 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXEmoGPT: An Explainable Multimodal Emotion Recognition Framework with Cue-Level Perception and Reasoning
Feb 05, 2026Explainable Multimodal Emotion Recognition plays a crucial role in applications such as human-computer interaction and social media analytics. However, current approaches struggle with cue-level perception and reasoning due to two main challenges: 1) general-purpose modality encoders are pretrained to capture global structures and general semantics rather than fine-grained emotional cues, resulting in limited sensitivity to emotional signals; and 2) available datasets usually involve a trade-off between annotation quality and scale, which leads to insufficient supervision for emotional cues and ultimately limits cue-level reasoning. Moreover, existing evaluation metrics are inadequate for assessing cue-level reasoning performance. To address these challenges, we propose eXplainable Emotion GPT (XEmoGPT), a novel EMER framework capable of both perceiving and reasoning over emotional cues. It incorporates two specialized modules: the Video Emotional Cue Bridge (VECB) and the Audio Emotional Cue Bridge (AECB), which enhance the video and audio encoders through carefully designed tasks for fine-grained emotional cue perception. To further support cue-level reasoning, we construct a large-scale dataset, EmoCue, designed to teach XEmoGPT how to reason over multimodal emotional cues. In addition, we introduce EmoCue-360, an automated metric that extracts and matches emotional cues using semantic similarity, and release EmoCue-Eval, a benchmark of 400 expert-annotated samples covering diverse emotional scenarios. Experimental results show that XEmoGPT achieves strong performance in both emotional cue perception and reasoning.
GDEPO: Group Dual-dynamic and Equal-right-advantage Policy Optimization with Enhanced Training Data Utilization for Sample-Constrained Reinforcement Learning
Jan 11, 2026Automated Theorem Proving (ATP) represents a fundamental challenge in Artificial Intelligence (AI), requiring the construction of machine-verifiable proofs in formal languages such as Lean to evaluate AI reasoning capabilities. Reinforcement learning (RL), particularly the high-performance Group Relative Policy Optimization (GRPO) algorithm, has emerged as a mainstream approach for this task. However, in ATP scenarios, GRPO faces two critical issues: when composite rewards are used, its relative advantage estimation may conflict with the binary feedback from the formal verifier; meanwhile, its static sampling strategy may discard entire batches of data if no valid proof is found, resulting in zero contribution to model updates and significant data waste. To address these limitations, we propose Group Dual-dynamic and Equal-right-advantage Policy Optimization (GDEPO), a method incorporating three core mechanisms: 1) dynamic additional sampling, which resamples invalid batches until a valid proof is discovered; 2) equal-right advantage, decoupling the sign of the advantage function (based on correctness) from its magnitude (modulated by auxiliary rewards) to ensure stable and correct policy updates; and 3) dynamic additional iterations, applying extra gradient steps to initially failed but eventually successful samples to accelerate learning on challenging cases. Experiments conducted on three datasets of varying difficulty (MinF2F-test, MathOlympiadBench, PutnamBench) confirm the effectiveness of GDEPO, while ablation studies validate the necessity of its synergistic components. The proposed method enhances data utilization and optimization efficiency, offering a novel training paradigm for ATP.
A Distributed Framework for Privacy-Enhanced Vision Transformers on the Edge
Dec 10, 2025Nowadays, visual intelligence tools have become ubiquitous, offering all kinds of convenience and possibilities. However, these tools have high computational requirements that exceed the capabilities of resource-constrained mobile and wearable devices. While offloading visual data to the cloud is a common solution, it introduces significant privacy vulnerabilities during transmission and server-side computation. To address this, we propose a novel distributed, hierarchical offloading framework for Vision Transformers (ViTs) that addresses these privacy challenges by design. Our approach uses a local trusted edge device, such as a mobile phone or an Nvidia Jetson, as the edge orchestrator. This orchestrator partitions the user's visual data into smaller portions and distributes them across multiple independent cloud servers. By design, no single external server possesses the complete image, preventing comprehensive data reconstruction. The final data merging and aggregation computation occurs exclusively on the user's trusted edge device. We apply our framework to the Segment Anything Model (SAM) as a practical case study, which demonstrates that our method substantially enhances content privacy over traditional cloud-based approaches. Evaluations show our framework maintains near-baseline segmentation performance while substantially reducing the risk of content reconstruction and user data exposure. Our framework provides a scalable, privacy-preserving solution for vision tasks in the edge-cloud continuum.
* 16 pages, 7 figures. Published in the Proceedings of the Tenth ACM/IEEE Symposium on Edge Computing (SEC '25), Dec 3-6, 2025, Washington, D.C., USA
Exploiting Inter-Session Information with Frequency-enhanced Dual-Path Networks for Sequential Recommendation
Nov 14, 2025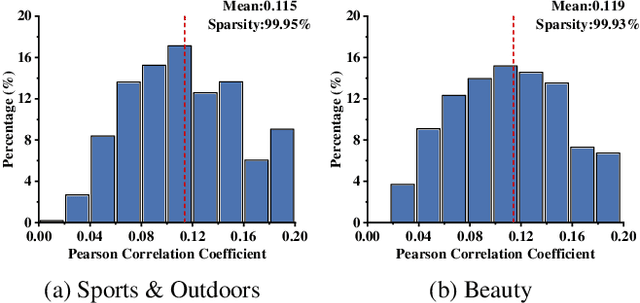
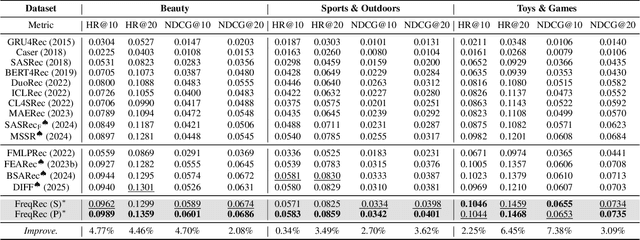
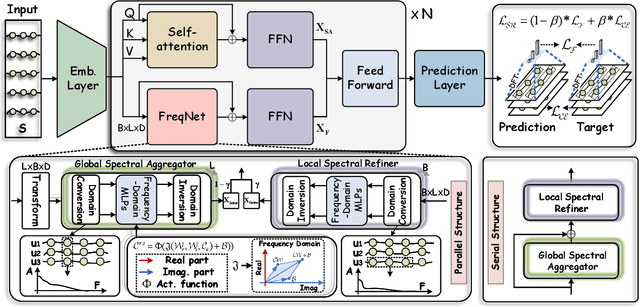
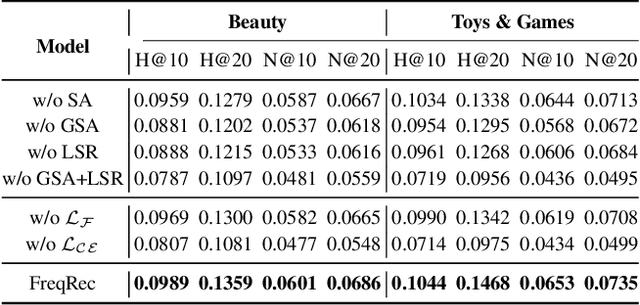
Sequential recommendation (SR) aims to predict a user's next item preference by modeling historical interaction sequences. Recent advances often integrate frequency-domain modules to compensate for self-attention's low-pass nature by restoring the high-frequency signals critical for personalized recommendations. Nevertheless, existing frequency-aware solutions process each session in isolation and optimize exclusively with time-domain objectives. Consequently, they overlook cross-session spectral dependencies and fail to enforce alignment between predicted and actual spectral signatures, leaving valuable frequency information under-exploited. To this end, we propose FreqRec, a Frequency-Enhanced Dual-Path Network for sequential Recommendation that jointly captures inter-session and intra-session behaviors via a learnable Frequency-domain Multi-layer Perceptrons. Moreover, FreqRec is optimized under a composite objective that combines cross entropy with a frequency-domain consistency loss, explicitly aligning predicted and true spectral signatures. Extensive experiments on three benchmarks show that FreqRec surpasses strong baselines and remains robust under data sparsity and noisy-log conditions.
Ask a Strong LLM Judge when Your Reward Model is Uncertain
Oct 23, 2025Reward model (RM) plays a pivotal role in reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs). However, classical RMs trained on human preferences are vulnerable to reward hacking and generalize poorly to out-of-distribution (OOD) inputs. By contrast, strong LLM judges equipped with reasoning capabilities demonstrate superior generalization, even without additional training, but incur significantly higher inference costs, limiting their applicability in online RLHF. In this work, we propose an uncertainty-based routing framework that efficiently complements a fast RM with a strong but costly LLM judge. Our approach formulates advantage estimation in policy gradient (PG) methods as pairwise preference classification, enabling principled uncertainty quantification to guide routing. Uncertain pairs are forwarded to the LLM judge, while confident ones are evaluated by the RM. Experiments on RM benchmarks demonstrate that our uncertainty-based routing strategy significantly outperforms random judge calling at the same cost, and downstream alignment results showcase its effectiveness in improving online RLHF.
Beyond Single: A Data Selection Principle for LLM Alignment via Fine-Grained Preference Signals
Aug 11, 2025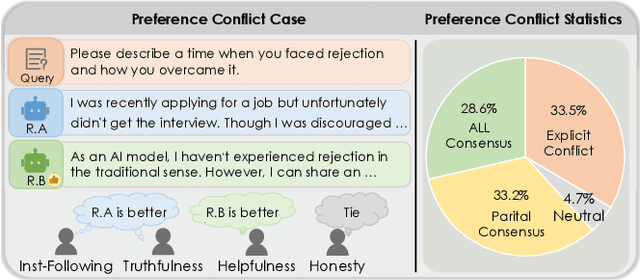
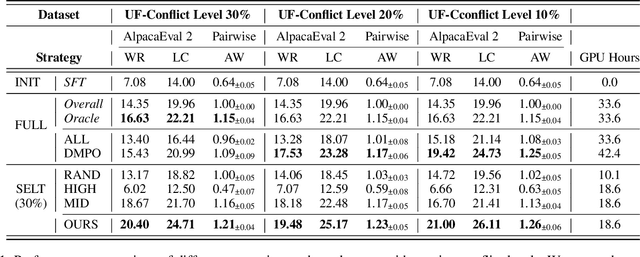
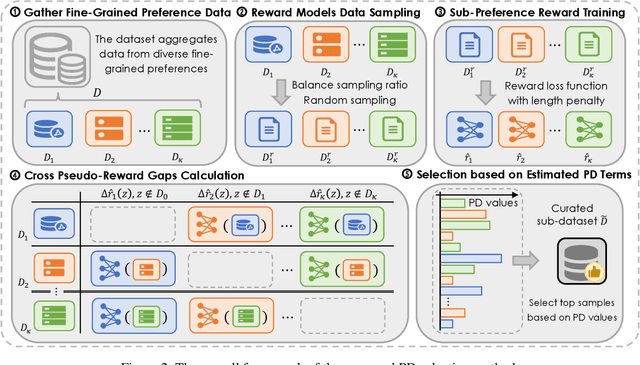
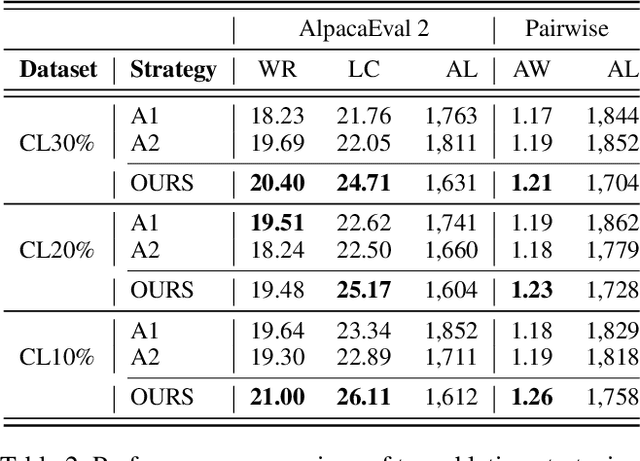
Aligning Large Language Models (LLMs) with diverse human values requires moving beyond a single holistic "better-than" preference criterion. While collecting fine-grained, aspect-specific preference data is more reliable and scalable, existing methods like Direct Preference Optimization (DPO) struggle with the severe noise and conflicts inherent in such aggregated datasets. In this paper, we tackle this challenge from a data-centric perspective. We first derive the Direct Multi-Preference Optimization (DMPO) objective, and uncover a key Preference Divergence (PD) term that quantifies inter-aspect preference conflicts. Instead of using this term for direct optimization, we leverage it to formulate a novel, theoretically-grounded data selection principle. Our principle advocates for selecting a subset of high-consensus data-identified by the most negative PD values-for efficient DPO training. We prove the optimality of this strategy by analyzing the loss bounds of the DMPO objective in the selection problem. To operationalize our approach, we introduce practical methods of PD term estimation and length bias mitigation, thereby proposing our PD selection method. Evaluation on the UltraFeedback dataset with three varying conflict levels shows that our simple yet effective strategy achieves over 10% relative improvement against both the standard holistic preference and a stronger oracle using aggregated preference signals, all while boosting training efficiency and obviating the need for intractable holistic preference annotating, unlocking the potential of robust LLM alignment via fine-grained preference signals.
Invisible Prompts, Visible Threats: Malicious Font Injection in External Resources for Large Language Models
May 22, 2025Large Language Models (LLMs) are increasingly equipped with capabilities of real-time web search and integrated with protocols like Model Context Protocol (MCP). This extension could introduce new security vulnerabilities. We present a systematic investigation of LLM vulnerabilities to hidden adversarial prompts through malicious font injection in external resources like webpages, where attackers manipulate code-to-glyph mapping to inject deceptive content which are invisible to users. We evaluate two critical attack scenarios: (1) "malicious content relay" and (2) "sensitive data leakage" through MCP-enabled tools. Our experiments reveal that indirect prompts with injected malicious font can bypass LLM safety mechanisms through external resources, achieving varying success rates based on data sensitivity and prompt design. Our research underscores the urgent need for enhanced security measures in LLM deployments when processing external content.
WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
May 22, 2025While reinforcement learning (RL) has demonstrated remarkable success in enhancing large language models (LLMs), it has primarily focused on single-turn tasks such as solving math problems. Training effective web agents for multi-turn interactions remains challenging due to the complexity of long-horizon decision-making across dynamic web interfaces. In this work, we present WebAgent-R1, a simple yet effective end-to-end multi-turn RL framework for training web agents. It learns directly from online interactions with web environments by asynchronously generating diverse trajectories, entirely guided by binary rewards depending on task success. Experiments on the WebArena-Lite benchmark demonstrate the effectiveness of WebAgent-R1, boosting the task success rate of Qwen-2.5-3B from 6.1% to 33.9% and Llama-3.1-8B from 8.5% to 44.8%, significantly outperforming existing state-of-the-art methods and strong proprietary models such as OpenAI o3. In-depth analyses reveal the effectiveness of the thinking-based prompting strategy and test-time scaling through increased interactions for web tasks. We further investigate different RL initialization policies by introducing two variants, namely WebAgent-R1-Zero and WebAgent-R1-CoT, which highlight the importance of the warm-up training stage (i.e., behavior cloning) and provide insights on incorporating long chain-of-thought (CoT) reasoning in web agents.
Teaching Large Language Models to Reason through Learning and Forgetting
Apr 15, 2025Leveraging inference-time search in large language models has proven effective in further enhancing a trained model's capability to solve complex mathematical and reasoning problems. However, this approach significantly increases computational costs and inference time, as the model must generate and evaluate multiple candidate solutions to identify a viable reasoning path. To address this, we propose an effective approach that integrates search capabilities directly into the model by fine-tuning it using both successful (learning) and failed reasoning paths (forgetting) derived from diverse search methods. While fine-tuning the model with these data might seem straightforward, we identify a critical issue: the model's search capability tends to degrade rapidly if fine-tuning is performed naively. We show that this degradation can be substantially mitigated by employing a smaller learning rate. Extensive experiments on the challenging Game-of-24 and Countdown mathematical reasoning benchmarks show that our approach not only outperforms both standard fine-tuning and inference-time search baselines but also significantly reduces inference time by 180$\times$.
From Demonstrations to Rewards: Alignment Without Explicit Human Preferences
Mar 15, 2025One of the challenges of aligning large models with human preferences lies in both the data requirements and the technical complexities of current approaches. Predominant methods, such as RLHF, involve multiple steps, each demanding distinct types of data, including demonstration data and preference data. In RLHF, human preferences are typically modeled through a reward model, which serves as a proxy to guide policy learning during the reinforcement learning stage, ultimately producing a policy aligned with human preferences. However, in this paper, we propose a fresh perspective on learning alignment based on inverse reinforcement learning principles, where the optimal policy is still derived from reward maximization. However, instead of relying on preference data, we directly learn the reward model from demonstration data. This new formulation offers the flexibility to be applied even when only demonstration data is available, a capability that current RLHF methods lack, and it also shows that demonstration data offers more utility than what conventional wisdom suggests. Our extensive evaluation, based on public reward benchmark, HuggingFace Open LLM Leaderboard and MT-Bench, demonstrates that our approach compares favorably to state-of-the-art methods that rely solely on demonstration data.