 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgiPose: Estimating Surgical Tool Kinematics from Monocular Video for Surgical Robot Learning
Dec 19, 2025Imitation learning (IL) has shown immense promise in enabling autonomous dexterous manipulation, including learning surgical tasks. To fully unlock the potential of IL for surgery, access to clinical datasets is needed, which unfortunately lack the kinematic data required for current IL approaches. A promising source of large-scale surgical demonstrations is monocular surgical videos available online, making monocular pose estimation a crucial step toward enabling large-scale robot learning. Toward this end, we propose SurgiPose, a differentiable rendering based approach to estimate kinematic information from monocular surgical videos, eliminating the need for direct access to ground truth kinematics. Our method infers tool trajectories and joint angles by optimizing tool pose parameters to minimize the discrepancy between rendered and real images. To evaluate the effectiveness of our approach, we conduct experiments on two robotic surgical tasks: tissue lifting and needle pickup, using the da Vinci Research Kit Si (dVRK Si). We train imitation learning policies with both ground truth measured kinematics and estimated kinematics from video and compare their performance. Our results show that policies trained on estimated kinematics achieve comparable success rates to those trained on ground truth data, demonstrating the feasibility of using monocular video based kinematic estimation for surgical robot learning. By enabling kinematic estimation from monocular surgical videos, our work lays the foundation for large scale learning of autonomous surgical policies from online surgical data.
* 8 pages, 6 figures, 2 tables
Autonomous Soft Robotic Guidewire Navigation via Imitation Learning
Oct 10, 2025In endovascular surgery, endovascular interventionists push a thin tube called a catheter, guided by a thin wire to a treatment site inside the patient's blood vessels to treat various conditions such as blood clots, aneurysms, and malformations. Guidewires with robotic tips can enhance maneuverability, but they present challenges in modeling and control. Automation of soft robotic guidewire navigation has the potential to overcome these challenges, increasing the precision and safety of endovascular navigation. In other surgical domains, end-to-end imitation learning has shown promising results. Thus, we develop a transformer-based imitation learning framework with goal conditioning, relative action outputs, and automatic contrast dye injections to enable generalizable soft robotic guidewire navigation in an aneurysm targeting task. We train the model on 36 different modular bifurcated geometries, generating 647 total demonstrations under simulated fluoroscopy, and evaluate it on three previously unseen vascular geometries. The model can autonomously drive the tip of the robot to the aneurysm location with a success rate of 83% on the unseen geometries, outperforming several baselines. In addition, we present ablation and baseline studies to evaluate the effectiveness of each design and data collection choice. Project website: https://softrobotnavigation.github.io/
SRT-H: A Hierarchical Framework for Autonomous Surgery via Language Conditioned Imitation Learning
May 15, 2025Research on autonomous robotic surgery has largely focused on simple task automation in controlled environments. However, real-world surgical applications require dexterous manipulation over extended time scales while demanding generalization across diverse variations in human tissue. These challenges remain difficult to address using existing logic-based or conventional end-to-end learning strategies. To bridge this gap, we propose a hierarchical framework for dexterous, long-horizon surgical tasks. Our method employs a high-level policy for task planning and a low-level policy for generating task-space controls for the surgical robot. The high-level planner plans tasks using language, producing task-specific or corrective instructions that guide the robot at a coarse level. Leveraging language as a planning modality offers an intuitive and generalizable interface, mirroring how experienced surgeons instruct traineers during procedures. We validate our framework in ex-vivo experiments on a complex minimally invasive procedure, cholecystectomy, and conduct ablative studies to assess key design choices. Our approach achieves a 100% success rate across n=8 different ex-vivo gallbladders, operating fully autonomously without human intervention. The hierarchical approach greatly improves the policy's ability to recover from suboptimal states that are inevitable in the highly dynamic environment of realistic surgical applications. This work represents the first demonstration of step-level autonomy, marking a critical milestone toward autonomous surgical systems for clinical studies. By advancing generalizable autonomy in surgical robotics, our approach brings the field closer to real-world deployment.
Towards Robust Algorithms for Surgical Phase Recognition via Digital Twin-based Scene Representation
Oct 26, 2024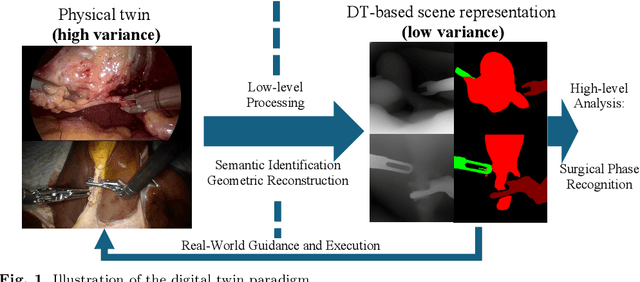

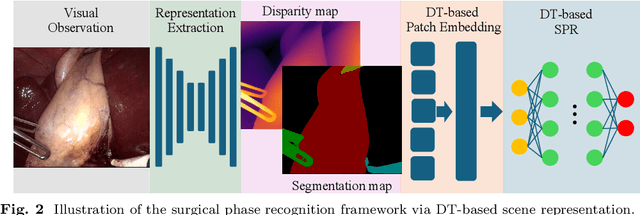
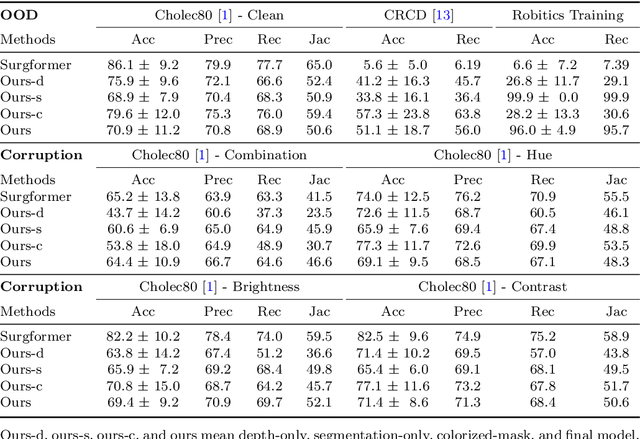
Purpose: Surgical phase recognition (SPR) is an integral component of surgical data science, enabling high-level surgical analysis. End-to-end trained neural networks that predict surgical phase directly from videos have shown excellent performance on benchmarks. However, these models struggle with robustness due to non-causal associations in the training set, resulting in poor generalizability. Our goal is to improve model robustness to variations in the surgical videos by leveraging the digital twin (DT) paradigm -- an intermediary layer to separate high-level analysis (SPR) from low-level processing (geometric understanding). This approach takes advantage of the recent vision foundation models that ensure reliable low-level scene understanding to craft DT-based scene representations that support various high-level tasks. Methods: We present a DT-based framework for SPR from videos. The framework employs vision foundation models to extract representations. We embed the representation in place of raw video inputs in the state-of-the-art Surgformer model. The framework is trained on the Cholec80 dataset and evaluated on out-of-distribution (OOD) and corrupted test samples. Results: Contrary to the vulnerability of the baseline model, our framework demonstrates strong robustness on both OOD and corrupted samples, with a video-level accuracy of 51.1 on the challenging CRCD dataset, 96.0 on an internal robotics training dataset, and 64.4 on a highly corrupted Cholec80 test set. Conclusion: Our findings lend support to the thesis that DT-based scene representations are effective in enhancing model robustness. Future work will seek to improve the feature informativeness, automate feature extraction, and incorporate interpretability for a more comprehensive framework.
Surgical Robot Transformer (SRT): Imitation Learning for Surgical Tasks
Jul 17, 2024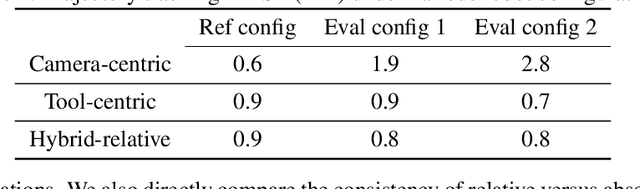
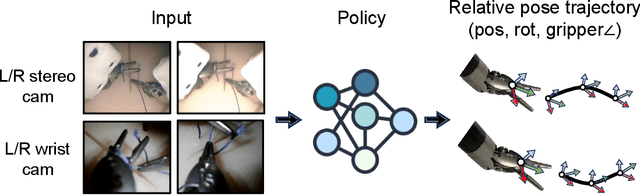
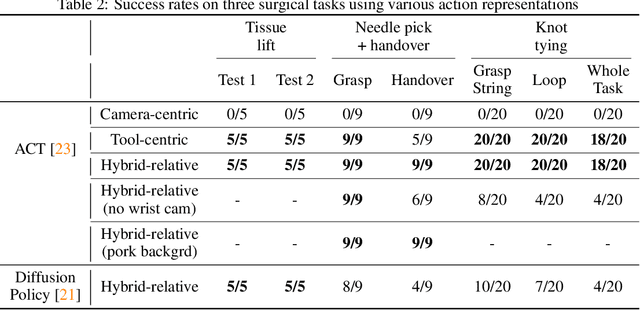
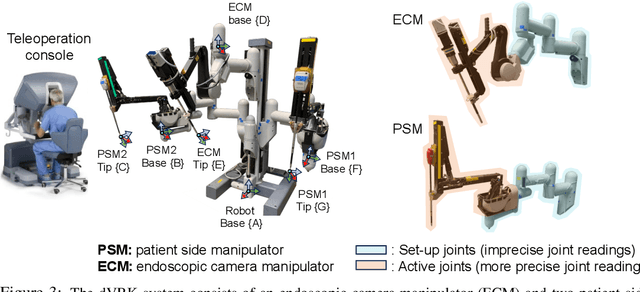
We explore whether surgical manipulation tasks can be learned on the da Vinci robot via imitation learning. However, the da Vinci system presents unique challenges which hinder straight-forward implementation of imitation learning. Notably, its forward kinematics is inconsistent due to imprecise joint measurements, and naively training a policy using such approximate kinematics data often leads to task failure. To overcome this limitation, we introduce a relative action formulation which enables successful policy training and deployment using its approximate kinematics data. A promising outcome of this approach is that the large repository of clinical data, which contains approximate kinematics, may be directly utilized for robot learning without further corrections. We demonstrate our findings through successful execution of three fundamental surgical tasks, including tissue manipulation, needle handling, and knot-tying.
General surgery vision transformer: A video pre-trained foundation model for general surgery
Mar 12, 2024



The absence of openly accessible data and specialized foundation models is a major barrier for computational research in surgery. Toward this, (i) we open-source the largest dataset of general surgery videos to-date, consisting of 680 hours of surgical videos, including data from robotic and laparoscopic techniques across 28 procedures; (ii) we propose a technique for video pre-training a general surgery vision transformer (GSViT) on surgical videos based on forward video prediction that can run in real-time for surgical applications, toward which we open-source the code and weights of GSViT; (iii) we also release code and weights for procedure-specific fine-tuned versions of GSViT across 10 procedures; (iv) we demonstrate the performance of GSViT on the Cholec80 phase annotation task, displaying improved performance over state-of-the-art single frame predictors.
Addressing cognitive bias in medical language models
Feb 20, 2024



There is increasing interest in the application large language models (LLMs) to the medical field, in part because of their impressive performance on medical exam questions. While promising, exam questions do not reflect the complexity of real patient-doctor interactions. In reality, physicians' decisions are shaped by many complex factors, such as patient compliance, personal experience, ethical beliefs, and cognitive bias. Taking a step toward understanding this, our hypothesis posits that when LLMs are confronted with clinical questions containing cognitive biases, they will yield significantly less accurate responses compared to the same questions presented without such biases. In this study, we developed BiasMedQA, a benchmark for evaluating cognitive biases in LLMs applied to medical tasks. Using BiasMedQA we evaluated six LLMs, namely GPT-4, Mixtral-8x70B, GPT-3.5, PaLM-2, Llama 2 70B-chat, and the medically specialized PMC Llama 13B. We tested these models on 1,273 questions from the US Medical Licensing Exam (USMLE) Steps 1, 2, and 3, modified to replicate common clinically-relevant cognitive biases. Our analysis revealed varying effects for biases on these LLMs, with GPT-4 standing out for its resilience to bias, in contrast to Llama 2 70B-chat and PMC Llama 13B, which were disproportionately affected by cognitive bias. Our findings highlight the critical need for bias mitigation in the development of medical LLMs, pointing towards safer and more reliable applications in healthcare.
General-purpose foundation models for increased autonomy in robot-assisted surgery
Jan 01, 2024The dominant paradigm for end-to-end robot learning focuses on optimizing task-specific objectives that solve a single robotic problem such as picking up an object or reaching a target position. However, recent work on high-capacity models in robotics has shown promise toward being trained on large collections of diverse and task-agnostic datasets of video demonstrations. These models have shown impressive levels of generalization to unseen circumstances, especially as the amount of data and the model complexity scale. Surgical robot systems that learn from data have struggled to advance as quickly as other fields of robot learning for a few reasons: (1) there is a lack of existing large-scale open-source data to train models, (2) it is challenging to model the soft-body deformations that these robots work with during surgery because simulation cannot match the physical and visual complexity of biological tissue, and (3) surgical robots risk harming patients when tested in clinical trials and require more extensive safety measures. This perspective article aims to provide a path toward increasing robot autonomy in robot-assisted surgery through the development of a multi-modal, multi-task, vision-language-action model for surgical robots. Ultimately, we argue that surgical robots are uniquely positioned to benefit from general-purpose models and provide three guiding actions toward increased autonomy in robot-assisted surgery.
Cooperative vs. Teleoperation Control of the Steady Hand Eye Robot with Adaptive Sclera Force Control: A Comparative Study
Dec 04, 2023



A surgeon's physiological hand tremor can significantly impact the outcome of delicate and precise retinal surgery, such as retinal vein cannulation (RVC) and epiretinal membrane peeling. Robot-assisted eye surgery technology provides ophthalmologists with advanced capabilities such as hand tremor cancellation, hand motion scaling, and safety constraints that enable them to perform these otherwise challenging and high-risk surgeries with high precision and safety. Steady-Hand Eye Robot (SHER) with cooperative control mode can filter out surgeon's hand tremor, yet another important safety feature, that is, minimizing the contact force between the surgical instrument and sclera surface for avoiding tissue damage cannot be met in this control mode. Also, other capabilities, such as hand motion scaling and haptic feedback, require a teleoperation control framework. In this work, for the first time, we implemented a teleoperation control mode incorporated with an adaptive sclera force control algorithm using a PHANTOM Omni haptic device and a force-sensing surgical instrument equipped with Fiber Bragg Grating (FBG) sensors attached to the SHER 2.1 end-effector. This adaptive sclera force control algorithm allows the robot to dynamically minimize the tool-sclera contact force. Moreover, for the first time, we compared the performance of the proposed adaptive teleoperation mode with the cooperative mode by conducting a vessel-following experiment inside an eye phantom under a microscope.
Micromanipulation in Surgery: Autonomous Needle Insertion Inside the Eye for Targeted Drug Delivery
Jun 30, 2023We consider a micromanipulation problem in eye surgery, specifically retinal vein cannulation (RVC). RVC involves inserting a microneedle into a retinal vein for the purpose of targeted drug delivery. The procedure requires accurately guiding a needle to a target vein and inserting it while avoiding damage to the surrounding tissues. RVC can be considered similar to the reach or push task studied in robotics manipulation, but with additional constraints related to precision and safety while interacting with soft tissues. Prior works have mainly focused developing robotic hardware and sensors to enhance the surgeons' accuracy, leaving the automation of RVC largely unexplored. In this paper, we present the first autonomous strategy for RVC while relying on a minimal setup: a robotic arm, a needle, and monocular images. Our system exclusively relies on monocular vision to achieve precise navigation, gentle placement on the target vein, and safe insertion without causing tissue damage. Throughout the procedure, we employ machine learning for perception and to identify key surgical events such as needle-vein contact and vein punctures. Detecting these events guides our task and motion planning framework, which generates safe trajectories using model predictive control to complete the procedure. We validate our system through 24 successful autonomous trials on 4 cadaveric pig eyes. We show that our system can navigate to target veins within 22 micrometers of XY accuracy and under 35 seconds, and consistently puncture the target vein without causing tissue damage. Preliminary comparison to a human demonstrates the superior accuracy and reliability of our system.