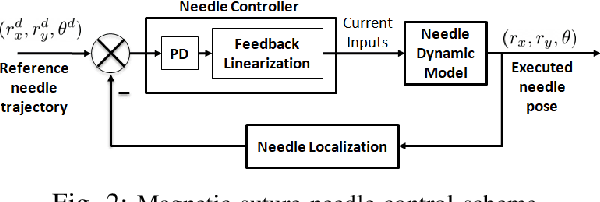
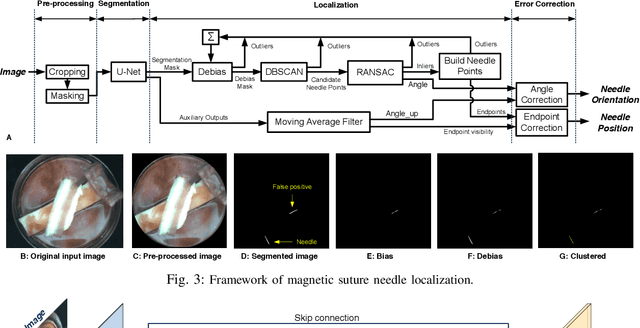
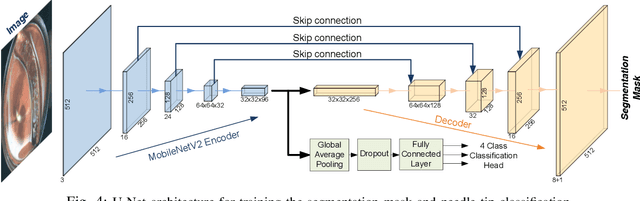
Real-time visual localization of needles is necessary for various surgical applications, including surgical automation and visual feedback. In this study we investigate localization and autonomous robotic control of needles in the context of our magneto-suturing system. Our system holds the potential for surgical manipulation with the benefit of minimal invasiveness and reduced patient side effects. However, the non-linear magnetic fields produce unintuitive forces and demand delicate position-based control that exceeds the capabilities of direct human manipulation. This makes automatic needle localization a necessity. Our localization method combines neural network-based segmentation and classical techniques, and we are able to consistently locate our needle with 0.73 mm RMS error in clean environments and 2.72 mm RMS error in challenging environments with blood and occlusion. The average localization RMS error is 2.16 mm for all environments we used in the experiments. We combine this localization method with our closed-loop feedback control system to demonstrate the further applicability of localization to autonomous control. Our needle is able to follow a running suture path in (1) no blood, no tissue; (2) heavy blood, no tissue; (3) no blood, with tissue; and (4) heavy blood, with tissue environments. The tip position tracking error ranges from 2.6 mm to 3.7 mm RMS, opening the door towards autonomous suturing tasks.
Single View Geocentric Pose in the Wild
May 18, 2021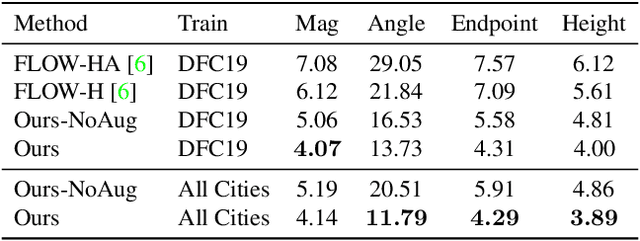
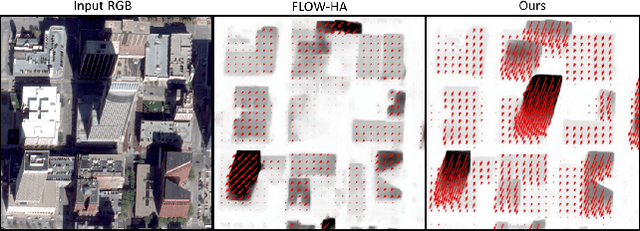
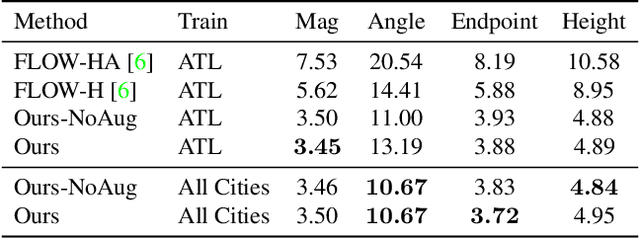
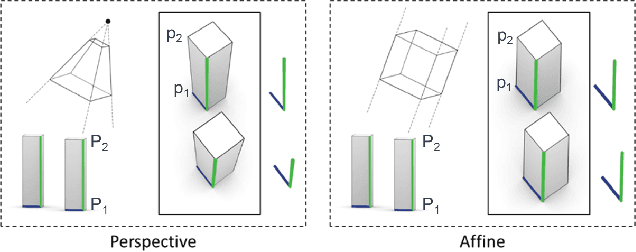
Current methods for Earth observation tasks such as semantic mapping, map alignment, and change detection rely on near-nadir images; however, often the first available images in response to dynamic world events such as natural disasters are oblique. These tasks are much more difficult for oblique images due to observed object parallax. There has been recent success in learning to regress geocentric pose, defined as height above ground and orientation with respect to gravity, by training with airborne lidar registered to satellite images. We present a model for this novel task that exploits affine invariance properties to outperform state of the art performance by a wide margin. We also address practical issues required to deploy this method in the wild for real-world applications. Our data and code are publicly available.