 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Anomaly-guided Ego-graph Diffusion Model for Inductive Graph Anomaly Detection
Feb 05, 2026Graph anomaly detection (GAD) is crucial in applications like fraud detection and cybersecurity. Despite recent advancements using graph neural networks (GNNs), two major challenges persist. At the model level, most methods adopt a transductive learning paradigm, which assumes static graph structures, making them unsuitable for dynamic, evolving networks. At the data level, the extreme class imbalance, where anomalous nodes are rare, leads to biased models that fail to generalize to unseen anomalies. These challenges are interdependent: static transductive frameworks limit effective data augmentation, while imbalance exacerbates model distortion in inductive learning settings. To address these challenges, we propose a novel data-centric framework that integrates dynamic graph modeling with balanced anomaly synthesis. Our framework features: (1) a discrete ego-graph diffusion model, which captures the local topology of anomalies to generate ego-graphs aligned with anomalous structural distribution, and (2) a curriculum anomaly augmentation mechanism, which dynamically adjusts synthetic data generation during training, focusing on underrepresented anomaly patterns to improve detection and generalization. Experiments on five datasets demonstrate that the effectiveness of our framework.
Diffusion Epistemic Uncertainty with Asymmetric Learning for Diffusion-Generated Image Detection
Jan 21, 2026The rapid progress of diffusion models highlights the growing need for detecting generated images. Previous research demonstrates that incorporating diffusion-based measurements, such as reconstruction error, can enhance the generalizability of detectors. However, ignoring the differing impacts of aleatoric and epistemic uncertainty on reconstruction error can undermine detection performance. Aleatoric uncertainty, arising from inherent data noise, creates ambiguity that impedes accurate detection of generated images. As it reflects random variations within the data (e.g., noise in natural textures), it does not help distinguish generated images. In contrast, epistemic uncertainty, which represents the model's lack of knowledge about unfamiliar patterns, supports detection. In this paper, we propose a novel framework, Diffusion Epistemic Uncertainty with Asymmetric Learning~(DEUA), for detecting diffusion-generated images. We introduce Diffusion Epistemic Uncertainty~(DEU) estimation via the Laplace approximation to assess the proximity of data to the manifold of diffusion-generated samples. Additionally, an asymmetric loss function is introduced to train a balanced classifier with larger margins, further enhancing generalizability. Extensive experiments on large-scale benchmarks validate the state-of-the-art performance of our method.
MPCOM: Robotic Data Gathering with Radio Mapping and Model Predictive Communication
Apr 16, 2024Robotic data gathering (RDG) is an emerging paradigm that navigates a robot to harvest data from remote sensors. However, motion planning in this paradigm needs to maximize the RDG efficiency instead of the navigation efficiency, for which the existing motion planning methods become inefficient, as they plan robot trajectories merely according to motion factors. This paper proposes radio map guided model predictive communication (MPCOM), which navigates the robot with both grid and radio maps for shape-aware collision avoidance and communication-aware trajectory generation in a dynamic environment. The proposed MPCOM is able to trade off the time spent on reaching goal, avoiding collision, and improving communication. MPCOM captures high-order signal propagation characteristics using radio maps and incorporates the map-guided communication regularizer to the motion planning block. Experiments in IRSIM and CARLA simulators show that the proposed MPCOM outperforms other benchmarks in both LOS and NLOS cases. Real-world testing based on car-like robots is also provided to demonstrate the effectiveness of MPCOM in indoor environments.
A Virtual Reality Training System for Automotive Engines Assembly and Disassembly
Nov 02, 2023



Automotive engine assembly and disassembly are common and crucial programs in the automotive industry. Traditional education trains students to learn automotive engine assembly and disassembly in lecture courses and then to operate with physical engines, which are generally low effectiveness and high cost. In this work, we developed a multi-layer structured Virtual Reality (VR) system to provide students with training in automotive engine (Buick Verano) assembly and disassembly. We designed the VR training system with The VR training system is designed to have several major features, including replaceable engine parts and reusable tools, friendly user interfaces and guidance, and bottom-up designed multi-layer architecture, which can be extended to various engine models. The VR system is evaluated with controlled experiments of two groups of students. The results demonstrate that our VR training system provides remarkable usability in terms of effectiveness and efficiency. Currently, our VR system has been demonstrated and employed in the courses of Chinese colleges to train students in automotive engine assembly and disassembly. A free-to-use executable file (Microsoft Windows) and open-source code are available at https://github.com/LadissonLai/SUSTech_VREngine for facilitating the development of VR systems in the automotive industry. Finally, a video describing the operations in our VR training system is available at https://www.youtube.com/watch?v=yZe4YTwwAC4
A Novel Convolutional Neural Network Architecture with a Continuous Symmetry
Aug 09, 2023



This paper introduces a new Convolutional Neural Network (ConvNet) architecture inspired by a class of partial differential equations (PDEs) called quasi-linear hyperbolic systems. With comparable performance on the image classification task, it allows for the modification of the weights via a continuous group of symmetry. This is a significant shift from traditional models where the architecture and weights are essentially fixed. We wish to promote the (internal) symmetry as a new desirable property for a neural network, and to draw attention to the PDE perspective in analyzing and interpreting ConvNets in the broader Deep Learning community.
Integrated Photonic Reservoir Computing with All-Optical Readout
Jun 28, 2023



Integrated photonic reservoir computing has been demonstrated to be able to tackle different problems because of its neural network nature. A key advantage of photonic reservoir computing over other neuromorphic paradigms is its straightforward readout system, which facilitates both rapid training and robust, fabrication variation-insensitive photonic integrated hardware implementation for real-time processing. We present our recent development of a fully-optical, coherent photonic reservoir chip integrated with an optical readout system, capitalizing on these benefits. Alongside the integrated system, we also demonstrate a weight update strategy that is suitable for the integrated optical readout hardware. Using this online training scheme, we successfully solved 3-bit header recognition and delayed XOR tasks at 20 Gbps in real-time, all within the optical domain without excess delays.
Uncertainty-Aware Learning Against Label Noise on Imbalanced Datasets
Jul 12, 2022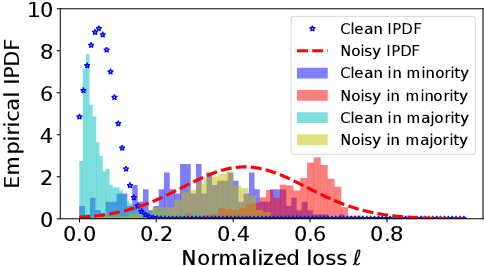
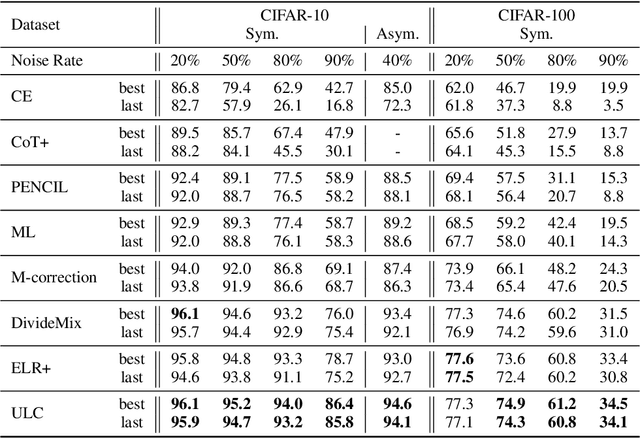
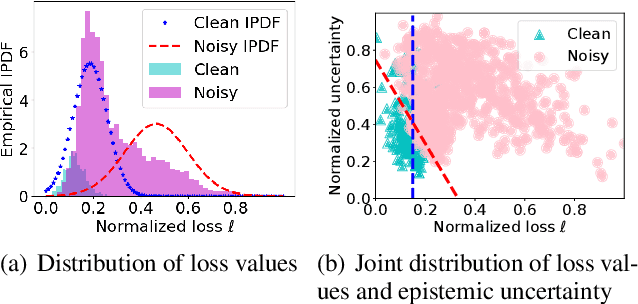
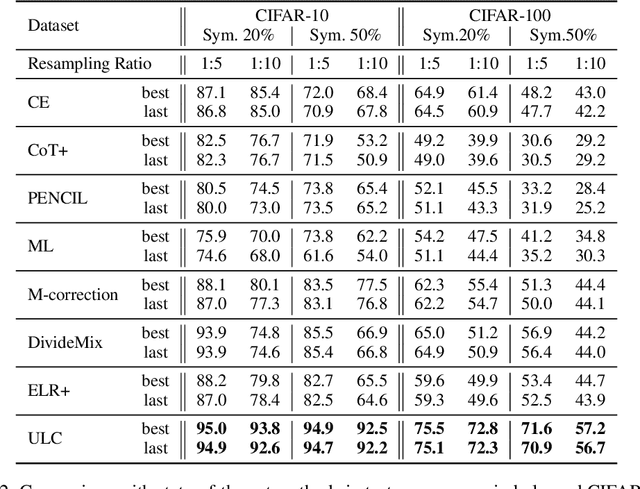
Learning against label noise is a vital topic to guarantee a reliable performance for deep neural networks. Recent research usually refers to dynamic noise modeling with model output probabilities and loss values, and then separates clean and noisy samples. These methods have gained notable success. However, unlike cherry-picked data, existing approaches often cannot perform well when facing imbalanced datasets, a common scenario in the real world. We thoroughly investigate this phenomenon and point out two major issues that hinder the performance, i.e., \emph{inter-class loss distribution discrepancy} and \emph{misleading predictions due to uncertainty}. The first issue is that existing methods often perform class-agnostic noise modeling. However, loss distributions show a significant discrepancy among classes under class imbalance, and class-agnostic noise modeling can easily get confused with noisy samples and samples in minority classes. The second issue refers to that models may output misleading predictions due to epistemic uncertainty and aleatoric uncertainty, thus existing methods that rely solely on the output probabilities may fail to distinguish confident samples. Inspired by our observations, we propose an Uncertainty-aware Label Correction framework~(ULC) to handle label noise on imbalanced datasets. First, we perform epistemic uncertainty-aware class-specific noise modeling to identify trustworthy clean samples and refine/discard highly confident true/corrupted labels. Then, we introduce aleatoric uncertainty in the subsequent learning process to prevent noise accumulation in the label noise modeling process. We conduct experiments on several synthetic and real-world datasets. The results demonstrate the effectiveness of the proposed method, especially on imbalanced datasets.
Contrastive Multi-view Hyperbolic Hierarchical Clustering
May 05, 2022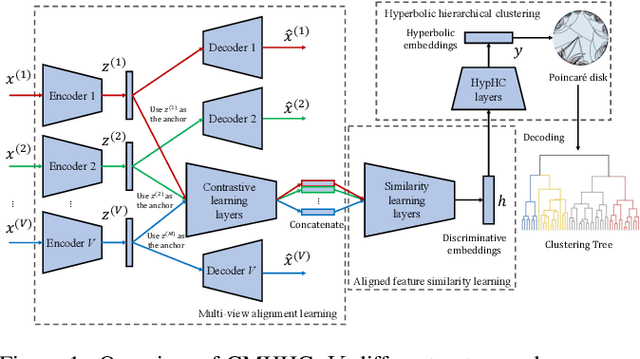
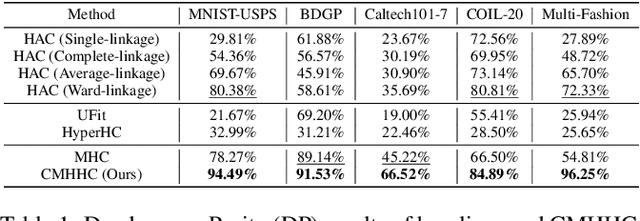
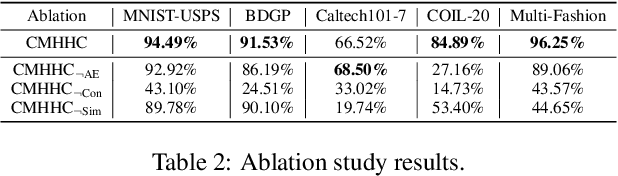
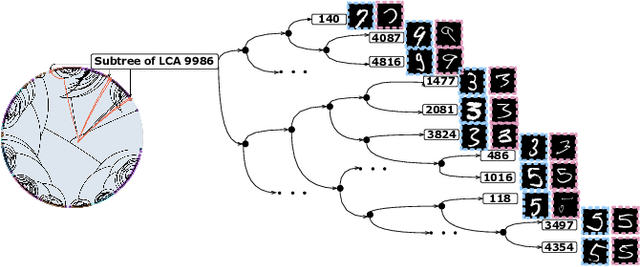
Hierarchical clustering recursively partitions data at an increasingly finer granularity. In real-world applications, multi-view data have become increasingly important. This raises a less investigated problem, i.e., multi-view hierarchical clustering, to better understand the hierarchical structure of multi-view data. To this end, we propose a novel neural network-based model, namely Contrastive Multi-view Hyperbolic Hierarchical Clustering (CMHHC). It consists of three components, i.e., multi-view alignment learning, aligned feature similarity learning, and continuous hyperbolic hierarchical clustering. First, we align sample-level representations across multiple views in a contrastive way to capture the view-invariance information. Next, we utilize both the manifold and Euclidean similarities to improve the metric property. Then, we embed the representations into a hyperbolic space and optimize the hyperbolic embeddings via a continuous relaxation of hierarchical clustering loss. Finally, a binary clustering tree is decoded from optimized hyperbolic embeddings. Experimental results on five real-world datasets demonstrate the effectiveness of the proposed method and its components.
Capture Uncertainties in Deep Neural Networks for Safe Operation of Autonomous Driving Vehicles
Aug 11, 2021Uncertainties in Deep Neural Network (DNN)-based perception and vehicle's motion pose challenges to the development of safe autonomous driving vehicles. In this paper, we propose a safe motion planning framework featuring the quantification and propagation of DNN-based perception uncertainties and motion uncertainties. Contributions of this work are twofold: (1) A Bayesian Deep Neural network model which detects 3D objects and quantitatively captures the associated aleatoric and epistemic uncertainties of DNNs; (2) An uncertainty-aware motion planning algorithm (PU-RRT) that accounts for uncertainties in object detection and ego-vehicle's motion. The proposed approaches are validated via simulated complex scenarios built in CARLA. Experimental results show that the proposed motion planning scheme can cope with uncertainties of DNN-based perception and vehicle motion, and improve the operational safety of autonomous vehicles while still achieving desirable efficiency.
2nd Place Solution for Waymo Open Dataset Challenge -- Real-time 2D Object Detection
Jun 16, 2021
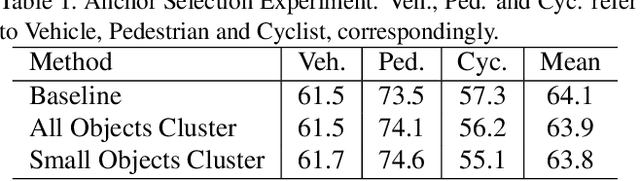
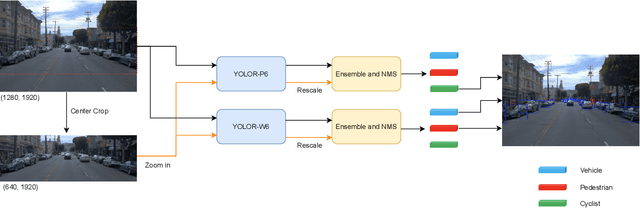
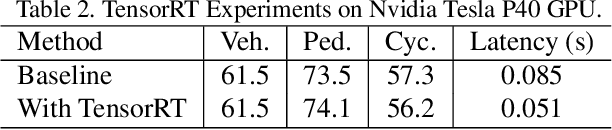
In an autonomous driving system, it is essential to recognize vehicles, pedestrians and cyclists from images. Besides the high accuracy of the prediction, the requirement of real-time running brings new challenges for convolutional network models. In this report, we introduce a real-time method to detect the 2D objects from images. We aggregate several popular one-stage object detectors and train the models of variety input strategies independently, to yield better performance for accurate multi-scale detection of each category, especially for small objects. For model acceleration, we leverage TensorRT to optimize the inference time of our detection pipeline. As shown in the leaderboard, our proposed detection framework ranks the 2nd place with 75.00% L1 mAP and 69.72% L2 mAP in the real-time 2D detection track of the Waymo Open Dataset Challenges, while our framework achieves the latency of 45.8ms/frame on an Nvidia Tesla V100 GPU.