 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen More Thinking Hurts: Overthinking in LLM Test-Time Compute Scaling
Apr 12, 2026Scaling test-time compute through extended chains of thought has become a dominant paradigm for improving large language model reasoning. However, existing research implicitly assumes that longer thinking always yields better results. This assumption remains largely unexamined. We systematically investigate how the marginal utility of additional reasoning tokens changes as compute budgets increase. We find that marginal returns diminish substantially at higher budgets and that models exhibit ``overthinking'', where extended reasoning is associated with abandoning previously correct answers. Furthermore, we show that optimal thinking length varies across problem difficulty, suggesting that uniform compute allocation is suboptimal. Our cost-aware evaluation framework reveals that stopping at moderate budgets can reduce computation significantly while maintaining comparable accuracy.
The Master-Slave Encoder Model for Improving Patent Text Summarization: A New Approach to Combining Specifications and Claims
Nov 21, 2024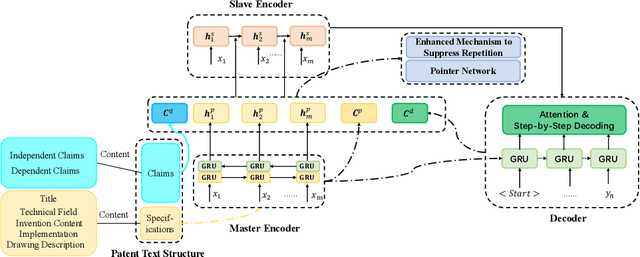



In order to solve the problem of insufficient generation quality caused by traditional patent text abstract generation models only originating from patent specifications, the problem of new terminology OOV caused by rapid patent updates, and the problem of information redundancy caused by insufficient consideration of the high professionalism, accuracy, and uniqueness of patent texts, we proposes a patent text abstract generation model (MSEA) based on a master-slave encoder architecture; Firstly, the MSEA model designs a master-slave encoder, which combines the instructions in the patent text with the claims as input, and fully explores the characteristics and details between the two through the master-slave encoder; Then, the model enhances the consideration of new technical terms in the input sequence based on the pointer network, and further enhances the correlation with the input text by re weighing the "remembered" and "for-gotten" parts of the input sequence from the encoder; Finally, an enhanced repetition suppression mechanism for patent text was introduced to ensure accurate and non redundant abstracts generated. On a publicly available patent text dataset, compared to the state-of-the-art model, Improved Multi-Head Attention Mechanism (IMHAM), the MSEA model achieves an improvement of 0.006, 0.005, and 0.005 in Rouge-1, Rouge-2, and Rouge-L scores, respectively. MSEA leverages the characteristics of patent texts to effectively enhance the quality of patent text generation, demonstrating its advancement and effectiveness in the experiments.
CLIPC8: Face liveness detection algorithm based on image-text pairs and contrastive learning
Nov 29, 2023

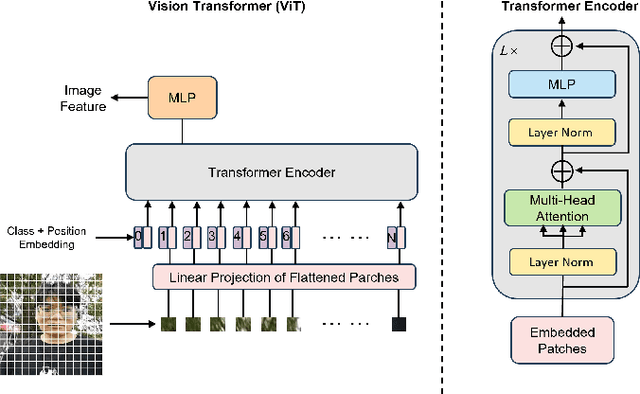

Face recognition technology is widely used in the financial field, and various types of liveness attack behaviors need to be addressed. Existing liveness detection algorithms are trained on specific training datasets and tested on testing datasets, but their performance and robustness in transferring to unseen datasets are relatively poor. To tackle this issue, we propose a face liveness detection method based on image-text pairs and contrastive learning, dividing liveness attack problems in the financial field into eight categories and using text information to describe the images of these eight types of attacks. The text encoder and image encoder are used to extract feature vector representations for the classification description text and face images, respectively. By maximizing the similarity of positive samples and minimizing the similarity of negative samples, the model learns shared representations between images and texts. The proposed method is capable of effectively detecting specific liveness attack behaviors in certain scenarios, such as those occurring in dark environments or involving the tampering of ID card photos. Additionally, it is also effective in detecting traditional liveness attack methods, such as printing photo attacks and screen remake attacks. The zero-shot capabilities of face liveness detection on five public datasets, including NUAA, CASIA-FASD, Replay-Attack, OULU-NPU and MSU-MFSD also reaches the level of commercial algorithms. The detection capability of proposed algorithm was verified on 5 types of testing datasets, and the results show that the method outperformed commercial algorithms, and the detection rates reached 100% on multiple datasets. Demonstrating the effectiveness and robustness of introducing image-text pairs and contrastive learning into liveness detection tasks as proposed in this paper.
Q-LSTM Language Model -- Decentralized Quantum Multilingual Pre-Trained Language Model for Privacy Protection
Oct 06, 2022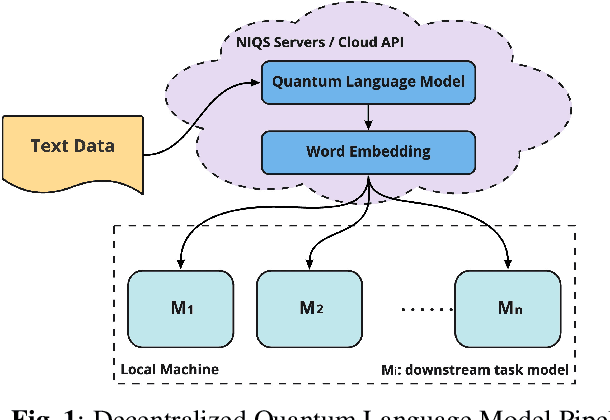

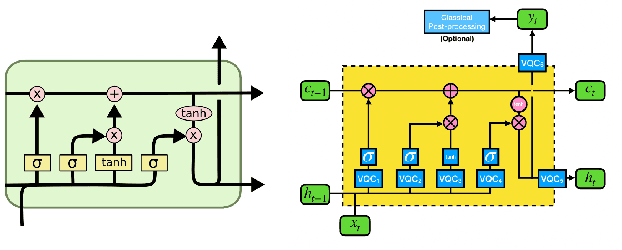
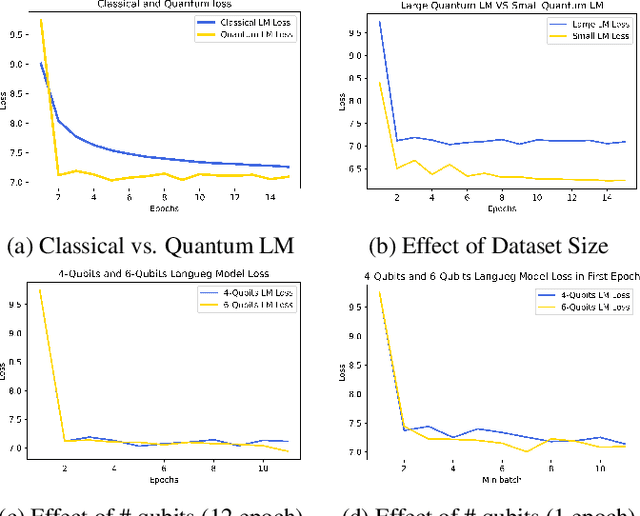
Large-scale language models are trained on a massive amount of natural language data that might encode or reflect our private information. With careful manipulation, malicious agents can reverse engineer the training data even if data sanitation and differential privacy algorithms were involved in the pre-training process. In this work, we propose a decentralized training framework to address privacy concerns in training large-scale language models. The framework consists of a cloud quantum language model built with Variational Quantum Classifiers (VQC) for sentence embedding and a local Long-Short Term Memory (LSTM) model. We use both intrinsic evaluation (loss, perplexity) and extrinsic evaluation (downstream sentiment analysis task) to evaluate the performance of our quantum language model. Our quantum model was comparable to its classical counterpart on all the above metrics. We also perform ablation studies to look into the effect of the size of VQC and the size of training data on the performance of the model. Our approach solves privacy concerns without sacrificing downstream task performance. The intractability of quantum operations on classical hardware ensures the confidentiality of the training data and makes it impossible to be recovered by any adversary.