 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-R1: Enforcing Interpretable and Faithful Vision-language Reasoning via Saliency-map Alignment Reward
Apr 06, 2026Vision-language models (VLMs) have achieved remarkable success across diverse tasks. However, concerns about their trustworthiness persist, particularly regarding tendencies to lean more on textual cues than visual evidence and the risk of producing ungrounded or fabricated responses. To address these issues, we propose Saliency-R1, a framework for improving the interpretability and faithfulness of VLMs reasoning. Specifically, we introduce a novel saliency map technique that efficiently highlights critical image regions contributing to generated tokens without additional computational overhead. This can further be extended to trace how visual information flows through the reasoning process to the final answers, revealing the alignment between the thinking process and the visual context. We use the overlap between the saliency maps and human-annotated bounding boxes as the reward function, and apply Group Relative Policy Optimization (GRPO) to align the salient parts and critical regions, encouraging models to focus on relevant areas when conduct reasoning. Experiments show Saliency-R1 improves reasoning faithfulness, interpretability, and overall task performance.
Surg$Σ$: A Spectrum of Large-Scale Multimodal Data and Foundation Models for Surgical Intelligence
Mar 17, 2026Surgical intelligence has the potential to improve the safety and consistency of surgical care, yet most existing surgical AI frameworks remain task-specific and struggle to generalize across procedures and institutions. Although multimodal foundation models, particularly multimodal large language models, have demonstrated strong cross-task capabilities across various medical domains, their advancement in surgery remains constrained by the lack of large-scale, systematically curated multimodal data. To address this challenge, we introduce Surg$Σ$, a spectrum of large-scale multimodal data and foundation models for surgical intelligence. At the core of this framework lies Surg$Σ$-DB, a large-scale multimodal data foundation designed to support diverse surgical tasks. Surg$Σ$-DB consolidates heterogeneous surgical data sources (including open-source datasets, curated in-house clinical collections and web-source data) into a unified schema, aiming to improve label consistency and data standardization across heterogeneous datasets. Surg$Σ$-DB spans 6 clinical specialties and diverse surgical types, providing rich image- and video-level annotations across 18 practical surgical tasks covering understanding, reasoning, planning, and generation, at an unprecedented scale (over 5.98M conversations). Beyond conventional multimodal conversations, Surg$Σ$-DB incorporates hierarchical reasoning annotations, providing richer semantic cues to support deeper contextual understanding in complex surgical scenarios. We further provide empirical evidence through recently developed surgical foundation models built upon Surg$Σ$-DB, illustrating the practical benefits of large-scale multimodal annotations, unified semantic design, and structured reasoning annotations for improving cross-task generalization and interpretability.
Generalized Recognition of Basic Surgical Actions Enables Skill Assessment and Vision-Language-Model-based Surgical Planning
Mar 13, 2026Artificial intelligence, imaging, and large language models have the potential to transform surgical practice, training, and automation. Understanding and modeling of basic surgical actions (BSA), the fundamental unit of operation in any surgery, is important to drive the evolution of this field. In this paper, we present a BSA dataset comprising 10 basic actions across 6 surgical specialties with over 11,000 video clips, which is the largest to date. Based on the BSA dataset, we developed a new foundation model that conducts general-purpose recognition of basic actions. Our approach demonstrates robust cross-specialist performance in experiments validated on datasets from different procedural types and various body parts. Furthermore, we demonstrate downstream applications enabled by the BAS foundation model through surgical skill assessment in prostatectomy using domain-specific knowledge, and action planning in cholecystectomy and nephrectomy using large vision-language models. Multinational surgeons' evaluation of the language model's output of the action planning explainable texts demonstrated clinical relevance. These findings indicate that basic surgical actions can be robustly recognized across scenarios, and an accurate BSA understanding model can essentially facilitate complex applications and speed up the realization of surgical superintelligence.
Surg-R1: A Hierarchical Reasoning Foundation Model for Scalable and Interpretable Surgical Decision Support with Multi-Center Clinical Validation
Mar 12, 2026Surgical scene understanding demands not only accurate predictions but also interpretable reasoning that surgeons can verify against clinical expertise. However, existing surgical vision-language models generate predictions without reasoning chains, and general-purpose reasoning models fail on compositional surgical tasks without domain-specific knowledge. We present Surg-R1, a surgical Vision-Language Model that addresses this gap through hierarchical reasoning trained via a four-stage pipeline. Our approach introduces three key contributions: (1) a three-level reasoning hierarchy decomposing surgical interpretation into perceptual grounding, relational understanding, and contextual reasoning; (2) the largest surgical chain-of-thought dataset with 320,000 reasoning pairs; and (3) a four-stage training pipeline progressing from supervised fine-tuning to group relative policy optimization and iterative self-improvement. Evaluation on SurgBench, comprising six public benchmarks and six multi-center external validation datasets from five institutions, demonstrates that Surg-R1 achieves the highest Arena Score (64.9%) on public benchmarks versus Gemini 3.0 Pro (46.1%) and GPT-5.1 (37.9%), outperforming both proprietary reasoning models and specialized surgical VLMs on the majority of tasks spanning instrument localization, triplet recognition, phase recognition, action recognition, and critical view of safety assessment, with a 15.2 percentage point improvement over the strongest surgical baseline on external validation.
CubeComposer: Spatio-Temporal Autoregressive 4K 360° Video Generation from Perspective Video
Mar 04, 2026Generating high-quality 360° panoramic videos from perspective input is one of the crucial applications for virtual reality (VR), whereby high-resolution videos are especially important for immersive experience. Existing methods are constrained by computational limitations of vanilla diffusion models, only supporting $\leq$ 1K resolution native generation and relying on suboptimal post super-resolution to increase resolution. We introduce CubeComposer, a novel spatio-temporal autoregressive diffusion model that natively generates 4K-resolution 360° videos. By decomposing videos into cubemap representations with six faces, CubeComposer autoregressively synthesizes content in a well-planned spatio-temporal order, reducing memory demands while enabling high-resolution output. Specifically, to address challenges in multi-dimensional autoregression, we propose: (1) a spatio-temporal autoregressive strategy that orchestrates 360° video generation across cube faces and time windows for coherent synthesis; (2) a cube face context management mechanism, equipped with a sparse context attention design to improve efficiency; and (3) continuity-aware techniques, including cube-aware positional encoding, padding, and blending to eliminate boundary seams. Extensive experiments on benchmark datasets demonstrate that CubeComposer outperforms state-of-the-art methods in native resolution and visual quality, supporting practical VR application scenarios. Project page: https://lg-li.github.io/project/cubecomposer
The Dresden Dataset for 4D Reconstruction of Non-Rigid Abdominal Surgical Scenes
Mar 03, 2026The D4D Dataset provides paired endoscopic video and high-quality structured-light geometry for evaluating 3D reconstruction of deforming abdominal soft tissue in realistic surgical conditions. Data were acquired from six porcine cadaver sessions using a da Vinci Xi stereo endoscope and a Zivid structured-light camera, registered via optical tracking and manually curated iterative alignment methods. Three sequence types - whole deformations, incremental deformations, and moved-camera clips - probe algorithm robustness to non-rigid motion, deformation magnitude, and out-of-view updates. Each clip provides rectified stereo images, per-frame instrument masks, stereo depth, start/end structured-light point clouds, curated camera poses and camera intrinsics. In postprocessing, ICP and semi-automatic registration techniques are used to register data, and instrument masks are created. The dataset enables quantitative geometric evaluation in both visible and occluded regions, alongside photometric view-synthesis baselines. Comprising over 300,000 frames and 369 point clouds across 98 curated recordings, this resource can serve as a comprehensive benchmark for developing and evaluating non-rigid SLAM, 4D reconstruction, and depth estimation methods.
Real-time Monocular 2D and 3D Perception of Endoluminal Scenes for Controlling Flexible Robotic Endoscopic Instruments
Feb 16, 2026Endoluminal surgery offers a minimally invasive option for early-stage gastrointestinal and urinary tract cancers but is limited by surgical tools and a steep learning curve. Robotic systems, particularly continuum robots, provide flexible instruments that enable precise tissue resection, potentially improving outcomes. This paper presents a visual perception platform for a continuum robotic system in endoluminal surgery. Our goal is to utilize monocular endoscopic image-based perception algorithms to identify position and orientation of flexible instruments and measure their distances from tissues. We introduce 2D and 3D learning-based perception algorithms and develop a physically-realistic simulator that models flexible instruments dynamics. This simulator generates realistic endoluminal scenes, enabling control of flexible robots and substantial data collection. Using a continuum robot prototype, we conducted module and system-level evaluations. Results show that our algorithms improve control of flexible instruments, reducing manipulation time by over 70% for trajectory-following tasks and enhancing understanding of surgical scenarios, leading to robust endoluminal surgeries.
ARport: An Augmented Reality System for Markerless Image-Guided Port Placement in Robotic Surgery
Feb 15, 2026Purpose: Precise port placement is a critical step in robot-assisted surgery, where port configuration influences both visual access to the operative field and instrument maneuverability. To bridge the gap between preoperative planning and intraoperative execution, we present ARport, an augmented reality (AR) system that automatically maps pre-planned trocar layouts onto the patient's body surface, providing intuitive spatial guidance during surgical preparation. Methods: ARport, implemented on an optical see-through head-mounted display (OST-HMD), operates without any external sensors or markers, simplifying setup and enhancing workflow integration. It reconstructs the operative scene from RGB, depth, and pose data captured by the OST-HMD, extracts the patient's body surface using a foundation model, and performs surface-based markerless registration to align preoperative anatomical models to the extracted patient's body surface, enabling in-situ visualization of planned trocar layouts. A demonstration video illustrating the overall workflow is available online. Results: In full-scale human-phantom experiments, ARport accurately overlaid pre-planned trocar sites onto the physical phantom, achieving consistent spatial correspondence between virtual plans and real anatomy. Conclusion: ARport provides a fully marker-free and hardware-minimal solution for visualizing preoperative trocar plans directly on the patient's body surface. The system facilitates efficient intraoperative setup and demonstrates potential for seamless integration into routine clinical workflows.
Concepts from Representations: Post-hoc Concept Bottleneck Models via Sparse Decomposition of Visual Representations
Jan 18, 2026Deep learning has achieved remarkable success in image recognition, yet their inherent opacity poses challenges for deployment in critical domains. Concept-based interpretations aim to address this by explaining model reasoning through human-understandable concepts. However, existing post-hoc methods and ante-hoc concept bottleneck models (CBMs), suffer from limitations such as unreliable concept relevance, non-visual or labor-intensive concept definitions, and model or data-agnostic assumptions. This paper introduces Post-hoc Concept Bottleneck Model via Representation Decomposition (PCBM-ReD), a novel pipeline that retrofits interpretability onto pretrained opaque models. PCBM-ReD automatically extracts visual concepts from a pre-trained encoder, employs multimodal large language models (MLLMs) to label and filter concepts based on visual identifiability and task relevance, and selects an independent subset via reconstruction-guided optimization. Leveraging CLIP's visual-text alignment, it decomposes image representations into linear combination of concept embeddings to fit into the CBMs abstraction. Extensive experiments across 11 image classification tasks show PCBM-ReD achieves state-of-the-art accuracy, narrows the performance gap with end-to-end models, and exhibits better interpretability.
DSTED: Decoupling Temporal Stabilization and Discriminative Enhancement for Surgical Workflow Recognition
Dec 22, 2025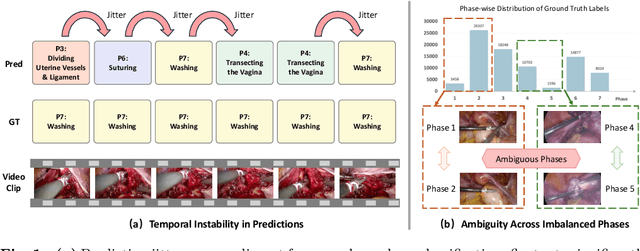
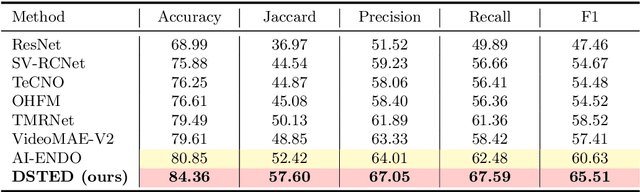
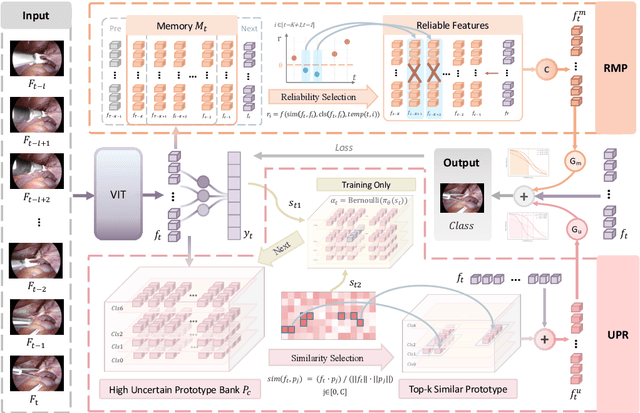
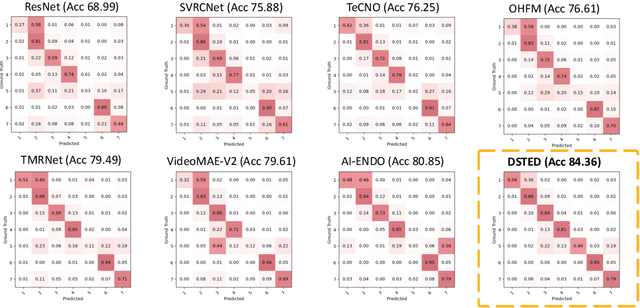
Purpose: Surgical workflow recognition enables context-aware assistance and skill assessment in computer-assisted interventions. Despite recent advances, current methods suffer from two critical challenges: prediction jitter across consecutive frames and poor discrimination of ambiguous phases. This paper aims to develop a stable framework by selectively propagating reliable historical information and explicitly modeling uncertainty for hard sample enhancement. Methods: We propose a dual-pathway framework DSTED with Reliable Memory Propagation (RMP) and Uncertainty-Aware Prototype Retrieval (UPR). RMP maintains temporal coherence by filtering and fusing high-confidence historical features through multi-criteria reliability assessment. UPR constructs learnable class-specific prototypes from high-uncertainty samples and performs adaptive prototype matching to refine ambiguous frame representations. Finally, a confidence-driven gate dynamically balances both pathways based on prediction certainty. Results: Our method achieves state-of-the-art performance on AutoLaparo-hysterectomy with 84.36% accuracy and 65.51% F1-score, surpassing the second-best method by 3.51% and 4.88% respectively. Ablations reveal complementary gains from RMP (2.19%) and UPR (1.93%), with synergistic effects when combined. Extensive analysis confirms substantial reduction in temporal jitter and marked improvement on challenging phase transitions. Conclusion: Our dual-pathway design introduces a novel paradigm for stable workflow recognition, demonstrating that decoupling the modeling of temporal consistency and phase ambiguity yields superior performance and clinical applicability.