 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Algorithms for Surgical Phase Recognition via Digital Twin-based Scene Representation
Paper and Code
Oct 26, 2024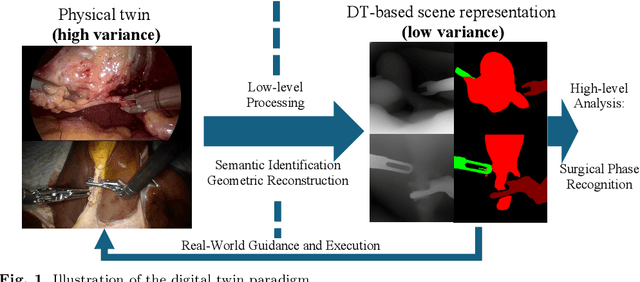

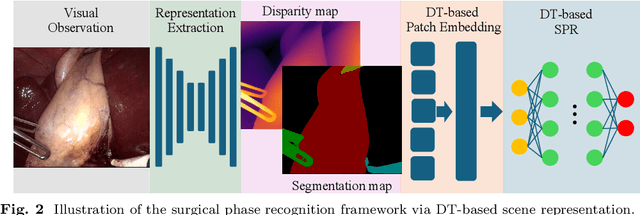
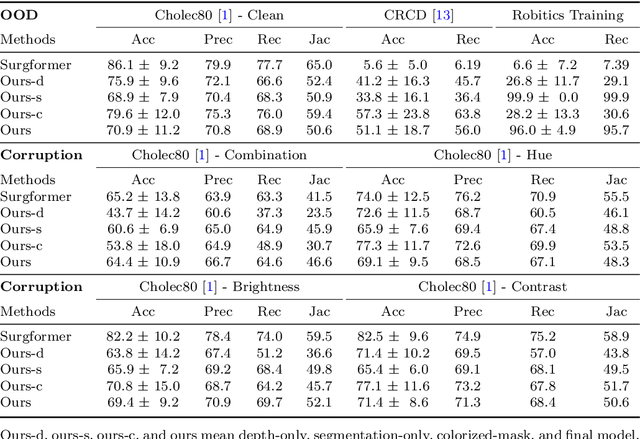
Purpose: Surgical phase recognition (SPR) is an integral component of surgical data science, enabling high-level surgical analysis. End-to-end trained neural networks that predict surgical phase directly from videos have shown excellent performance on benchmarks. However, these models struggle with robustness due to non-causal associations in the training set, resulting in poor generalizability. Our goal is to improve model robustness to variations in the surgical videos by leveraging the digital twin (DT) paradigm -- an intermediary layer to separate high-level analysis (SPR) from low-level processing (geometric understanding). This approach takes advantage of the recent vision foundation models that ensure reliable low-level scene understanding to craft DT-based scene representations that support various high-level tasks. Methods: We present a DT-based framework for SPR from videos. The framework employs vision foundation models to extract representations. We embed the representation in place of raw video inputs in the state-of-the-art Surgformer model. The framework is trained on the Cholec80 dataset and evaluated on out-of-distribution (OOD) and corrupted test samples. Results: Contrary to the vulnerability of the baseline model, our framework demonstrates strong robustness on both OOD and corrupted samples, with a video-level accuracy of 51.1 on the challenging CRCD dataset, 96.0 on an internal robotics training dataset, and 64.4 on a highly corrupted Cholec80 test set. Conclusion: Our findings lend support to the thesis that DT-based scene representations are effective in enhancing model robustness. Future work will seek to improve the feature informativeness, automate feature extraction, and incorporate interpretability for a more comprehensive framework.