 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSS-TTSD: Text to Spoken Dialogue Generation
Mar 20, 2026Spoken dialogue generation is crucial for applications like podcasts, dynamic commentary, and entertainment content, but poses significant challenges compared to single-utterance text-to-speech (TTS). Key requirements include accurate turn-taking, cross-turn acoustic consistency, and long-form stability, which current models often fail to address due to a lack of dialogue context modeling. To bridge this gap, we present MOSS-TTSD, a spoken dialogue synthesis model designed for expressive, multi-party conversational speech across multiple languages. With enhanced long-context modeling, MOSS-TTSD generates long-form spoken conversations from dialogue scripts with explicit speaker tags, supporting up to 60 minutes of single-pass synthesis, multi-party dialogue with up to 5 speakers, and zero-shot voice cloning from a short reference audio clip. The model supports various mainstream languages, including English and Chinese, and is adapted to several long-form scenarios. Additionally, to address limitations of existing evaluation methods, we propose TTSD-eval, an objective evaluation framework based on forced alignment that measures speaker attribution accuracy and speaker similarity without relying on speaker diarization tools. Both objective and subjective evaluation results show that MOSS-TTSD surpasses strong open-source and proprietary baselines in dialogue synthesis.
MOSS-TTS Technical Report
Mar 18, 2026This technical report presents MOSS-TTS, a speech generation foundation model built on a scalable recipe: discrete audio tokens, autoregressive modeling, and large-scale pretraining. Built on MOSS-Audio-Tokenizer, a causal Transformer tokenizer that compresses 24 kHz audio to 12.5 fps with variable-bitrate RVQ and unified semantic-acoustic representations, we release two complementary generators: MOSS-TTS, which emphasizes structural simplicity, scalability, and long-context/control-oriented deployment, and MOSS-TTS-Local-Transformer, which introduces a frame-local autoregressive module for higher modeling efficiency, stronger speaker preservation, and a shorter time to first audio. Across multilingual and open-domain settings, MOSS-TTS supports zero-shot voice cloning, token-level duration control, phoneme-/pinyin-level pronunciation control, smooth code-switching, and stable long-form generation. This report summarizes the design, training recipe, and empirical characteristics of the released models.
MOSS Transcribe Diarize: Accurate Transcription with Speaker Diarization
Jan 08, 2026Speaker-Attributed, Time-Stamped Transcription (SATS) aims to transcribe what is said and to precisely determine the timing of each speaker, which is particularly valuable for meeting transcription. Existing SATS systems rarely adopt an end-to-end formulation and are further constrained by limited context windows, weak long-range speaker memory, and the inability to output timestamps. To address these limitations, we present MOSS Transcribe Diarize, a unified multimodal large language model that jointly performs Speaker-Attributed, Time-Stamped Transcription in an end-to-end paradigm. Trained on extensive real wild data and equipped with a 128k context window for up to 90-minute inputs, MOSS Transcribe Diarize scales well and generalizes robustly. Across comprehensive evaluations, it outperforms state-of-the-art commercial systems on multiple public and in-house benchmarks.
One-shot Robust Federated Learning of Independent Component Analysis
May 26, 2025This paper investigates a general robust one-shot aggregation framework for distributed and federated Independent Component Analysis (ICA) problem. We propose a geometric median-based aggregation algorithm that leverages $k$-means clustering to resolve the permutation ambiguity in local client estimations. Our method first performs k-means to partition client-provided estimators into clusters and then aggregates estimators within each cluster using the geometric median. This approach provably remains effective even in highly heterogeneous scenarios where at most half of the clients can observe only a minimal number of samples. The key theoretical contribution lies in the combined analysis of the geometric median's error bound-aided by sample quantiles-and the maximum misclustering rates of the aforementioned solution of $k$-means. The effectiveness of the proposed approach is further supported by simulation studies conducted under various heterogeneous settings.
Community detection for Contexual-LSBM: Theoretical limitation on misclassfication ratio and effecient algorithm
Jan 19, 2025The integration of both network information and node attribute information has recently gained significant attention in the context of community recovery problems. In this work, we address the task of determining the optimal classification rate for the Label-SBM(LSBM) model with node attribute information and. Specifically, we derive the optimal lower bound, which is characterized by the Chernoff-Hellinger divergence for a general LSBM network model with Gaussian node attributes. Additionally, we highlight the connection between the divergence $D(\bs\alpha, \mb P, \bs\mu)$ in our model and those introduced in \cite{yun2016optimal} and \cite{lu2016statistical}. We also presents a consistent algorithm based on spectral method for the proposed aggreated latent factor model.
RT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model
Nov 07, 2024Recent advances in Large Language Models (LLMs) have showcased their remarkable reasoning capabilities, making them influential across various fields. However, in robotics, their use has primarily been limited to manipulation planning tasks due to their inherent textual output. This paper addresses this limitation by investigating the potential of adopting the reasoning ability of LLMs for generating numerical predictions in robotics tasks, specifically for robotic grasping. We propose Reasoning Tuning, a novel method that integrates a reasoning phase before prediction during training, leveraging the extensive prior knowledge and advanced reasoning abilities of LLMs. This approach enables LLMs, notably with multi-modal capabilities, to generate accurate numerical outputs like grasp poses that are context-aware and adaptable through conversations. Additionally, we present the Reasoning Tuning VLM Grasp dataset, carefully curated to facilitate the adaptation of LLMs to robotic grasping. Extensive validation on both grasping datasets and real-world experiments underscores the adaptability of multi-modal LLMs for numerical prediction tasks in robotics. This not only expands their applicability but also bridges the gap between text-based planning and direct robot control, thereby maximizing the potential of LLMs in robotics.
Towards Robust Algorithms for Surgical Phase Recognition via Digital Twin-based Scene Representation
Oct 26, 2024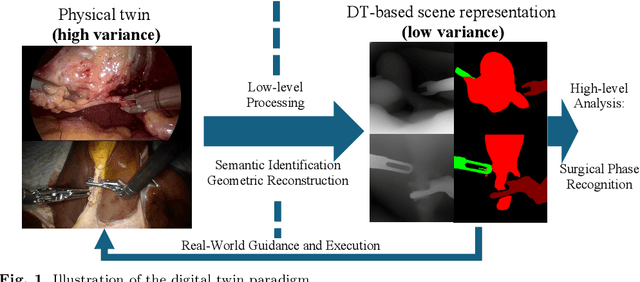

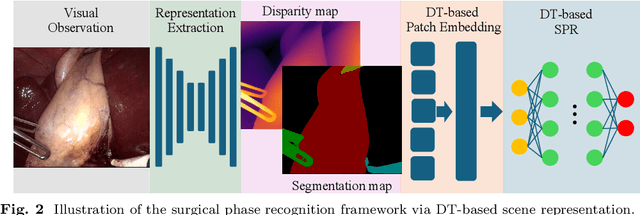
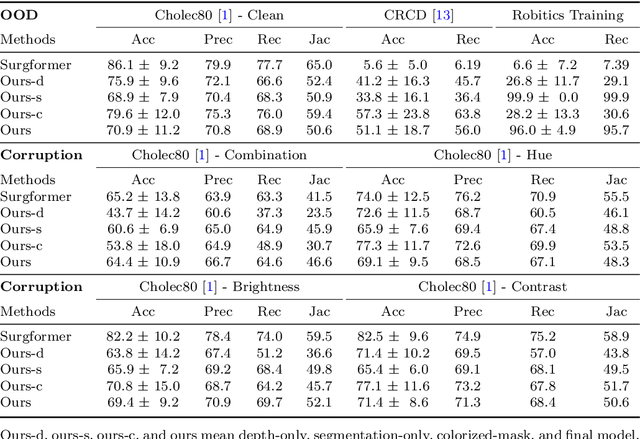
Purpose: Surgical phase recognition (SPR) is an integral component of surgical data science, enabling high-level surgical analysis. End-to-end trained neural networks that predict surgical phase directly from videos have shown excellent performance on benchmarks. However, these models struggle with robustness due to non-causal associations in the training set, resulting in poor generalizability. Our goal is to improve model robustness to variations in the surgical videos by leveraging the digital twin (DT) paradigm -- an intermediary layer to separate high-level analysis (SPR) from low-level processing (geometric understanding). This approach takes advantage of the recent vision foundation models that ensure reliable low-level scene understanding to craft DT-based scene representations that support various high-level tasks. Methods: We present a DT-based framework for SPR from videos. The framework employs vision foundation models to extract representations. We embed the representation in place of raw video inputs in the state-of-the-art Surgformer model. The framework is trained on the Cholec80 dataset and evaluated on out-of-distribution (OOD) and corrupted test samples. Results: Contrary to the vulnerability of the baseline model, our framework demonstrates strong robustness on both OOD and corrupted samples, with a video-level accuracy of 51.1 on the challenging CRCD dataset, 96.0 on an internal robotics training dataset, and 64.4 on a highly corrupted Cholec80 test set. Conclusion: Our findings lend support to the thesis that DT-based scene representations are effective in enhancing model robustness. Future work will seek to improve the feature informativeness, automate feature extraction, and incorporate interpretability for a more comprehensive framework.
Jigsaw Game: Federated Clustering
Jul 17, 2024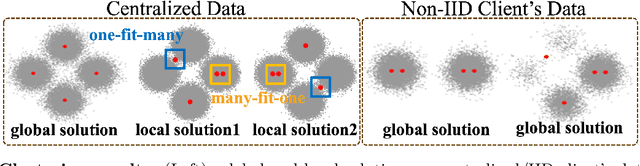
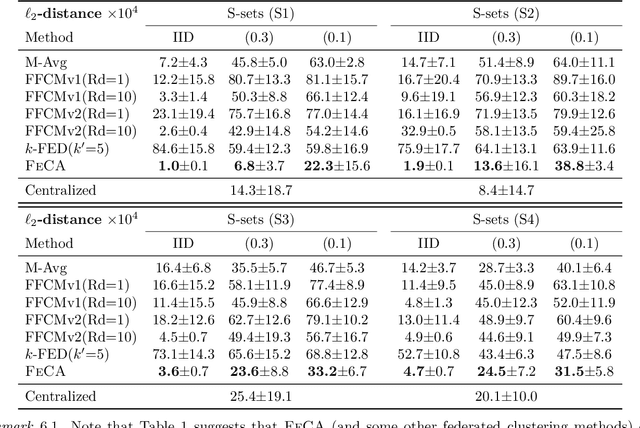
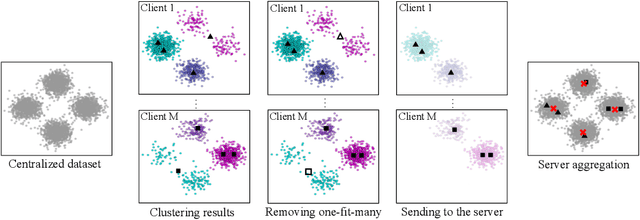
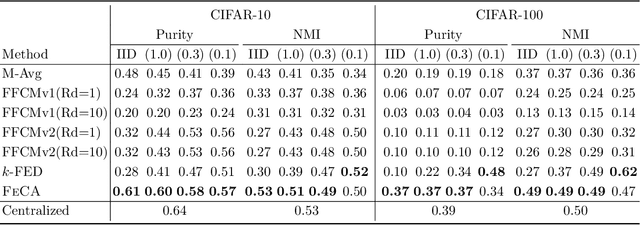
Federated learning has recently garnered significant attention, especially within the domain of supervised learning. However, despite the abundance of unlabeled data on end-users, unsupervised learning problems such as clustering in the federated setting remain underexplored. In this paper, we investigate the federated clustering problem, with a focus on federated k-means. We outline the challenge posed by its non-convex objective and data heterogeneity in the federated framework. To tackle these challenges, we adopt a new perspective by studying the structures of local solutions in k-means and propose a one-shot algorithm called FeCA (Federated Centroid Aggregation). FeCA adaptively refines local solutions on clients, then aggregates these refined solutions to recover the global solution of the entire dataset in a single round. We empirically demonstrate the robustness of FeCA under various federated scenarios on both synthetic and real-world data. Additionally, we extend FeCA to representation learning and present DeepFeCA, which combines DeepCluster and FeCA for unsupervised feature learning in the federated setting.
SegSTRONG-C: Segmenting Surgical Tools Robustly On Non-adversarial Generated Corruptions -- An EndoVis'24 Challenge
Jul 16, 2024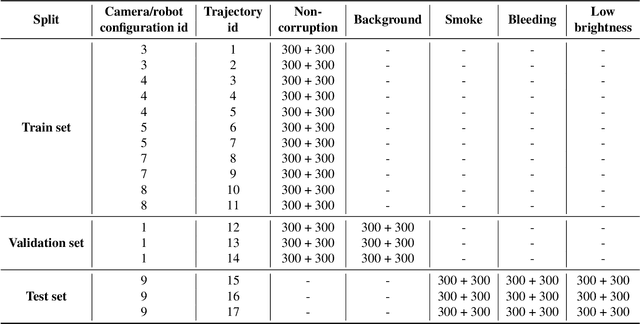


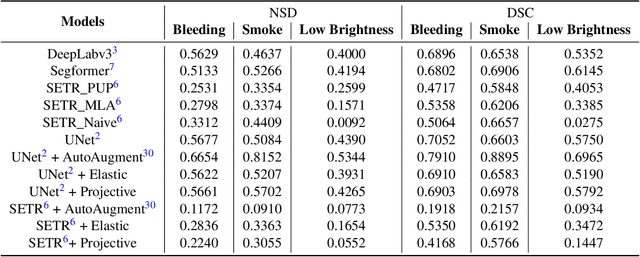
Accurate segmentation of tools in robot-assisted surgery is critical for machine perception, as it facilitates numerous downstream tasks including augmented reality feedback. While current feed-forward neural network-based methods exhibit excellent segmentation performance under ideal conditions, these models have proven susceptible to even minor corruptions, significantly impairing the model's performance. This vulnerability is especially problematic in surgical settings where predictions might be used to inform high-stakes decisions. To better understand model behavior under non-adversarial corruptions, prior work has explored introducing artificial corruptions, like Gaussian noise or contrast perturbation to test set images, to assess model robustness. However, these corruptions are either not photo-realistic or model/task agnostic. Thus, these investigations provide limited insights into model deterioration under realistic surgical corruptions. To address this limitation, we introduce the SegSTRONG-C challenge that aims to promote the development of algorithms robust to unforeseen but plausible image corruptions of surgery, like smoke, bleeding, and low brightness. We collect and release corruption-free mock endoscopic video sequences for the challenge participants to train their algorithms and benchmark them on video sequences with photo-realistic non-adversarial corruptions for a binary robot tool segmentation task. This new benchmark will allow us to carefully study neural network robustness to non-adversarial corruptions of surgery, thus constituting an important first step towards more robust models for surgical computer vision. In this paper, we describe the data collection and annotation protocol, baseline evaluations of established segmentation models, and data augmentation-based techniques to enhance model robustness.
Causal inference through multi-stage learning and doubly robust deep neural networks
Jul 11, 2024
Deep neural networks (DNNs) have demonstrated remarkable empirical performance in large-scale supervised learning problems, particularly in scenarios where both the sample size $n$ and the dimension of covariates $p$ are large. This study delves into the application of DNNs across a wide spectrum of intricate causal inference tasks, where direct estimation falls short and necessitates multi-stage learning. Examples include estimating the conditional average treatment effect and dynamic treatment effect. In this framework, DNNs are constructed sequentially, with subsequent stages building upon preceding ones. To mitigate the impact of estimation errors from early stages on subsequent ones, we integrate DNNs in a doubly robust manner. In contrast to previous research, our study offers theoretical assurances regarding the effectiveness of DNNs in settings where the dimensionality $p$ expands with the sample size. These findings are significant independently and extend to degenerate single-stage learning problems.