 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Stress Monitoring, Detection, and Management in College Students: A Wearable Technology and Machine-Learning Approach
May 21, 2025



College students are increasingly affected by stress, anxiety, and depression, yet face barriers to traditional mental health care. This study evaluated the efficacy of a mobile health (mHealth) intervention, Mental Health Evaluation and Lookout Program (mHELP), which integrates a smartwatch sensor and machine learning (ML) algorithms for real-time stress detection and self-management. In a 12-week randomized controlled trial (n = 117), participants were assigned to a treatment group using mHELP's full suite of interventions or a control group using the app solely for real-time stress logging and weekly psychological assessments. The primary outcome, "Moments of Stress" (MS), was assessed via physiological and self-reported indicators and analyzed using Generalized Linear Mixed Models (GLMM) approaches. Similarly, secondary outcomes of psychological assessments, including the Generalized Anxiety Disorder-7 (GAD-7) for anxiety, the Patient Health Questionnaire (PHQ-8) for depression, and the Perceived Stress Scale (PSS), were also analyzed via GLMM. The finding of the objective measure, MS, indicates a substantial decrease in MS among the treatment group compared to the control group, while no notable between-group differences were observed in subjective scores of anxiety (GAD-7), depression (PHQ-8), or stress (PSS). However, the treatment group exhibited a clinically meaningful decline in GAD-7 and PSS scores. These findings underscore the potential of wearable-enabled mHealth tools to reduce acute stress in college populations and highlight the need for extended interventions and tailored features to address chronic symptoms like depression.
Resolving uncertainty on the fly: Modeling adaptive driving behavior as active inference
Nov 10, 2023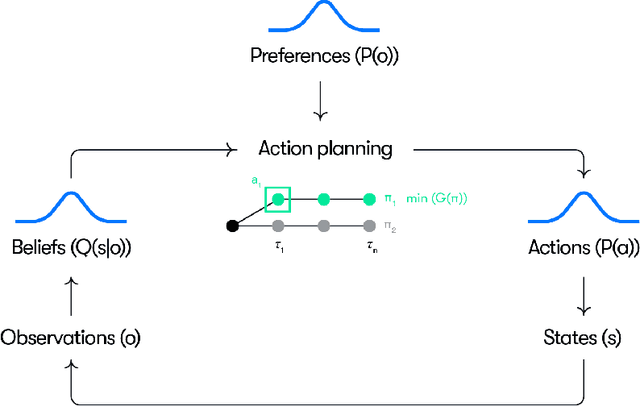
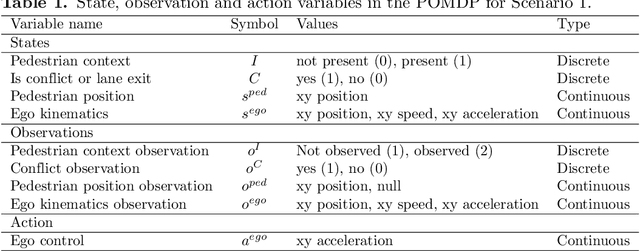
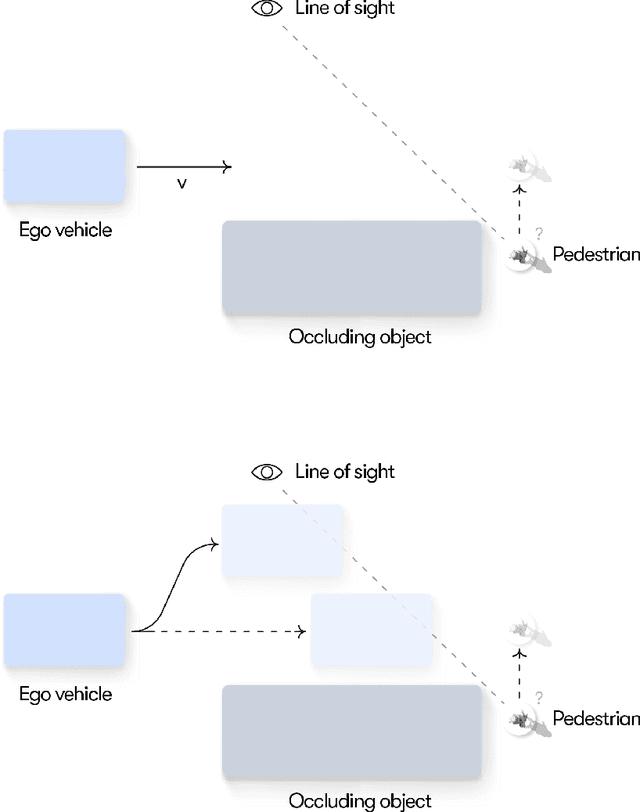

Understanding adaptive human driving behavior, in particular how drivers manage uncertainty, is of key importance for developing simulated human driver models that can be used in the evaluation and development of autonomous vehicles. However, existing traffic psychology models of adaptive driving behavior either lack computational rigor or only address specific scenarios and/or behavioral phenomena. While models developed in the fields of machine learning and robotics can effectively learn adaptive driving behavior from data, due to their black box nature, they offer little or no explanation of the mechanisms underlying the adaptive behavior. Thus, a generalizable, interpretable, computational model of adaptive human driving behavior is still lacking. This paper proposes such a model based on active inference, a behavioral modeling framework originating in computational neuroscience. The model offers a principled solution to how humans trade progress against caution through policy selection based on the single mandate to minimize expected free energy. This casts goal-seeking and information-seeking (uncertainty-resolving) behavior under a single objective function, allowing the model to seamlessly resolve uncertainty as a means to obtain its goals. We apply the model in two apparently disparate driving scenarios that require managing uncertainty, (1) driving past an occluding object and (2) visual time sharing between driving and a secondary task, and show how human-like adaptive driving behavior emerges from the single principle of expected free energy minimization.
A Unified View on Solving Objective Mismatch in Model-Based Reinforcement Learning
Oct 10, 2023Model-based Reinforcement Learning (MBRL) aims to make agents more sample-efficient, adaptive, and explainable by learning an explicit model of the environment. While the capabilities of MBRL agents have significantly improved in recent years, how to best learn the model is still an unresolved question. The majority of MBRL algorithms aim at training the model to make accurate predictions about the environment and subsequently using the model to determine the most rewarding actions. However, recent research has shown that model predictive accuracy is often not correlated with action quality, tracing the root cause to the \emph{objective mismatch} between accurate dynamics model learning and policy optimization of rewards. A number of interrelated solution categories to the objective mismatch problem have emerged as MBRL continues to mature as a research area. In this work, we provide an in-depth survey of these solution categories and propose a taxonomy to foster future research.
Evaluating Mental Stress Among College Students Using Heart Rate and Hand Acceleration Data Collected from Wearable Sensors
Sep 20, 2023



Stress is various mental health disorders including depression and anxiety among college students. Early stress diagnosis and intervention may lower the risk of developing mental illnesses. We examined a machine learning-based method for identification of stress using data collected in a naturalistic study utilizing self-reported stress as ground truth as well as physiological data such as heart rate and hand acceleration. The study involved 54 college students from a large campus who used wearable wrist-worn sensors and a mobile health (mHealth) application continuously for 40 days. The app gathered physiological data including heart rate and hand acceleration at one hertz frequency. The application also enabled users to self-report stress by tapping on the watch face, resulting in a time-stamped record of the self-reported stress. We created, evaluated, and analyzed machine learning algorithms for identifying stress episodes among college students using heart rate and accelerometer data. The XGBoost method was the most reliable model with an AUC of 0.64 and an accuracy of 84.5%. The standard deviation of hand acceleration, standard deviation of heart rate, and the minimum heart rate were the most important features for stress detection. This evidence may support the efficacy of identifying patterns in physiological reaction to stress using smartwatch sensors and may inform the design of future tools for real-time detection of stress.
A Bayesian Approach to Robust Inverse Reinforcement Learning
Sep 15, 2023We consider a Bayesian approach to offline model-based inverse reinforcement learning (IRL). The proposed framework differs from existing offline model-based IRL approaches by performing simultaneous estimation of the expert's reward function and subjective model of environment dynamics. We make use of a class of prior distributions which parameterizes how accurate the expert's model of the environment is to develop efficient algorithms to estimate the expert's reward and subjective dynamics in high-dimensional settings. Our analysis reveals a novel insight that the estimated policy exhibits robust performance when the expert is believed (a priori) to have a highly accurate model of the environment. We verify this observation in the MuJoCo environments and show that our algorithms outperform state-of-the-art offline IRL algorithms.