 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving uncertainty on the fly: Modeling adaptive driving behavior as active inference
Nov 10, 2023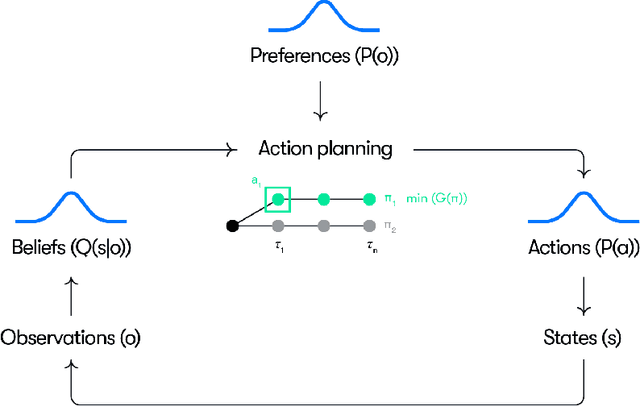
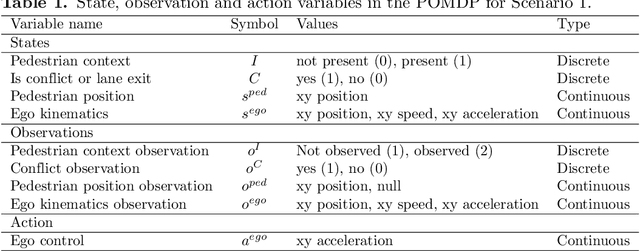
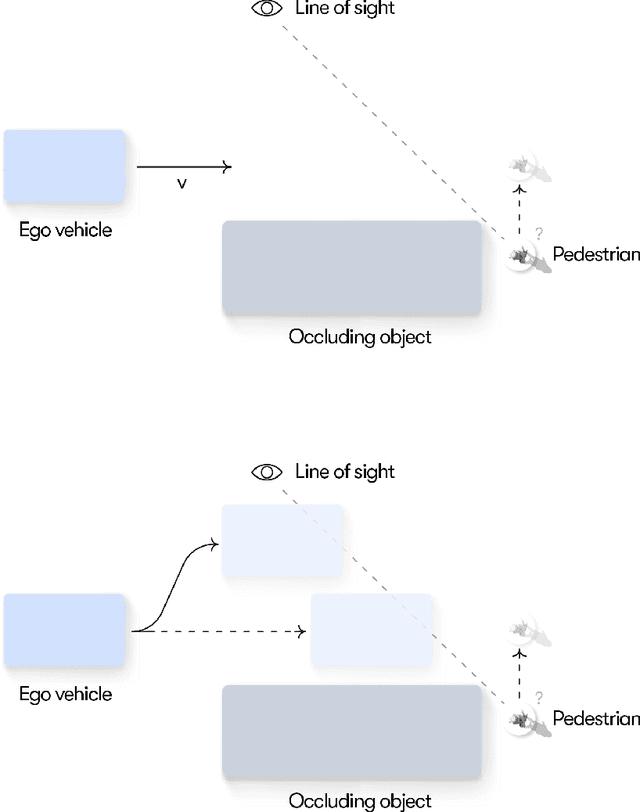

Understanding adaptive human driving behavior, in particular how drivers manage uncertainty, is of key importance for developing simulated human driver models that can be used in the evaluation and development of autonomous vehicles. However, existing traffic psychology models of adaptive driving behavior either lack computational rigor or only address specific scenarios and/or behavioral phenomena. While models developed in the fields of machine learning and robotics can effectively learn adaptive driving behavior from data, due to their black box nature, they offer little or no explanation of the mechanisms underlying the adaptive behavior. Thus, a generalizable, interpretable, computational model of adaptive human driving behavior is still lacking. This paper proposes such a model based on active inference, a behavioral modeling framework originating in computational neuroscience. The model offers a principled solution to how humans trade progress against caution through policy selection based on the single mandate to minimize expected free energy. This casts goal-seeking and information-seeking (uncertainty-resolving) behavior under a single objective function, allowing the model to seamlessly resolve uncertainty as a means to obtain its goals. We apply the model in two apparently disparate driving scenarios that require managing uncertainty, (1) driving past an occluding object and (2) visual time sharing between driving and a secondary task, and show how human-like adaptive driving behavior emerges from the single principle of expected free energy minimization.
Personalization of End-to-end Speech Recognition On Mobile Devices For Named Entities
Dec 14, 2019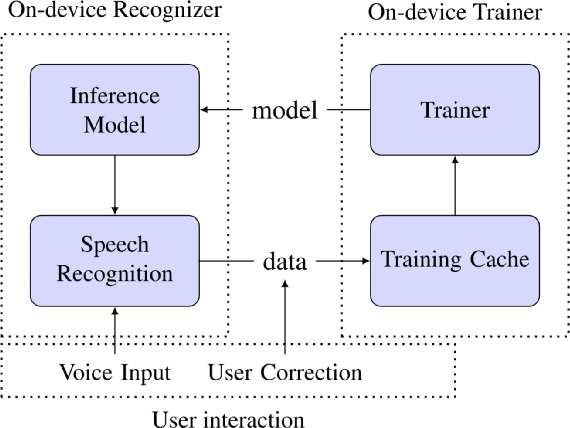
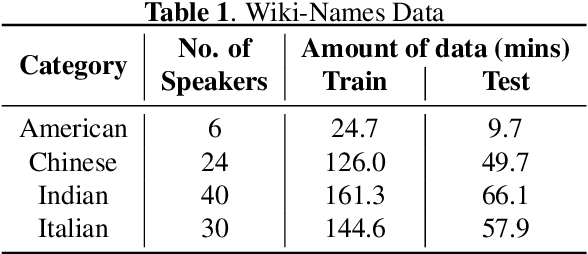
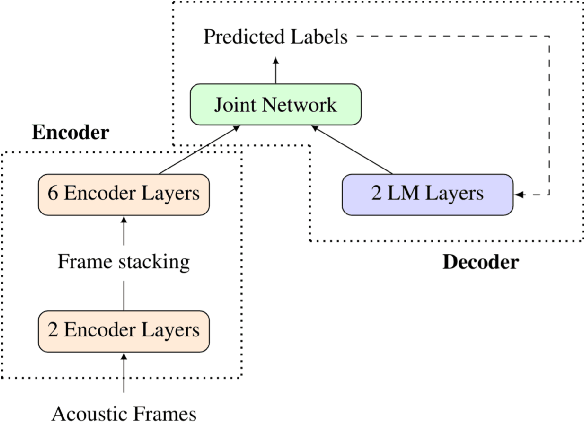
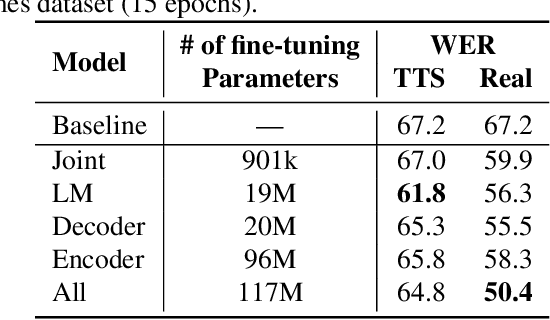
We study the effectiveness of several techniques to personalize end-to-end speech models and improve the recognition of proper names relevant to the user. These techniques differ in the amounts of user effort required to provide supervision, and are evaluated on how they impact speech recognition performance. We propose using keyword-dependent precision and recall metrics to measure vocabulary acquisition performance. We evaluate the algorithms on a dataset that we designed to contain names of persons that are difficult to recognize. Therefore, the baseline recall rate for proper names in this dataset is very low: 2.4%. A data synthesis approach we developed brings it to 48.6%, with no need for speech input from the user. With speech input, if the user corrects only the names, the name recall rate improves to 64.4%. If the user corrects all the recognition errors, we achieve the best recall of 73.5%. To eliminate the need to upload user data and store personalized models on a server, we focus on performing the entire personalization workflow on a mobile device.
Switched linear encoding with rectified linear autoencoders
Jan 19, 2013

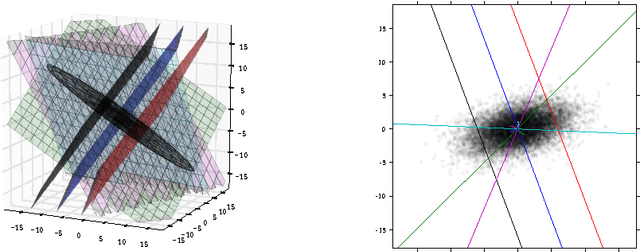
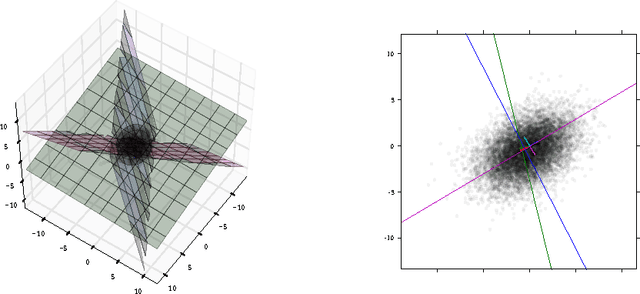
Several recent results in machine learning have established formal connections between autoencoders---artificial neural network models that attempt to reproduce their inputs---and other coding models like sparse coding and K-means. This paper explores in depth an autoencoder model that is constructed using rectified linear activations on its hidden units. Our analysis builds on recent results to further unify the world of sparse linear coding models. We provide an intuitive interpretation of the behavior of these coding models and demonstrate this intuition using small, artificial datasets with known distributions.