 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Ultra-Fast Cardiovascular Imaging Across Heterogeneous Clinical Environments with a Generalist Foundation Model and Multimodal Database
Dec 25, 2025Multimodal cardiovascular magnetic resonance (CMR) imaging provides comprehensive and non-invasive insights into cardiovascular disease (CVD) diagnosis and underlying mechanisms. Despite decades of advancements, its widespread clinical adoption remains constrained by prolonged scan times and heterogeneity across medical environments. This underscores the urgent need for a generalist reconstruction foundation model for ultra-fast CMR imaging, one capable of adapting across diverse imaging scenarios and serving as the essential substrate for all downstream analyses. To enable this goal, we curate MMCMR-427K, the largest and most comprehensive multimodal CMR k-space database to date, comprising 427,465 multi-coil k-space data paired with structured metadata across 13 international centers, 12 CMR modalities, 15 scanners, and 17 CVD categories in populations across three continents. Building on this unprecedented resource, we introduce CardioMM, a generalist reconstruction foundation model capable of dynamically adapting to heterogeneous fast CMR imaging scenarios. CardioMM unifies semantic contextual understanding with physics-informed data consistency to deliver robust reconstructions across varied scanners, protocols, and patient presentations. Comprehensive evaluations demonstrate that CardioMM achieves state-of-the-art performance in the internal centers and exhibits strong zero-shot generalization to unseen external settings. Even at imaging acceleration up to 24x, CardioMM reliably preserves key cardiac phenotypes, quantitative myocardial biomarkers, and diagnostic image quality, enabling a substantial increase in CMR examination throughput without compromising clinical integrity. Together, our open-access MMCMR-427K database and CardioMM framework establish a scalable pathway toward high-throughput, high-quality, and clinically accessible cardiovascular imaging.
Towards Universal Learning-based Model for Cardiac Image Reconstruction: Summary of the CMRxRecon2024 Challenge
Mar 05, 2025Cardiovascular magnetic resonance (CMR) offers diverse imaging contrasts for assessment of cardiac function and tissue characterization. However, acquiring each single CMR modality is often time-consuming, and comprehensive clinical protocols require multiple modalities with various sampling patterns, further extending the overall acquisition time and increasing susceptibility to motion artifacts. Existing deep learning-based reconstruction methods are often designed for specific acquisition parameters, which limits their ability to generalize across a variety of scan scenarios. As part of the CMRxRecon Series, the CMRxRecon2024 challenge provides diverse datasets encompassing multi-modality multi-view imaging with various sampling patterns, and a platform for the international community to develop and benchmark reconstruction solutions in two well-crafted tasks. Task 1 is a modality-universal setting, evaluating the out-of-distribution generalization of the reconstructed model, while Task 2 follows sampling-universal setting assessing the one-for-all adaptability of the universal model. Main contributions include providing the first and largest publicly available multi-modality, multi-view cardiac k-space dataset; developing a benchmarking platform that simulates clinical acceleration protocols, with a shared code library and tutorial for various k-t undersampling patterns and data processing; giving technical insights of enhanced data consistency based on physic-informed networks and adaptive prompt-learning embedding to be versatile to different clinical settings; additional finding on evaluation metrics to address the limitations of conventional ground-truth references in universal reconstruction tasks.
FaceScape: 3D Facial Dataset and Benchmark for Single-View 3D Face Reconstruction
Nov 01, 2021
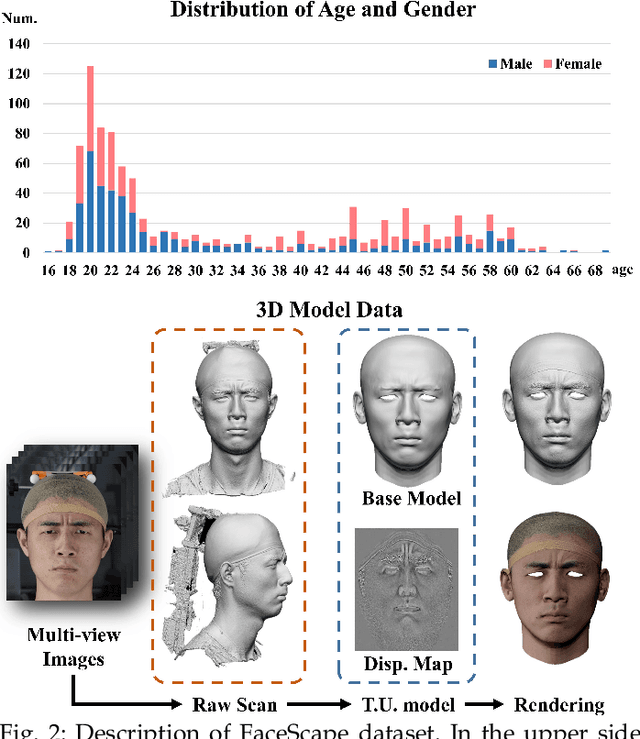
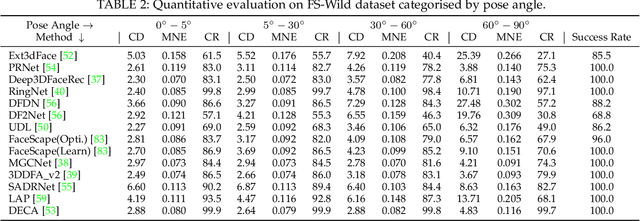
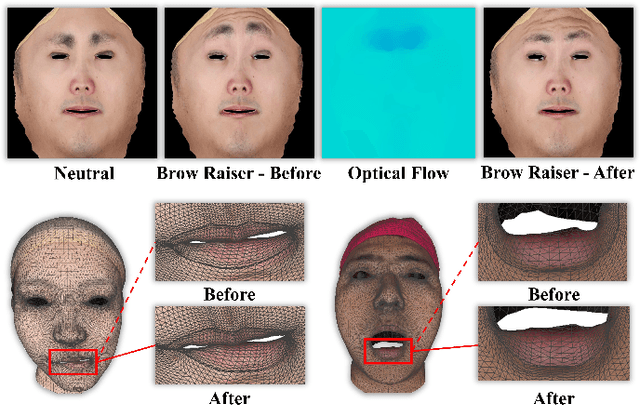
In this paper, we present a large-scale detailed 3D face dataset, FaceScape, and the corresponding benchmark to evaluate single-view facial 3D reconstruction. By training on FaceScape data, a novel algorithm is proposed to predict elaborate riggable 3D face models from a single image input. FaceScape dataset provides 18,760 textured 3D faces, captured from 938 subjects and each with 20 specific expressions. The 3D models contain the pore-level facial geometry that is also processed to be topologically uniformed. These fine 3D facial models can be represented as a 3D morphable model for rough shapes and displacement maps for detailed geometry. Taking advantage of the large-scale and high-accuracy dataset, a novel algorithm is further proposed to learn the expression-specific dynamic details using a deep neural network. The learned relationship serves as the foundation of our 3D face prediction system from a single image input. Different than the previous methods, our predicted 3D models are riggable with highly detailed geometry under different expressions. We also use FaceScape data to generate the in-the-wild and in-the-lab benchmark to evaluate recent methods of single-view face reconstruction. The accuracy is reported and analyzed on the dimensions of camera pose and focal length, which provides a faithful and comprehensive evaluation and reveals new challenges. The unprecedented dataset, benchmark, and code have been released to the public for research purpose.
Hybrid Differentially Private Federated Learning on Vertically Partitioned Data
Sep 06, 2020
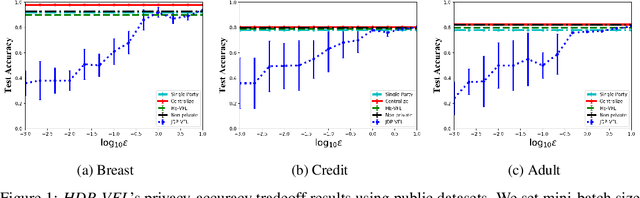
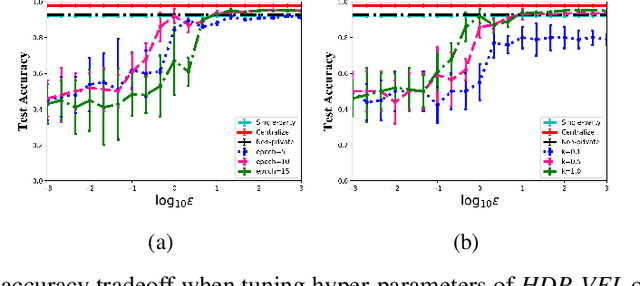

We present HDP-VFL, the first hybrid differentially private (DP) framework for vertical federated learning (VFL) to demonstrate that it is possible to jointly learn a generalized linear model (GLM) from vertically partitioned data with only a negligible cost, w.r.t. training time, accuracy, etc., comparing to idealized non-private VFL. Our work builds on the recent advances in VFL-based collaborative training among different organizations which rely on protocols like Homomorphic Encryption (HE) and Secure Multi-Party Computation (MPC) to secure computation and training. In particular, we analyze how VFL's intermediate result (IR) can leak private information of the training data during communication and design a DP-based privacy-preserving algorithm to ensure the data confidentiality of VFL participants. We mathematically prove that our algorithm not only provides utility guarantees for VFL, but also offers multi-level privacy, i.e. DP w.r.t. IR and joint differential privacy (JDP) w.r.t. model weights. Experimental results demonstrate that our work, under adequate privacy budgets, is quantitatively and qualitatively similar to GLMs, learned in idealized non-private VFL setting, rather than the increased cost in memory and processing time in most prior works based on HE or MPC. Our codes will be released if this paper is accepted.
A Federated Multi-View Deep Learning Framework for Privacy-Preserving Recommendations
Aug 25, 2020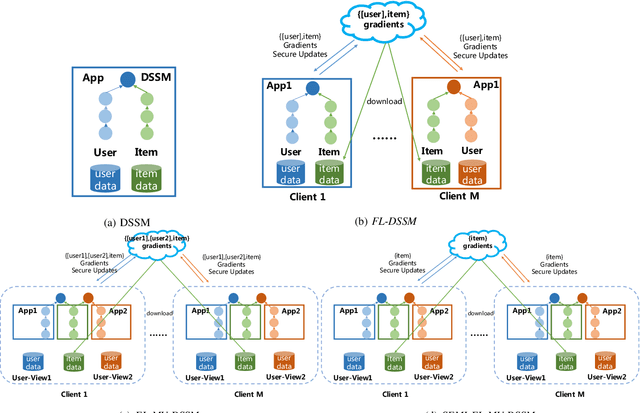
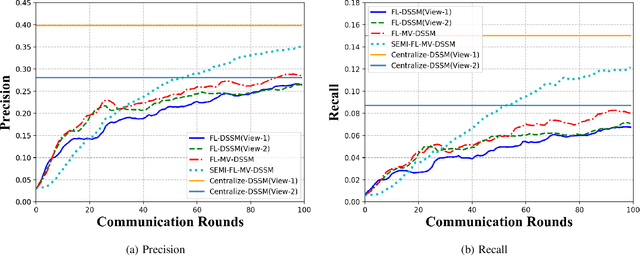


Privacy-preserving recommendations are recently gaining momentum, since the decentralized user data is increasingly harder to collect, by recommendation service providers, due to the serious concerns over user privacy and data security. This situation is further exacerbated by the strict government regulations such as Europe's General Data Privacy Regulations(GDPR). Federated Learning(FL) is a newly developed privacy-preserving machine learning paradigm to bridge data repositories without compromising data security and privacy. Thus many federated recommendation(FedRec) algorithms have been proposed to realize personalized privacy-preserving recommendations. However, existing FedRec algorithms, mostly extended from traditional collaborative filtering(CF) method, cannot address cold-start problem well. In addition, their performance overhead w.r.t. model accuracy, trained in a federated setting, is often non-negligible comparing to centralized recommendations. This paper studies this issue and presents FL-MV-DSSM, a generic content-based federated multi-view recommendation framework that not only addresses the cold-start problem, but also significantly boosts the recommendation performance by learning a federated model from multiple data source for capturing richer user-level features. The new federated multi-view setting, proposed by FL-MV-DSSM, opens new usage models and brings in new security challenges to FL in recommendation scenarios. We prove the security guarantees of \xxx, and empirical evaluations on FL-MV-DSSM and its variations with public datasets demonstrate its effectiveness. Our codes will be released if this paper is accepted.
FaceScape: a Large-scale High Quality 3D Face Dataset and Detailed Riggable 3D Face Prediction
Apr 21, 2020

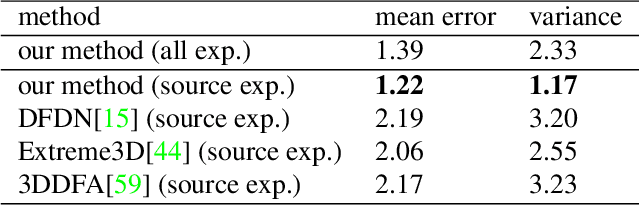
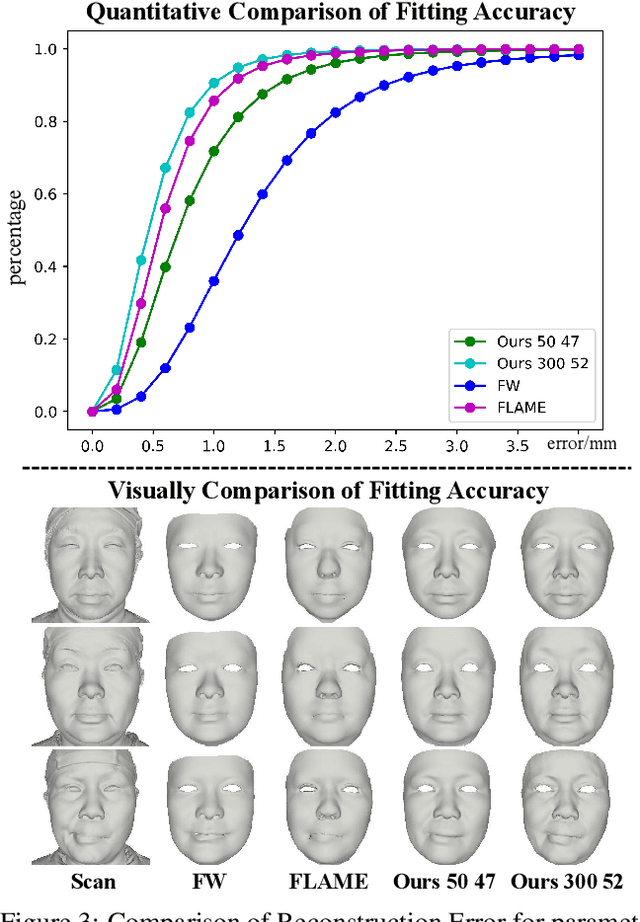
In this paper, we present a large-scale detailed 3D face dataset, FaceScape, and propose a novel algorithm that is able to predict elaborate riggable 3D face models from a single image input. FaceScape dataset provides 18,760 textured 3D faces, captured from 938 subjects and each with 20 specific expressions. The 3D models contain the pore-level facial geometry that is also processed to be topologically uniformed. These fine 3D facial models can be represented as a 3D morphable model for rough shapes and displacement maps for detailed geometry. Taking advantage of the large-scale and high-accuracy dataset, a novel algorithm is further proposed to learn the expression-specific dynamic details using a deep neural network. The learned relationship serves as the foundation of our 3D face prediction system from a single image input. Different than the previous methods, our predicted 3D models are riggable with highly detailed geometry under different expressions. The unprecedented dataset and code will be released to public for research purpose.