 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel open-source ultrasound dataset with deep learning benchmarks for spinal cord injury localization and anatomical segmentation
Sep 24, 2024



While deep learning has catalyzed breakthroughs across numerous domains, its broader adoption in clinical settings is inhibited by the costly and time-intensive nature of data acquisition and annotation. To further facilitate medical machine learning, we present an ultrasound dataset of 10,223 Brightness-mode (B-mode) images consisting of sagittal slices of porcine spinal cords (N=25) before and after a contusion injury. We additionally benchmark the performance metrics of several state-of-the-art object detection algorithms to localize the site of injury and semantic segmentation models to label the anatomy for comparison and creation of task-specific architectures. Finally, we evaluate the zero-shot generalization capabilities of the segmentation models on human ultrasound spinal cord images to determine whether training on our porcine dataset is sufficient for accurately interpreting human data. Our results show that the YOLOv8 detection model outperforms all evaluated models for injury localization, achieving a mean Average Precision (mAP50-95) score of 0.606. Segmentation metrics indicate that the DeepLabv3 segmentation model achieves the highest accuracy on unseen porcine anatomy, with a Mean Dice score of 0.587, while SAMed achieves the highest Mean Dice score generalizing to human anatomy (0.445). To the best of our knowledge, this is the largest annotated dataset of spinal cord ultrasound images made publicly available to researchers and medical professionals, as well as the first public report of object detection and segmentation architectures to assess anatomical markers in the spinal cord for methodology development and clinical applications.
SegSTRONG-C: Segmenting Surgical Tools Robustly On Non-adversarial Generated Corruptions -- An EndoVis'24 Challenge
Jul 16, 2024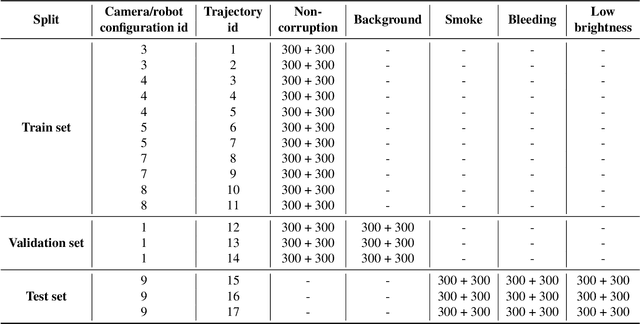


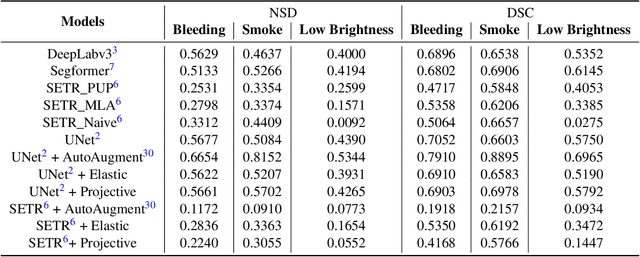
Accurate segmentation of tools in robot-assisted surgery is critical for machine perception, as it facilitates numerous downstream tasks including augmented reality feedback. While current feed-forward neural network-based methods exhibit excellent segmentation performance under ideal conditions, these models have proven susceptible to even minor corruptions, significantly impairing the model's performance. This vulnerability is especially problematic in surgical settings where predictions might be used to inform high-stakes decisions. To better understand model behavior under non-adversarial corruptions, prior work has explored introducing artificial corruptions, like Gaussian noise or contrast perturbation to test set images, to assess model robustness. However, these corruptions are either not photo-realistic or model/task agnostic. Thus, these investigations provide limited insights into model deterioration under realistic surgical corruptions. To address this limitation, we introduce the SegSTRONG-C challenge that aims to promote the development of algorithms robust to unforeseen but plausible image corruptions of surgery, like smoke, bleeding, and low brightness. We collect and release corruption-free mock endoscopic video sequences for the challenge participants to train their algorithms and benchmark them on video sequences with photo-realistic non-adversarial corruptions for a binary robot tool segmentation task. This new benchmark will allow us to carefully study neural network robustness to non-adversarial corruptions of surgery, thus constituting an important first step towards more robust models for surgical computer vision. In this paper, we describe the data collection and annotation protocol, baseline evaluations of established segmentation models, and data augmentation-based techniques to enhance model robustness.
Unidirectional brain-computer interface: Artificial neural network encoding natural images to fMRI response in the visual cortex
Sep 26, 2023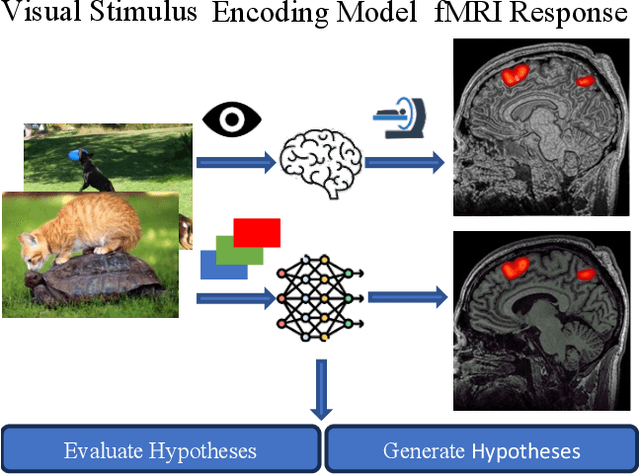

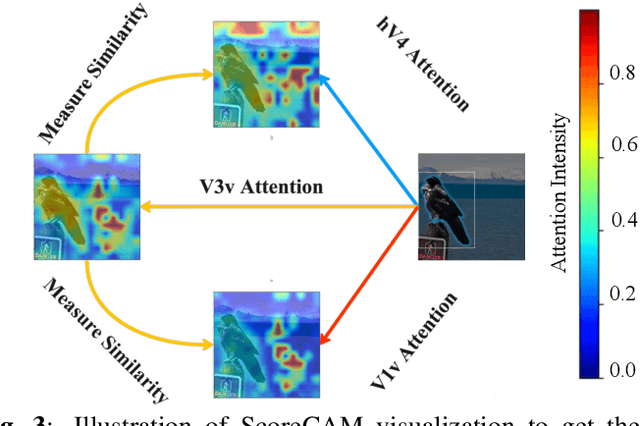
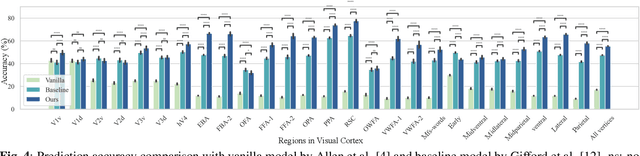
While significant advancements in artificial intelligence (AI) have catalyzed progress across various domains, its full potential in understanding visual perception remains underexplored. We propose an artificial neural network dubbed VISION, an acronym for "Visual Interface System for Imaging Output of Neural activity," to mimic the human brain and show how it can foster neuroscientific inquiries. Using visual and contextual inputs, this multimodal model predicts the brain's functional magnetic resonance imaging (fMRI) scan response to natural images. VISION successfully predicts human hemodynamic responses as fMRI voxel values to visual inputs with an accuracy exceeding state-of-the-art performance by 45%. We further probe the trained networks to reveal representational biases in different visual areas, generate experimentally testable hypotheses, and formulate an interpretable metric to associate these hypotheses with cortical functions. With both a model and evaluation metric, the cost and time burdens associated with designing and implementing functional analysis on the visual cortex could be reduced. Our work suggests that the evolution of computational models may shed light on our fundamental understanding of the visual cortex and provide a viable approach toward reliable brain-machine interfaces.
TAToo: Vision-based Joint Tracking of Anatomy and Tool for Skull-base Surgery
Dec 29, 2022Purpose: Tracking the 3D motion of the surgical tool and the patient anatomy is a fundamental requirement for computer-assisted skull-base surgery. The estimated motion can be used both for intra-operative guidance and for downstream skill analysis. Recovering such motion solely from surgical videos is desirable, as it is compliant with current clinical workflows and instrumentation. Methods: We present Tracker of Anatomy and Tool (TAToo). TAToo jointly tracks the rigid 3D motion of patient skull and surgical drill from stereo microscopic videos. TAToo estimates motion via an iterative optimization process in an end-to-end differentiable form. For robust tracking performance, TAToo adopts a probabilistic formulation and enforces geometric constraints on the object level. Results: We validate TAToo on both simulation data, where ground truth motion is available, as well as on anthropomorphic phantom data, where optical tracking provides a strong baseline. We report sub-millimeter and millimeter inter-frame tracking accuracy for skull and drill, respectively, with rotation errors below 1{\deg}. We further illustrate how TAToo may be used in a surgical navigation setting. Conclusion: We present TAToo, which simultaneously tracks the surgical tool and the patient anatomy in skull-base surgery. TAToo directly predicts the motion from surgical videos, without the need of any markers. Our results show that the performance of TAToo compares favorably to competing approaches. Future work will include fine-tuning of our depth network to reach a 1 mm clinical accuracy goal desired for surgical applications in the skull base.
Twin-S: A Digital Twin for Skull-base Surgery
Nov 21, 2022



Purpose: Digital twins are virtual interactive models of the real world, exhibiting identical behavior and properties. In surgical applications, computational analysis from digital twins can be used, for example, to enhance situational awareness. Methods: We present a digital twin framework for skull-base surgeries, named Twin-S, which can be integrated within various image-guided interventions seamlessly. Twin-S combines high-precision optical tracking and real-time simulation. We rely on rigorous calibration routines to ensure that the digital twin representation precisely mimics all real-world processes. Twin-S models and tracks the critical components of skull-base surgery, including the surgical tool, patient anatomy, and surgical camera. Significantly, Twin-S updates and reflects real-world drilling of the anatomical model in frame rate. Results: We extensively evaluate the accuracy of Twin-S, which achieves an average 1.39 mm error during the drilling process. We further illustrate how segmentation masks derived from the continuously updated digital twin can augment the surgical microscope view in a mixed reality setting, where bone requiring ablation is highlighted to provide surgeons additional situational awareness. Conclusion: We present Twin-S, a digital twin environment for skull-base surgery. Twin-S tracks and updates the virtual model in real-time given measurements from modern tracking technologies. Future research on complementing optical tracking with higher-precision vision-based approaches may further increase the accuracy of Twin-S.
Q-LSTM Language Model -- Decentralized Quantum Multilingual Pre-Trained Language Model for Privacy Protection
Oct 06, 2022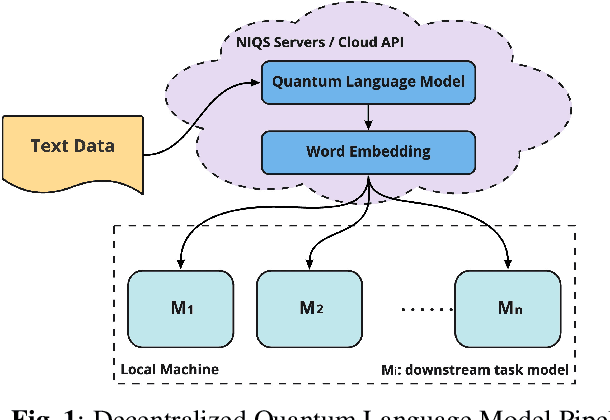

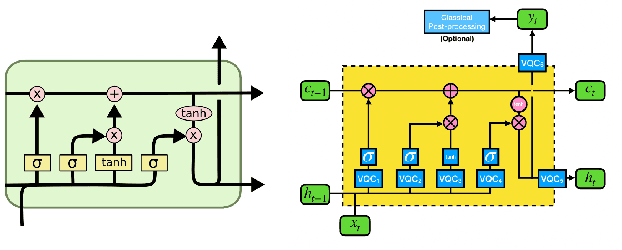
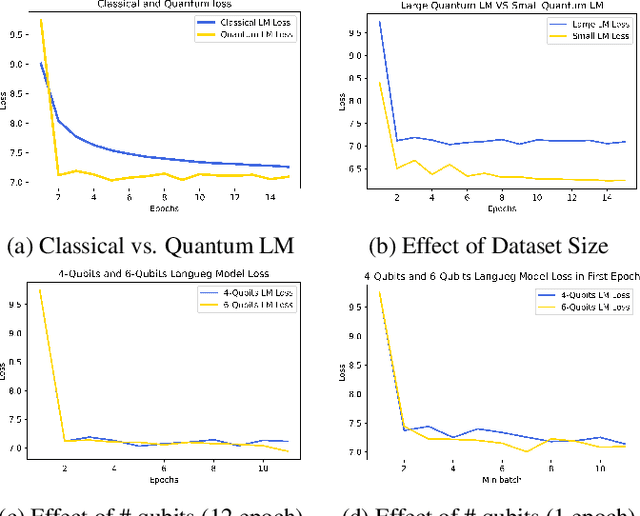
Large-scale language models are trained on a massive amount of natural language data that might encode or reflect our private information. With careful manipulation, malicious agents can reverse engineer the training data even if data sanitation and differential privacy algorithms were involved in the pre-training process. In this work, we propose a decentralized training framework to address privacy concerns in training large-scale language models. The framework consists of a cloud quantum language model built with Variational Quantum Classifiers (VQC) for sentence embedding and a local Long-Short Term Memory (LSTM) model. We use both intrinsic evaluation (loss, perplexity) and extrinsic evaluation (downstream sentiment analysis task) to evaluate the performance of our quantum language model. Our quantum model was comparable to its classical counterpart on all the above metrics. We also perform ablation studies to look into the effect of the size of VQC and the size of training data on the performance of the model. Our approach solves privacy concerns without sacrificing downstream task performance. The intractability of quantum operations on classical hardware ensures the confidentiality of the training data and makes it impossible to be recovered by any adversary.