 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBronchOpt : Vision-Based Pose Optimization with Fine-Tuned Foundation Models for Accurate Bronchoscopy Navigation
Nov 12, 2025



Accurate intra-operative localization of the bronchoscope tip relative to patient anatomy remains challenging due to respiratory motion, anatomical variability, and CT-to-body divergence that cause deformation and misalignment between intra-operative views and pre-operative CT. Existing vision-based methods often fail to generalize across domains and patients, leading to residual alignment errors. This work establishes a generalizable foundation for bronchoscopy navigation through a robust vision-based framework and a new synthetic benchmark dataset that enables standardized and reproducible evaluation. We propose a vision-based pose optimization framework for frame-wise 2D-3D registration between intra-operative endoscopic views and pre-operative CT anatomy. A fine-tuned modality- and domain-invariant encoder enables direct similarity computation between real endoscopic RGB frames and CT-rendered depth maps, while a differentiable rendering module iteratively refines camera poses through depth consistency. To enhance reproducibility, we introduce the first public synthetic benchmark dataset for bronchoscopy navigation, addressing the lack of paired CT-endoscopy data. Trained exclusively on synthetic data distinct from the benchmark, our model achieves an average translational error of 2.65 mm and a rotational error of 0.19 rad, demonstrating accurate and stable localization. Qualitative results on real patient data further confirm strong cross-domain generalization, achieving consistent frame-wise 2D-3D alignment without domain-specific adaptation. Overall, the proposed framework achieves robust, domain-invariant localization through iterative vision-based optimization, while the new benchmark provides a foundation for standardized progress in vision-based bronchoscopy navigation.
DualVision ArthroNav: Investigating Opportunities to Enhance Localization and Reconstruction in Image-based Arthroscopy Navigation via External Cameras
Nov 12, 2025


Arthroscopic procedures can greatly benefit from navigation systems that enhance spatial awareness, depth perception, and field of view. However, existing optical tracking solutions impose strict workspace constraints and disrupt surgical workflow. Vision-based alternatives, though less invasive, often rely solely on the monocular arthroscope camera, making them prone to drift, scale ambiguity, and sensitivity to rapid motion or occlusion. We propose DualVision ArthroNav, a multi-camera arthroscopy navigation system that integrates an external camera rigidly mounted on the arthroscope. The external camera provides stable visual odometry and absolute localization, while the monocular arthroscope video enables dense scene reconstruction. By combining these complementary views, our system resolves the scale ambiguity and long-term drift inherent in monocular SLAM and ensures robust relocalization. Experiments demonstrate that our system effectively compensates for calibration errors, achieving an average absolute trajectory error of 1.09 mm. The reconstructed scenes reach an average target registration error of 2.16 mm, with high visual fidelity (SSIM = 0.69, PSNR = 22.19). These results indicate that our system provides a practical and cost-efficient solution for arthroscopic navigation, bridging the gap between optical tracking and purely vision-based systems, and paving the way toward clinically deployable, fully vision-based arthroscopic guidance.
Did you just see that? Arbitrary view synthesis for egocentric replay of operating room workflows from ambient sensors
Oct 06, 2025Observing surgical practice has historically relied on fixed vantage points or recollections, leaving the egocentric visual perspectives that guide clinical decisions undocumented. Fixed-camera video can capture surgical workflows at the room-scale, but cannot reconstruct what each team member actually saw. Thus, these videos only provide limited insights into how decisions that affect surgical safety, training, and workflow optimization are made. Here we introduce EgoSurg, the first framework to reconstruct the dynamic, egocentric replays for any operating room (OR) staff directly from wall-mounted fixed-camera video, and thus, without intervention to clinical workflow. EgoSurg couples geometry-driven neural rendering with diffusion-based view enhancement, enabling high-visual fidelity synthesis of arbitrary and egocentric viewpoints at any moment. In evaluation across multi-site surgical cases and controlled studies, EgoSurg reconstructs person-specific visual fields and arbitrary viewpoints with high visual quality and fidelity. By transforming existing OR camera infrastructure into a navigable dynamic 3D record, EgoSurg establishes a new foundation for immersive surgical data science, enabling surgical practice to be visualized, experienced, and analyzed from every angle.
Towards Robust Algorithms for Surgical Phase Recognition via Digital Twin-based Scene Representation
Oct 26, 2024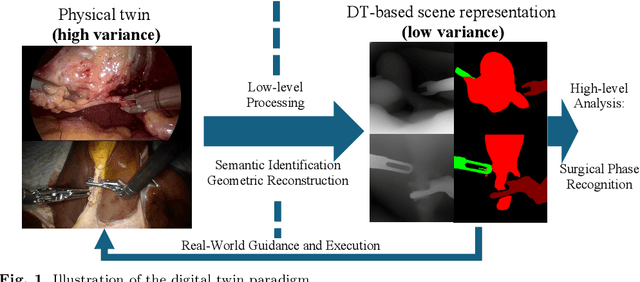

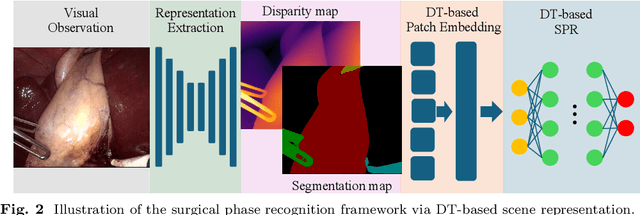
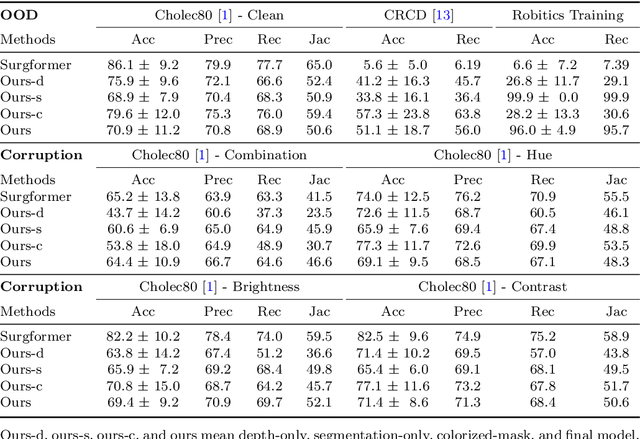
Purpose: Surgical phase recognition (SPR) is an integral component of surgical data science, enabling high-level surgical analysis. End-to-end trained neural networks that predict surgical phase directly from videos have shown excellent performance on benchmarks. However, these models struggle with robustness due to non-causal associations in the training set, resulting in poor generalizability. Our goal is to improve model robustness to variations in the surgical videos by leveraging the digital twin (DT) paradigm -- an intermediary layer to separate high-level analysis (SPR) from low-level processing (geometric understanding). This approach takes advantage of the recent vision foundation models that ensure reliable low-level scene understanding to craft DT-based scene representations that support various high-level tasks. Methods: We present a DT-based framework for SPR from videos. The framework employs vision foundation models to extract representations. We embed the representation in place of raw video inputs in the state-of-the-art Surgformer model. The framework is trained on the Cholec80 dataset and evaluated on out-of-distribution (OOD) and corrupted test samples. Results: Contrary to the vulnerability of the baseline model, our framework demonstrates strong robustness on both OOD and corrupted samples, with a video-level accuracy of 51.1 on the challenging CRCD dataset, 96.0 on an internal robotics training dataset, and 64.4 on a highly corrupted Cholec80 test set. Conclusion: Our findings lend support to the thesis that DT-based scene representations are effective in enhancing model robustness. Future work will seek to improve the feature informativeness, automate feature extraction, and incorporate interpretability for a more comprehensive framework.
Seamless Augmented Reality Integration in Arthroscopy: A Pipeline for Articular Reconstruction and Guidance
Oct 01, 2024Arthroscopy is a minimally invasive surgical procedure used to diagnose and treat joint problems. The clinical workflow of arthroscopy typically involves inserting an arthroscope into the joint through a small incision, during which surgeons navigate and operate largely by relying on their visual assessment through the arthroscope. However, the arthroscope's restricted field of view and lack of depth perception pose challenges in navigating complex articular structures and achieving surgical precision during procedures. Aiming at enhancing intraoperative awareness, we present a robust pipeline that incorporates simultaneous localization and mapping, depth estimation, and 3D Gaussian splatting to realistically reconstruct intra-articular structures solely based on monocular arthroscope video. Extending 3D reconstruction to Augmented Reality (AR) applications, our solution offers AR assistance for articular notch measurement and annotation anchoring in a human-in-the-loop manner. Compared to traditional Structure-from-Motion and Neural Radiance Field-based methods, our pipeline achieves dense 3D reconstruction and competitive rendering fidelity with explicit 3D representation in 7 minutes on average. When evaluated on four phantom datasets, our method achieves RMSE = 2.21mm reconstruction error, PSNR = 32.86 and SSIM = 0.89 on average. Because our pipeline enables AR reconstruction and guidance directly from monocular arthroscopy without any additional data and/or hardware, our solution may hold the potential for enhancing intraoperative awareness and facilitating surgical precision in arthroscopy. Our AR measurement tool achieves accuracy within 1.59 +/- 1.81mm and the AR annotation tool achieves a mIoU of 0.721.
SegSTRONG-C: Segmenting Surgical Tools Robustly On Non-adversarial Generated Corruptions -- An EndoVis'24 Challenge
Jul 16, 2024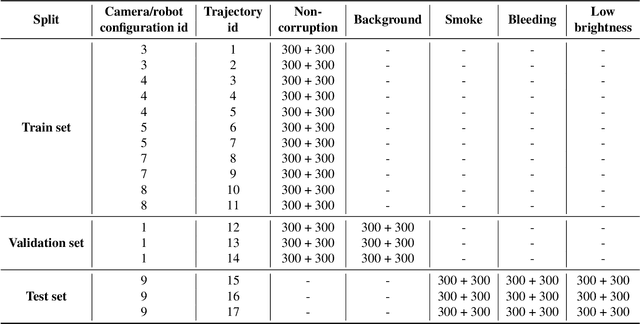


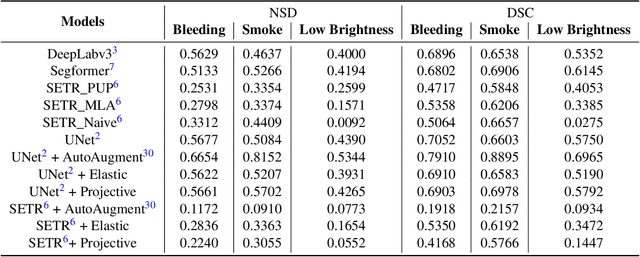
Accurate segmentation of tools in robot-assisted surgery is critical for machine perception, as it facilitates numerous downstream tasks including augmented reality feedback. While current feed-forward neural network-based methods exhibit excellent segmentation performance under ideal conditions, these models have proven susceptible to even minor corruptions, significantly impairing the model's performance. This vulnerability is especially problematic in surgical settings where predictions might be used to inform high-stakes decisions. To better understand model behavior under non-adversarial corruptions, prior work has explored introducing artificial corruptions, like Gaussian noise or contrast perturbation to test set images, to assess model robustness. However, these corruptions are either not photo-realistic or model/task agnostic. Thus, these investigations provide limited insights into model deterioration under realistic surgical corruptions. To address this limitation, we introduce the SegSTRONG-C challenge that aims to promote the development of algorithms robust to unforeseen but plausible image corruptions of surgery, like smoke, bleeding, and low brightness. We collect and release corruption-free mock endoscopic video sequences for the challenge participants to train their algorithms and benchmark them on video sequences with photo-realistic non-adversarial corruptions for a binary robot tool segmentation task. This new benchmark will allow us to carefully study neural network robustness to non-adversarial corruptions of surgery, thus constituting an important first step towards more robust models for surgical computer vision. In this paper, we describe the data collection and annotation protocol, baseline evaluations of established segmentation models, and data augmentation-based techniques to enhance model robustness.
TAToo: Vision-based Joint Tracking of Anatomy and Tool for Skull-base Surgery
Dec 29, 2022Purpose: Tracking the 3D motion of the surgical tool and the patient anatomy is a fundamental requirement for computer-assisted skull-base surgery. The estimated motion can be used both for intra-operative guidance and for downstream skill analysis. Recovering such motion solely from surgical videos is desirable, as it is compliant with current clinical workflows and instrumentation. Methods: We present Tracker of Anatomy and Tool (TAToo). TAToo jointly tracks the rigid 3D motion of patient skull and surgical drill from stereo microscopic videos. TAToo estimates motion via an iterative optimization process in an end-to-end differentiable form. For robust tracking performance, TAToo adopts a probabilistic formulation and enforces geometric constraints on the object level. Results: We validate TAToo on both simulation data, where ground truth motion is available, as well as on anthropomorphic phantom data, where optical tracking provides a strong baseline. We report sub-millimeter and millimeter inter-frame tracking accuracy for skull and drill, respectively, with rotation errors below 1{\deg}. We further illustrate how TAToo may be used in a surgical navigation setting. Conclusion: We present TAToo, which simultaneously tracks the surgical tool and the patient anatomy in skull-base surgery. TAToo directly predicts the motion from surgical videos, without the need of any markers. Our results show that the performance of TAToo compares favorably to competing approaches. Future work will include fine-tuning of our depth network to reach a 1 mm clinical accuracy goal desired for surgical applications in the skull base.
Twin-S: A Digital Twin for Skull-base Surgery
Nov 21, 2022



Purpose: Digital twins are virtual interactive models of the real world, exhibiting identical behavior and properties. In surgical applications, computational analysis from digital twins can be used, for example, to enhance situational awareness. Methods: We present a digital twin framework for skull-base surgeries, named Twin-S, which can be integrated within various image-guided interventions seamlessly. Twin-S combines high-precision optical tracking and real-time simulation. We rely on rigorous calibration routines to ensure that the digital twin representation precisely mimics all real-world processes. Twin-S models and tracks the critical components of skull-base surgery, including the surgical tool, patient anatomy, and surgical camera. Significantly, Twin-S updates and reflects real-world drilling of the anatomical model in frame rate. Results: We extensively evaluate the accuracy of Twin-S, which achieves an average 1.39 mm error during the drilling process. We further illustrate how segmentation masks derived from the continuously updated digital twin can augment the surgical microscope view in a mixed reality setting, where bone requiring ablation is highlighted to provide surgeons additional situational awareness. Conclusion: We present Twin-S, a digital twin environment for skull-base surgery. Twin-S tracks and updates the virtual model in real-time given measurements from modern tracking technologies. Future research on complementing optical tracking with higher-precision vision-based approaches may further increase the accuracy of Twin-S.
Q-LSTM Language Model -- Decentralized Quantum Multilingual Pre-Trained Language Model for Privacy Protection
Oct 06, 2022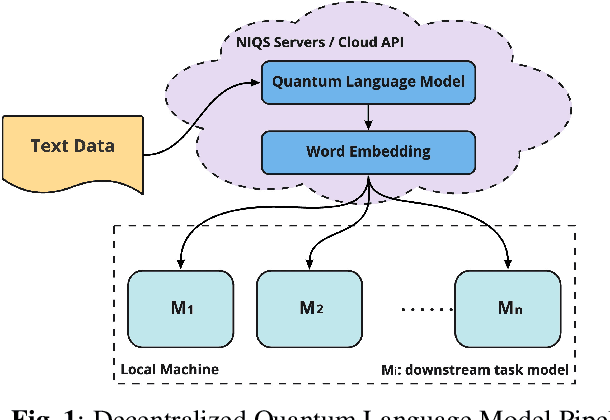

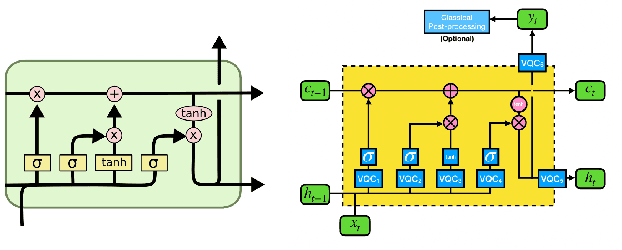
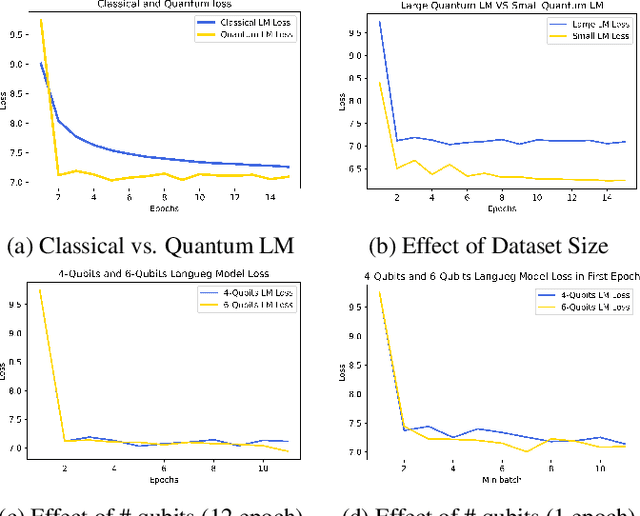
Large-scale language models are trained on a massive amount of natural language data that might encode or reflect our private information. With careful manipulation, malicious agents can reverse engineer the training data even if data sanitation and differential privacy algorithms were involved in the pre-training process. In this work, we propose a decentralized training framework to address privacy concerns in training large-scale language models. The framework consists of a cloud quantum language model built with Variational Quantum Classifiers (VQC) for sentence embedding and a local Long-Short Term Memory (LSTM) model. We use both intrinsic evaluation (loss, perplexity) and extrinsic evaluation (downstream sentiment analysis task) to evaluate the performance of our quantum language model. Our quantum model was comparable to its classical counterpart on all the above metrics. We also perform ablation studies to look into the effect of the size of VQC and the size of training data on the performance of the model. Our approach solves privacy concerns without sacrificing downstream task performance. The intractability of quantum operations on classical hardware ensures the confidentiality of the training data and makes it impossible to be recovered by any adversary.