 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Recognition of Basic Surgical Actions Enables Skill Assessment and Vision-Language-Model-based Surgical Planning
Mar 13, 2026Artificial intelligence, imaging, and large language models have the potential to transform surgical practice, training, and automation. Understanding and modeling of basic surgical actions (BSA), the fundamental unit of operation in any surgery, is important to drive the evolution of this field. In this paper, we present a BSA dataset comprising 10 basic actions across 6 surgical specialties with over 11,000 video clips, which is the largest to date. Based on the BSA dataset, we developed a new foundation model that conducts general-purpose recognition of basic actions. Our approach demonstrates robust cross-specialist performance in experiments validated on datasets from different procedural types and various body parts. Furthermore, we demonstrate downstream applications enabled by the BAS foundation model through surgical skill assessment in prostatectomy using domain-specific knowledge, and action planning in cholecystectomy and nephrectomy using large vision-language models. Multinational surgeons' evaluation of the language model's output of the action planning explainable texts demonstrated clinical relevance. These findings indicate that basic surgical actions can be robustly recognized across scenarios, and an accurate BSA understanding model can essentially facilitate complex applications and speed up the realization of surgical superintelligence.
Surg-R1: A Hierarchical Reasoning Foundation Model for Scalable and Interpretable Surgical Decision Support with Multi-Center Clinical Validation
Mar 12, 2026Surgical scene understanding demands not only accurate predictions but also interpretable reasoning that surgeons can verify against clinical expertise. However, existing surgical vision-language models generate predictions without reasoning chains, and general-purpose reasoning models fail on compositional surgical tasks without domain-specific knowledge. We present Surg-R1, a surgical Vision-Language Model that addresses this gap through hierarchical reasoning trained via a four-stage pipeline. Our approach introduces three key contributions: (1) a three-level reasoning hierarchy decomposing surgical interpretation into perceptual grounding, relational understanding, and contextual reasoning; (2) the largest surgical chain-of-thought dataset with 320,000 reasoning pairs; and (3) a four-stage training pipeline progressing from supervised fine-tuning to group relative policy optimization and iterative self-improvement. Evaluation on SurgBench, comprising six public benchmarks and six multi-center external validation datasets from five institutions, demonstrates that Surg-R1 achieves the highest Arena Score (64.9%) on public benchmarks versus Gemini 3.0 Pro (46.1%) and GPT-5.1 (37.9%), outperforming both proprietary reasoning models and specialized surgical VLMs on the majority of tasks spanning instrument localization, triplet recognition, phase recognition, action recognition, and critical view of safety assessment, with a 15.2 percentage point improvement over the strongest surgical baseline on external validation.
The Dresden Dataset for 4D Reconstruction of Non-Rigid Abdominal Surgical Scenes
Mar 03, 2026The D4D Dataset provides paired endoscopic video and high-quality structured-light geometry for evaluating 3D reconstruction of deforming abdominal soft tissue in realistic surgical conditions. Data were acquired from six porcine cadaver sessions using a da Vinci Xi stereo endoscope and a Zivid structured-light camera, registered via optical tracking and manually curated iterative alignment methods. Three sequence types - whole deformations, incremental deformations, and moved-camera clips - probe algorithm robustness to non-rigid motion, deformation magnitude, and out-of-view updates. Each clip provides rectified stereo images, per-frame instrument masks, stereo depth, start/end structured-light point clouds, curated camera poses and camera intrinsics. In postprocessing, ICP and semi-automatic registration techniques are used to register data, and instrument masks are created. The dataset enables quantitative geometric evaluation in both visible and occluded regions, alongside photometric view-synthesis baselines. Comprising over 300,000 frames and 369 point clouds across 98 curated recordings, this resource can serve as a comprehensive benchmark for developing and evaluating non-rigid SLAM, 4D reconstruction, and depth estimation methods.
ARport: An Augmented Reality System for Markerless Image-Guided Port Placement in Robotic Surgery
Feb 15, 2026Purpose: Precise port placement is a critical step in robot-assisted surgery, where port configuration influences both visual access to the operative field and instrument maneuverability. To bridge the gap between preoperative planning and intraoperative execution, we present ARport, an augmented reality (AR) system that automatically maps pre-planned trocar layouts onto the patient's body surface, providing intuitive spatial guidance during surgical preparation. Methods: ARport, implemented on an optical see-through head-mounted display (OST-HMD), operates without any external sensors or markers, simplifying setup and enhancing workflow integration. It reconstructs the operative scene from RGB, depth, and pose data captured by the OST-HMD, extracts the patient's body surface using a foundation model, and performs surface-based markerless registration to align preoperative anatomical models to the extracted patient's body surface, enabling in-situ visualization of planned trocar layouts. A demonstration video illustrating the overall workflow is available online. Results: In full-scale human-phantom experiments, ARport accurately overlaid pre-planned trocar sites onto the physical phantom, achieving consistent spatial correspondence between virtual plans and real anatomy. Conclusion: ARport provides a fully marker-free and hardware-minimal solution for visualizing preoperative trocar plans directly on the patient's body surface. The system facilitates efficient intraoperative setup and demonstrates potential for seamless integration into routine clinical workflows.
Learning dissection trajectories from expert surgical videos via imitation learning with equivariant diffusion
Jun 05, 2025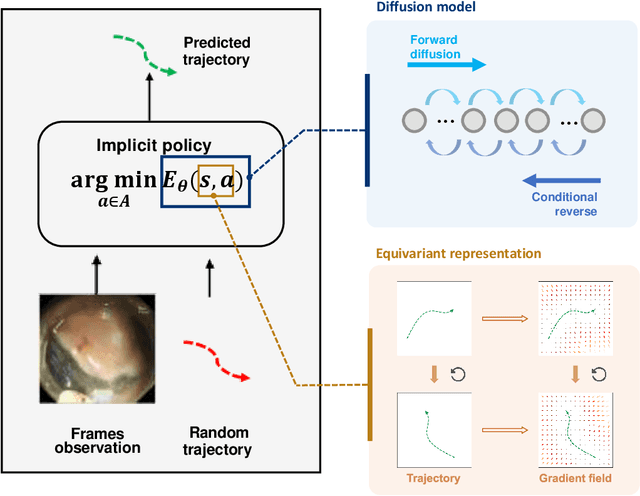
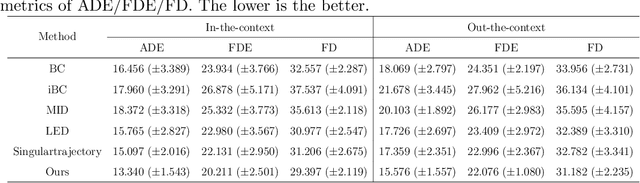
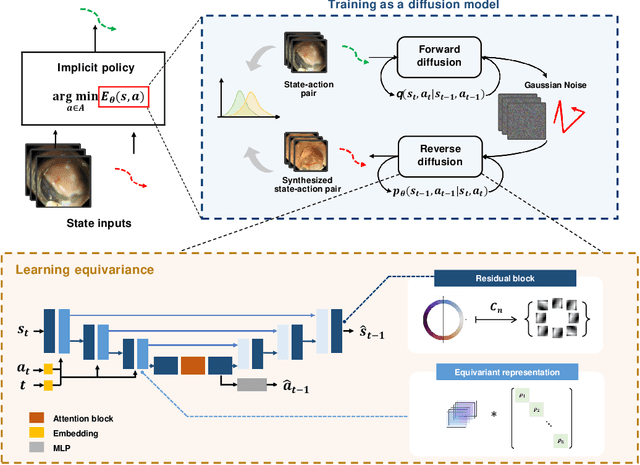
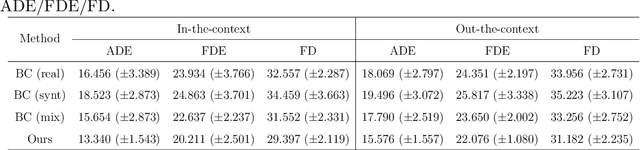
Endoscopic Submucosal Dissection (ESD) is a well-established technique for removing epithelial lesions. Predicting dissection trajectories in ESD videos offers significant potential for enhancing surgical skill training and simplifying the learning process, yet this area remains underexplored. While imitation learning has shown promise in acquiring skills from expert demonstrations, challenges persist in handling uncertain future movements, learning geometric symmetries, and generalizing to diverse surgical scenarios. To address these, we introduce a novel approach: Implicit Diffusion Policy with Equivariant Representations for Imitation Learning (iDPOE). Our method models expert behavior through a joint state action distribution, capturing the stochastic nature of dissection trajectories and enabling robust visual representation learning across various endoscopic views. By incorporating a diffusion model into policy learning, iDPOE ensures efficient training and sampling, leading to more accurate predictions and better generalization. Additionally, we enhance the model's ability to generalize to geometric symmetries by embedding equivariance into the learning process. To address state mismatches, we develop a forward-process guided action inference strategy for conditional sampling. Using an ESD video dataset of nearly 2000 clips, experimental results show that our approach surpasses state-of-the-art methods, both explicit and implicit, in trajectory prediction. To the best of our knowledge, this is the first application of imitation learning to surgical skill development for dissection trajectory prediction.
SegSTRONG-C: Segmenting Surgical Tools Robustly On Non-adversarial Generated Corruptions -- An EndoVis'24 Challenge
Jul 16, 2024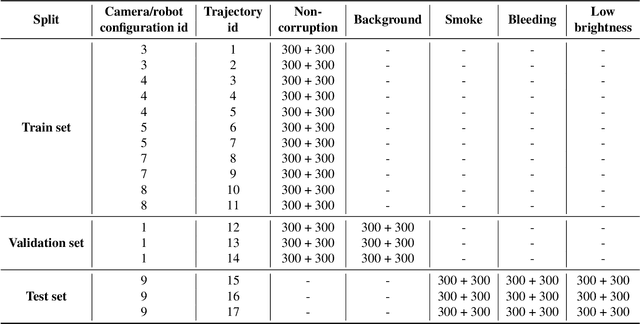


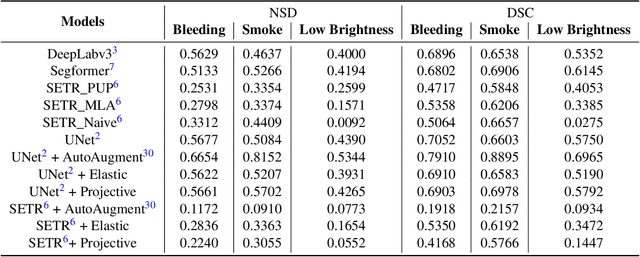
Accurate segmentation of tools in robot-assisted surgery is critical for machine perception, as it facilitates numerous downstream tasks including augmented reality feedback. While current feed-forward neural network-based methods exhibit excellent segmentation performance under ideal conditions, these models have proven susceptible to even minor corruptions, significantly impairing the model's performance. This vulnerability is especially problematic in surgical settings where predictions might be used to inform high-stakes decisions. To better understand model behavior under non-adversarial corruptions, prior work has explored introducing artificial corruptions, like Gaussian noise or contrast perturbation to test set images, to assess model robustness. However, these corruptions are either not photo-realistic or model/task agnostic. Thus, these investigations provide limited insights into model deterioration under realistic surgical corruptions. To address this limitation, we introduce the SegSTRONG-C challenge that aims to promote the development of algorithms robust to unforeseen but plausible image corruptions of surgery, like smoke, bleeding, and low brightness. We collect and release corruption-free mock endoscopic video sequences for the challenge participants to train their algorithms and benchmark them on video sequences with photo-realistic non-adversarial corruptions for a binary robot tool segmentation task. This new benchmark will allow us to carefully study neural network robustness to non-adversarial corruptions of surgery, thus constituting an important first step towards more robust models for surgical computer vision. In this paper, we describe the data collection and annotation protocol, baseline evaluations of established segmentation models, and data augmentation-based techniques to enhance model robustness.
Multi-objective Cross-task Learning via Goal-conditioned GPT-based Decision Transformers for Surgical Robot Task Automation
May 29, 2024



Surgical robot task automation has been a promising research topic for improving surgical efficiency and quality. Learning-based methods have been recognized as an interesting paradigm and been increasingly investigated. However, existing approaches encounter difficulties in long-horizon goal-conditioned tasks due to the intricate compositional structure, which requires decision-making for a sequence of sub-steps and understanding of inherent dynamics of goal-reaching tasks. In this paper, we propose a new learning-based framework by leveraging the strong reasoning capability of the GPT-based architecture to automate surgical robotic tasks. The key to our approach is developing a goal-conditioned decision transformer to achieve sequential representations with goal-aware future indicators in order to enhance temporal reasoning. Moreover, considering to exploit a general understanding of dynamics inherent in manipulations, thus making the model's reasoning ability to be task-agnostic, we also design a cross-task pretraining paradigm that uses multiple training objectives associated with data from diverse tasks. We have conducted extensive experiments on 10 tasks using the surgical robot learning simulator SurRoL~\cite{long2023human}. The results show that our new approach achieves promising performance and task versatility compared to existing methods. The learned trajectories can be deployed on the da Vinci Research Kit (dVRK) for validating its practicality in real surgical robot settings. Our project website is at: https://med-air.github.io/SurRoL.
Efficient Data-driven Scene Simulation using Robotic Surgery Videos via Physics-embedded 3D Gaussians
May 02, 2024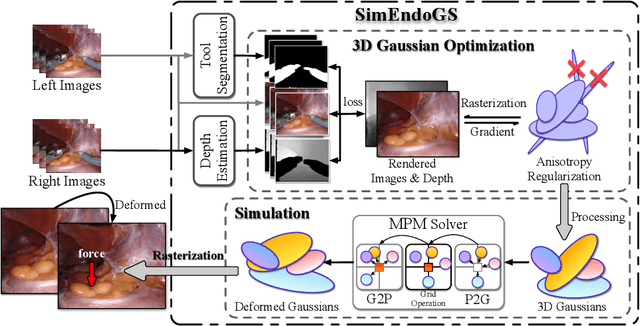

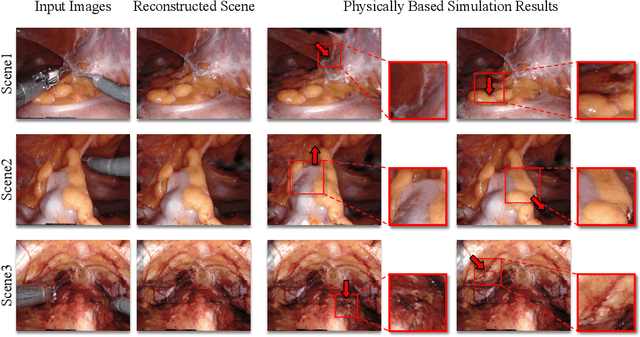
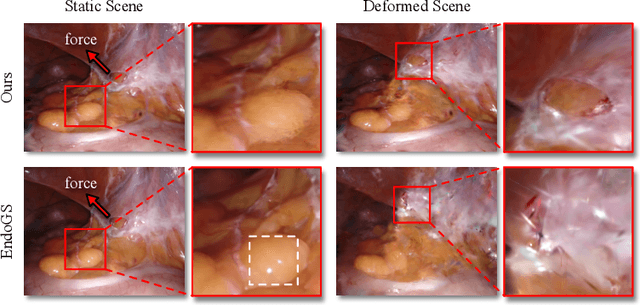
Surgical scene simulation plays a crucial role in surgical education and simulator-based robot learning. Traditional approaches for creating these environments with surgical scene involve a labor-intensive process where designers hand-craft tissues models with textures and geometries for soft body simulations. This manual approach is not only time-consuming but also limited in the scalability and realism. In contrast, data-driven simulation offers a compelling alternative. It has the potential to automatically reconstruct 3D surgical scenes from real-world surgical video data, followed by the application of soft body physics. This area, however, is relatively uncharted. In our research, we introduce 3D Gaussian as a learnable representation for surgical scene, which is learned from stereo endoscopic video. To prevent over-fitting and ensure the geometrical correctness of these scenes, we incorporate depth supervision and anisotropy regularization into the Gaussian learning process. Furthermore, we apply the Material Point Method, which is integrated with physical properties, to the 3D Gaussians to achieve realistic scene deformations. Our method was evaluated on our collected in-house and public surgical videos datasets. Results show that it can reconstruct and simulate surgical scenes from endoscopic videos efficiently-taking only a few minutes to reconstruct the surgical scene-and produce both visually and physically plausible deformations at a speed approaching real-time. The results demonstrate great potential of our proposed method to enhance the efficiency and variety of simulations available for surgical education and robot learning.
Efficient Physically-based Simulation of Soft Bodies in Embodied Environment for Surgical Robot
Feb 02, 2024Surgical robot simulation platform plays a crucial role in enhancing training efficiency and advancing research on robot learning. Much effort have been made by scholars on developing open-sourced surgical robot simulators to facilitate research. We also developed SurRoL formerly, an open-source, da Vinci Research Kit (dVRK) compatible and interactive embodied environment for robot learning. Despite its advancements, the simulation of soft bodies still remained a major challenge within the open-source platforms available for surgical robotics. To this end, we develop an interactive physically based soft body simulation framework and integrate it to SurRoL. Specifically, we utilized a high-performance adaptation of the Material Point Method (MPM) along with the Neo-Hookean model to represent the deformable tissue. Lagrangian particles are used to track the motion and deformation of the soft body throughout the simulation and Eulerian grids are leveraged to discretize space and facilitate the calculation of forces, velocities, and other physical quantities. We also employed an efficient collision detection and handling strategy to simulate the interaction between soft body and rigid tool of the surgical robot. By employing the Taichi programming language, our implementation harnesses parallel computing to boost simulation speed. Experimental results show that our platform is able to simulate soft bodies efficiently with strong physical interpretability and plausible visual effects. These new features in SurRoL enable the efficient simulation of surgical tasks involving soft tissue manipulation and pave the path for further investigation of surgical robot learning. The code will be released in a new branch of SurRoL github repo.
Visual-Kinematics Graph Learning for Procedure-agnostic Instrument Tip Segmentation in Robotic Surgeries
Sep 02, 2023



Accurate segmentation of surgical instrument tip is an important task for enabling downstream applications in robotic surgery, such as surgical skill assessment, tool-tissue interaction and deformation modeling, as well as surgical autonomy. However, this task is very challenging due to the small sizes of surgical instrument tips, and significant variance of surgical scenes across different procedures. Although much effort has been made on visual-based methods, existing segmentation models still suffer from low robustness thus not usable in practice. Fortunately, kinematics data from the robotic system can provide reliable prior for instrument location, which is consistent regardless of different surgery types. To make use of such multi-modal information, we propose a novel visual-kinematics graph learning framework to accurately segment the instrument tip given various surgical procedures. Specifically, a graph learning framework is proposed to encode relational features of instrument parts from both image and kinematics. Next, a cross-modal contrastive loss is designed to incorporate robust geometric prior from kinematics to image for tip segmentation. We have conducted experiments on a private paired visual-kinematics dataset including multiple procedures, i.e., prostatectomy, total mesorectal excision, fundoplication and distal gastrectomy on cadaver, and distal gastrectomy on porcine. The leave-one-procedure-out cross validation demonstrated that our proposed multi-modal segmentation method significantly outperformed current image-based state-of-the-art approaches, exceeding averagely 11.2% on Dice.