 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining In-distribution Attributes in Outliers for Out-of-distribution Detection
Dec 16, 2024Out-of-distribution (OOD) detection is indispensable for deploying reliable machine learning systems in real-world scenarios. Recent works, using auxiliary outliers in training, have shown good potential. However, they seldom concern the intrinsic correlations between in-distribution (ID) and OOD data. In this work, we discover an obvious correlation that OOD data usually possesses significant ID attributes. These attributes should be factored into the training process, rather than blindly suppressed as in previous approaches. Based on this insight, we propose a structured multi-view-based out-of-distribution detection learning (MVOL) framework, which facilitates rational handling of the intrinsic in-distribution attributes in outliers. We provide theoretical insights on the effectiveness of MVOL for OOD detection. Extensive experiments demonstrate the superiority of our framework to others. MVOL effectively utilizes both auxiliary OOD datasets and even wild datasets with noisy in-distribution data. Code is available at https://github.com/UESTC-nnLab/MVOL.
RT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model
Nov 07, 2024Recent advances in Large Language Models (LLMs) have showcased their remarkable reasoning capabilities, making them influential across various fields. However, in robotics, their use has primarily been limited to manipulation planning tasks due to their inherent textual output. This paper addresses this limitation by investigating the potential of adopting the reasoning ability of LLMs for generating numerical predictions in robotics tasks, specifically for robotic grasping. We propose Reasoning Tuning, a novel method that integrates a reasoning phase before prediction during training, leveraging the extensive prior knowledge and advanced reasoning abilities of LLMs. This approach enables LLMs, notably with multi-modal capabilities, to generate accurate numerical outputs like grasp poses that are context-aware and adaptable through conversations. Additionally, we present the Reasoning Tuning VLM Grasp dataset, carefully curated to facilitate the adaptation of LLMs to robotic grasping. Extensive validation on both grasping datasets and real-world experiments underscores the adaptability of multi-modal LLMs for numerical prediction tasks in robotics. This not only expands their applicability but also bridges the gap between text-based planning and direct robot control, thereby maximizing the potential of LLMs in robotics.
RLingua: Improving Reinforcement Learning Sample Efficiency in Robotic Manipulations With Large Language Models
Mar 19, 2024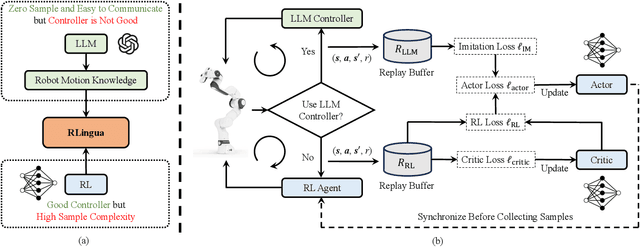
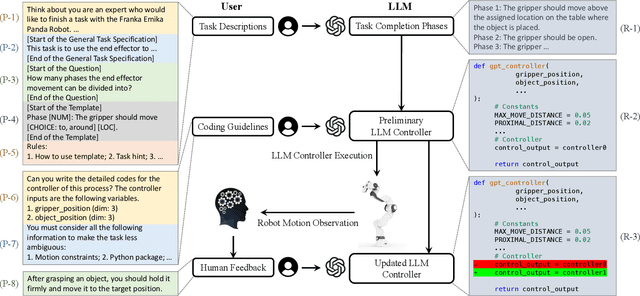
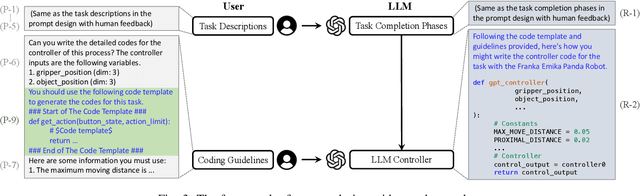
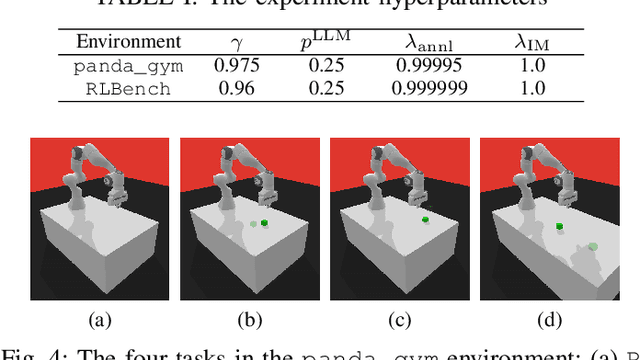
Reinforcement learning (RL) has demonstrated its capability in solving various tasks but is notorious for its low sample efficiency. In this paper, we propose RLingua, a framework that can leverage the internal knowledge of large language models (LLMs) to reduce the sample complexity of RL in robotic manipulations. To this end, we first present a method for extracting the prior knowledge of LLMs by prompt engineering so that a preliminary rule-based robot controller for a specific task can be generated in a user-friendly manner. Despite being imperfect, the LLM-generated robot controller is utilized to produce action samples during rollouts with a decaying probability, thereby improving RL's sample efficiency. We employ TD3, the widely-used RL baseline method, and modify the actor loss to regularize the policy learning towards the LLM-generated controller. RLingua also provides a novel method of improving the imperfect LLM-generated robot controllers by RL. We demonstrate that RLingua can significantly reduce the sample complexity of TD3 in four robot tasks of panda_gym and achieve high success rates in 12 sampled sparsely rewarded robot tasks in RLBench, where the standard TD3 fails. Additionally, We validated RLingua's effectiveness in real-world robot experiments through Sim2Real, demonstrating that the learned policies are effectively transferable to real robot tasks. Further details about our work are available at our project website https://rlingua.github.io.
VIHE: Virtual In-Hand Eye Transformer for 3D Robotic Manipulation
Mar 19, 2024In this work, we introduce the Virtual In-Hand Eye Transformer (VIHE), a novel method designed to enhance 3D manipulation capabilities through action-aware view rendering. VIHE autoregressively refines actions in multiple stages by conditioning on rendered views posed from action predictions in the earlier stages. These virtual in-hand views provide a strong inductive bias for effectively recognizing the correct pose for the hand, especially for challenging high-precision tasks such as peg insertion. On 18 manipulation tasks in RLBench simulated environments, VIHE achieves a new state-of-the-art, with a 12% absolute improvement, increasing from 65% to 77% over the existing state-of-the-art model using 100 demonstrations per task. In real-world scenarios, VIHE can learn manipulation tasks with just a handful of demonstrations, highlighting its practical utility. Videos and code implementation can be found at our project site: https://vihe-3d.github.io.
Reasoning Grasping via Multimodal Large Language Model
Feb 09, 2024



Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
MAC: ModAlity Calibration for Object Detection
Oct 14, 2023



The flourishing success of Deep Neural Networks(DNNs) on RGB-input perception tasks has opened unbounded possibilities for non-RGB-input perception tasks, such as object detection from wireless signals, lidar scans, and infrared images. Compared to the matured development pipeline of RGB-input (source modality) models, developing non-RGB-input (target-modality) models from scratch poses excessive challenges in the modality-specific network design/training tricks and labor in the target-modality annotation. In this paper, we propose ModAlity Calibration (MAC), an efficient pipeline for calibrating target-modality inputs to the DNN object detection models developed on the RGB (source) modality. We compose a target-modality-input model by adding a small calibrator module ahead of a source-modality model and introduce MAC training techniques to impose dense supervision on the calibrator. By leveraging (1) prior knowledge synthesized from the source-modality model and (2) paired {target, source} data with zero manual annotations, our target-modality models reach comparable or better metrics than baseline models that require 100% manual annotations. We demonstrate the effectiveness of MAC by composing the WiFi-input, Lidar-input, and Thermal-Infrared-input models upon the pre-trained RGB-input models respectively.