 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment
May 17, 2025



This paper investigates approaches to enhance the reasoning capabilities of Large Language Model (LLM) agents using Reinforcement Learning (RL). Specifically, we focus on multi-turn tool-use scenarios, which can be naturally modeled as Markov Decision Processes (MDPs). While existing approaches often train multi-turn LLM agents with trajectory-level advantage estimation in bandit settings, they struggle with turn-level credit assignment across multiple decision steps, limiting their performance on multi-turn reasoning tasks. To address this, we introduce a fine-grained turn-level advantage estimation strategy to enable more precise credit assignment in multi-turn agent interactions. The strategy is general and can be incorporated into various RL algorithms such as Group Relative Preference Optimization (GRPO). Our experimental evaluation on multi-turn reasoning and search-based tool-use tasks with GRPO implementations highlights the effectiveness of the MDP framework and the turn-level credit assignment in advancing the multi-turn reasoning capabilities of LLM agents in complex decision-making settings. Our method achieves 100% success in tool execution and 50% accuracy in exact answer matching, significantly outperforming baselines, which fail to invoke tools and achieve only 20-30% exact match accuracy.
From Demonstrations to Rewards: Alignment Without Explicit Human Preferences
Mar 15, 2025One of the challenges of aligning large models with human preferences lies in both the data requirements and the technical complexities of current approaches. Predominant methods, such as RLHF, involve multiple steps, each demanding distinct types of data, including demonstration data and preference data. In RLHF, human preferences are typically modeled through a reward model, which serves as a proxy to guide policy learning during the reinforcement learning stage, ultimately producing a policy aligned with human preferences. However, in this paper, we propose a fresh perspective on learning alignment based on inverse reinforcement learning principles, where the optimal policy is still derived from reward maximization. However, instead of relying on preference data, we directly learn the reward model from demonstration data. This new formulation offers the flexibility to be applied even when only demonstration data is available, a capability that current RLHF methods lack, and it also shows that demonstration data offers more utility than what conventional wisdom suggests. Our extensive evaluation, based on public reward benchmark, HuggingFace Open LLM Leaderboard and MT-Bench, demonstrates that our approach compares favorably to state-of-the-art methods that rely solely on demonstration data.
Bridging the Training-Inference Gap in LLMs by Leveraging Self-Generated Tokens
Oct 18, 2024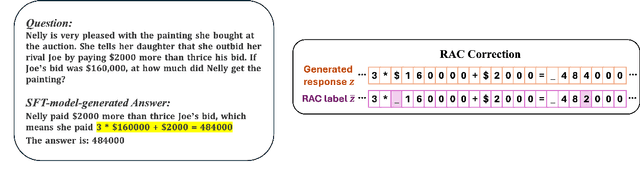
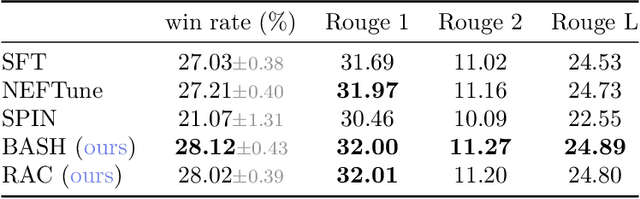
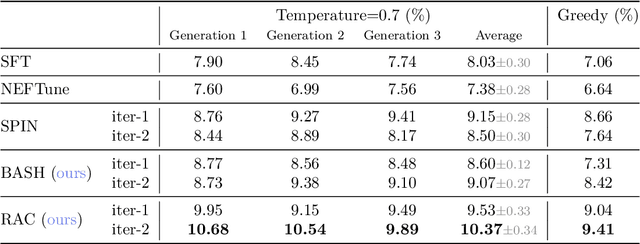
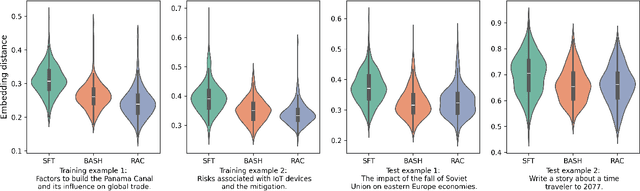
Language models are often trained to maximize the likelihood of the next token given past tokens in the training dataset. However, during inference time, they are utilized differently, generating text sequentially and auto-regressively by using previously generated tokens as input to predict the next one. Marginal differences in predictions at each step can cascade over successive steps, resulting in different distributions from what the models were trained for and potentially leading to unpredictable behavior. This paper proposes two simple approaches based on model own generation to address this discrepancy between the training and inference time. Our first approach is Batch-Scheduled Sampling, where, during training, we stochastically choose between the ground-truth token from the dataset and the model's own generated token as input to predict the next token. This is done in an offline manner, modifying the context window by interleaving ground-truth tokens with those generated by the model. Our second approach is Reference-Answer-based Correction, where we explicitly incorporate a self-correction capability into the model during training. This enables the model to effectively self-correct the gaps between the generated sequences and the ground truth data without relying on an external oracle model. By incorporating our proposed strategies during training, we have observed an overall improvement in performance compared to baseline methods, as demonstrated by our extensive experiments using summarization, general question-answering, and math question-answering tasks.
Joint Demonstration and Preference Learning Improves Policy Alignment with Human Feedback
Jun 11, 2024Aligning human preference and value is an important requirement for building contemporary foundation models and embodied AI. However, popular approaches such as reinforcement learning with human feedback (RLHF) break down the task into successive stages, such as supervised fine-tuning (SFT), reward modeling (RM), and reinforcement learning (RL), each performing one specific learning task. Such a sequential approach results in serious issues such as significant under-utilization of data and distribution mismatch between the learned reward model and generated policy, which eventually lead to poor alignment performance. We develop a single stage approach named Alignment with Integrated Human Feedback (AIHF), capable of integrating both human preference and demonstration to train reward models and the policy. The proposed approach admits a suite of efficient algorithms, which can easily reduce to, and leverage, popular alignment algorithms such as RLHF and Directly Policy Optimization (DPO), and only requires minor changes to the existing alignment pipelines. We demonstrate the efficiency of the proposed solutions with extensive experiments involving alignment problems in LLMs and robotic control problems in MuJoCo. We observe that the proposed solutions outperform the existing alignment algorithms such as RLHF and DPO by large margins, especially when the amount of high-quality preference data is relatively limited.
Getting More Juice Out of the SFT Data: Reward Learning from Human Demonstration Improves SFT for LLM Alignment
May 29, 2024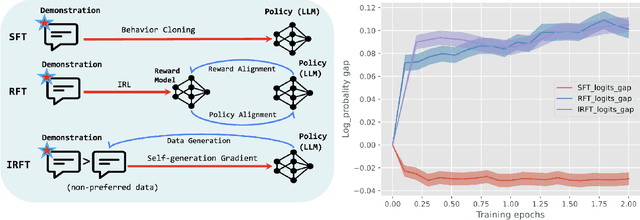

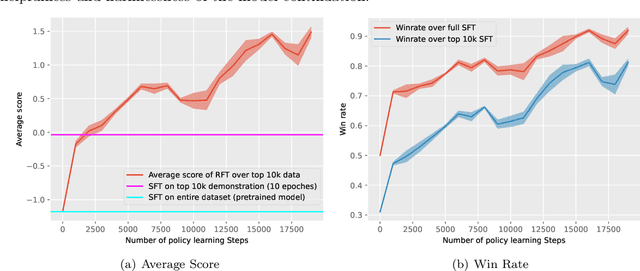
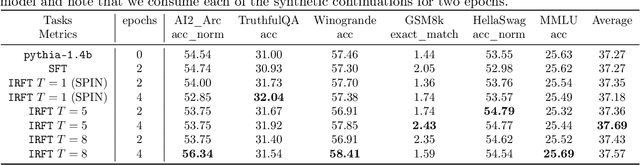
Aligning human preference and value is an important requirement for contemporary foundation models. State-of-the-art techniques such as Reinforcement Learning from Human Feedback (RLHF) often consist of two stages: 1) supervised fine-tuning (SFT), where the model is fine-tuned by learning from human demonstration data; 2) Preference learning, where preference data is used to learn a reward model, which is in turn used by a reinforcement learning (RL) step to fine-tune the model. Such reward model serves as a proxy to human preference, and it is critical to guide the RL step towards improving the model quality. In this work, we argue that the SFT stage significantly benefits from learning a reward model as well. Instead of using the human demonstration data directly via supervised learning, we propose to leverage an Inverse Reinforcement Learning (IRL) technique to (explicitly or implicitly) build an reward model, while learning the policy model. This approach leads to new SFT algorithms that are not only efficient to implement, but also promote the ability to distinguish between the preferred and non-preferred continuations. Moreover, we identify a connection between the proposed IRL based approach, and certain self-play approach proposed recently, and showed that self-play is a special case of modeling a reward-learning agent. Theoretically, we show that the proposed algorithms converge to the stationary solutions of the IRL problem. Empirically, we align 1B and 7B models using proposed methods and evaluate them on a reward benchmark model and the HuggingFace Open LLM Leaderboard. The proposed methods show significant performance improvement over existing SFT approaches. Our results indicate that it is beneficial to explicitly or implicitly leverage reward learning throughout the entire alignment process.
A Bayesian Approach to Robust Inverse Reinforcement Learning
Sep 15, 2023We consider a Bayesian approach to offline model-based inverse reinforcement learning (IRL). The proposed framework differs from existing offline model-based IRL approaches by performing simultaneous estimation of the expert's reward function and subjective model of environment dynamics. We make use of a class of prior distributions which parameterizes how accurate the expert's model of the environment is to develop efficient algorithms to estimate the expert's reward and subjective dynamics in high-dimensional settings. Our analysis reveals a novel insight that the estimated policy exhibits robust performance when the expert is believed (a priori) to have a highly accurate model of the environment. We verify this observation in the MuJoCo environments and show that our algorithms outperform state-of-the-art offline IRL algorithms.
Understanding Expertise through Demonstrations: A Maximum Likelihood Framework for Offline Inverse Reinforcement Learning
Feb 15, 2023



Offline inverse reinforcement learning (Offline IRL) aims to recover the structure of rewards and environment dynamics that underlie observed actions in a fixed, finite set of demonstrations from an expert agent. Accurate models of expertise in executing a task has applications in safety-sensitive applications such as clinical decision making and autonomous driving. However, the structure of an expert's preferences implicit in observed actions is closely linked to the expert's model of the environment dynamics (i.e. the ``world''). Thus, inaccurate models of the world obtained from finite data with limited coverage could compound inaccuracy in estimated rewards. To address this issue, we propose a bi-level optimization formulation of the estimation task wherein the upper level is likelihood maximization based upon a conservative model of the expert's policy (lower level). The policy model is conservative in that it maximizes reward subject to a penalty that is increasing in the uncertainty of the estimated model of the world. We propose a new algorithmic framework to solve the bi-level optimization problem formulation and provide statistical and computational guarantees of performance for the associated reward estimator. Finally, we demonstrate that the proposed algorithm outperforms the state-of-the-art offline IRL and imitation learning benchmarks by a large margin, over the continuous control tasks in MuJoCo and different datasets in the D4RL benchmark.
Structural Estimation of Markov Decision Processes in High-Dimensional State Space with Finite-Time Guarantees
Oct 04, 2022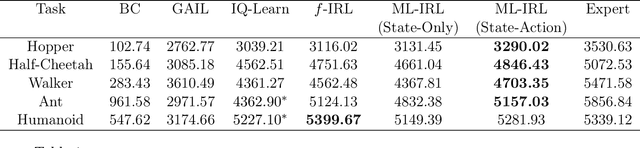
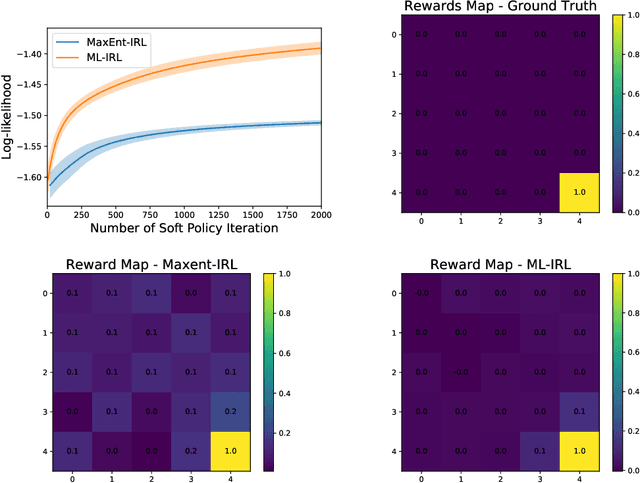

We consider the task of estimating a structural model of dynamic decisions by a human agent based upon the observable history of implemented actions and visited states. This problem has an inherent nested structure: in the inner problem, an optimal policy for a given reward function is identified while in the outer problem, a measure of fit is maximized. Several approaches have been proposed to alleviate the computational burden of this nested-loop structure, but these methods still suffer from high complexity when the state space is either discrete with large cardinality or continuous in high dimensions. Other approaches in the inverse reinforcement learning (IRL) literature emphasize policy estimation at the expense of reduced reward estimation accuracy. In this paper we propose a single-loop estimation algorithm with finite time guarantees that is equipped to deal with high-dimensional state spaces without compromising reward estimation accuracy. In the proposed algorithm, each policy improvement step is followed by a stochastic gradient step for likelihood maximization. We show that the proposed algorithm converges to a stationary solution with a finite-time guarantee. Further, if the reward is parameterized linearly, we show that the algorithm approximates the maximum likelihood estimator sublinearly. Finally, by using robotics control problems in MuJoCo and their transfer settings, we show that the proposed algorithm achieves superior performance compared with other IRL and imitation learning benchmarks.
Maximum-Likelihood Inverse Reinforcement Learning with Finite-Time Guarantees
Oct 04, 2022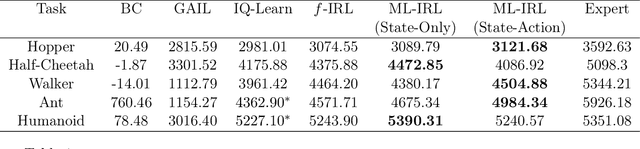

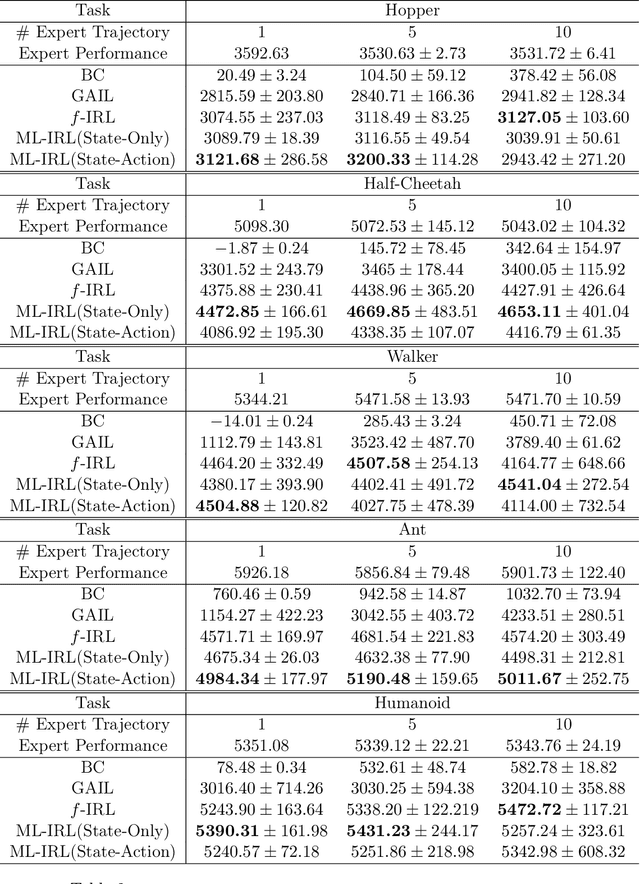
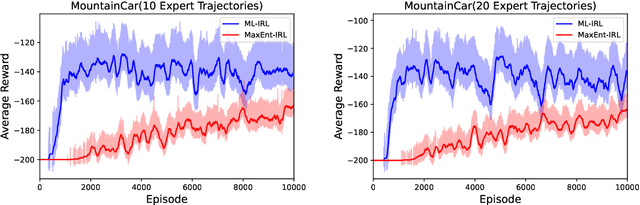
Inverse reinforcement learning (IRL) aims to recover the reward function and the associated optimal policy that best fits observed sequences of states and actions implemented by an expert. Many algorithms for IRL have an inherently nested structure: the inner loop finds the optimal policy given parametrized rewards while the outer loop updates the estimates towards optimizing a measure of fit. For high dimensional environments such nested-loop structure entails a significant computational burden. To reduce the computational burden of a nested loop, novel methods such as SQIL [1] and IQ-Learn [2] emphasize policy estimation at the expense of reward estimation accuracy. However, without accurate estimated rewards, it is not possible to do counterfactual analysis such as predicting the optimal policy under different environment dynamics and/or learning new tasks. In this paper we develop a novel single-loop algorithm for IRL that does not compromise reward estimation accuracy. In the proposed algorithm, each policy improvement step is followed by a stochastic gradient step for likelihood maximization. We show that the proposed algorithm provably converges to a stationary solution with a finite-time guarantee. If the reward is parameterized linearly, we show the identified solution corresponds to the solution of the maximum entropy IRL problem. Finally, by using robotics control problems in MuJoCo and their transfer settings, we show that the proposed algorithm achieves superior performance compared with other IRL and imitation learning benchmarks.
Learning to Coordinate in Multi-Agent Systems: A Coordinated Actor-Critic Algorithm and Finite-Time Guarantees
Oct 11, 2021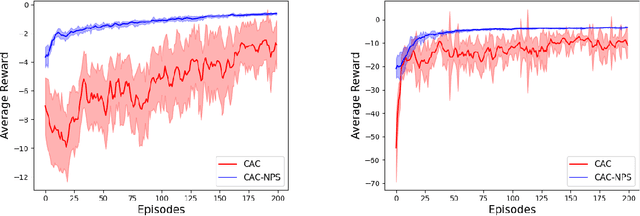
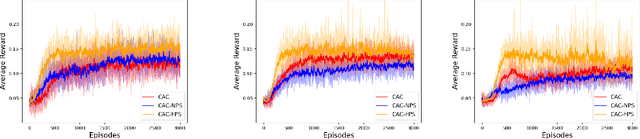
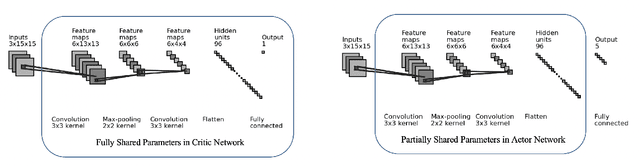
Multi-agent reinforcement learning (MARL) has attracted much research attention recently. However, unlike its single-agent counterpart, many theoretical and algorithmic aspects of MARL have not been well-understood. In this paper, we study the emergence of coordinated behavior by autonomous agents using an actor-critic (AC) algorithm. Specifically, we propose and analyze a class of coordinated actor-critic algorithms (CAC) in which individually parametrized policies have a {\it shared} part (which is jointly optimized among all agents) and a {\it personalized} part (which is only locally optimized). Such kind of {\it partially personalized} policy allows agents to learn to coordinate by leveraging peers' past experience and adapt to individual tasks. The flexibility in our design allows the proposed MARL-CAC algorithm to be used in a {\it fully decentralized} setting, where the agents can only communicate with their neighbors, as well as a {\it federated} setting, where the agents occasionally communicate with a server while optimizing their (partially personalized) local models. Theoretically, we show that under some standard regularity assumptions, the proposed MARL-CAC algorithm requires $\mathcal{O}(\epsilon^{-\frac{5}{2}})$ samples to achieve an $\epsilon$-stationary solution (defined as the solution whose squared norm of the gradient of the objective function is less than $\epsilon$). To the best of our knowledge, this work provides the first finite-sample guarantee for decentralized AC algorithm with partially personalized policies.