 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Compounding in Mobile Keyboard Input
Jan 17, 2022This paper proposes a framework to improve the typing experience of mobile users in morphologically rich languages. Smartphone keyboards typically support features such as input decoding, corrections and predictions that all rely on language models. For latency reasons, these operations happen on device, so the models are of limited size and cannot easily cover all the words needed by users for their daily tasks, especially in morphologically rich languages. In particular, the compounding nature of Germanic languages makes their vocabulary virtually infinite. Similarly, heavily inflecting and agglutinative languages (e.g. Slavic, Turkic or Finno-Ugric languages) tend to have much larger vocabularies than morphologically simpler languages, such as English or Mandarin. We propose to model such languages with automatically selected subword units annotated with what we call binding types, allowing the decoder to know when to bind subword units into words. We show that this method brings around 20% word error rate reduction in a variety of compounding languages. This is more than twice the improvement we previously obtained with a more basic approach, also described in the paper.
Exploring Heterogeneous Characteristics of Layers in ASR Models for More Efficient Training
Oct 08, 2021

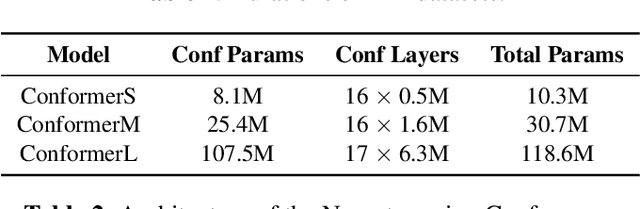
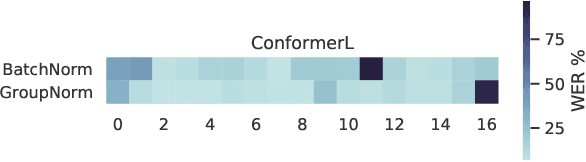
Transformer-based architectures have been the subject of research aimed at understanding their overparameterization and the non-uniform importance of their layers. Applying these approaches to Automatic Speech Recognition, we demonstrate that the state-of-the-art Conformer models generally have multiple ambient layers. We study the stability of these layers across runs and model sizes, propose that group normalization may be used without disrupting their formation, and examine their correlation with model weight updates in each layer. Finally, we apply these findings to Federated Learning in order to improve the training procedure, by targeting Federated Dropout to layers by importance. This allows us to reduce the model size optimized by clients without quality degradation, and shows potential for future exploration.
Low-rank Gradient Approximation For Memory-Efficient On-device Training of Deep Neural Network
Jan 24, 2020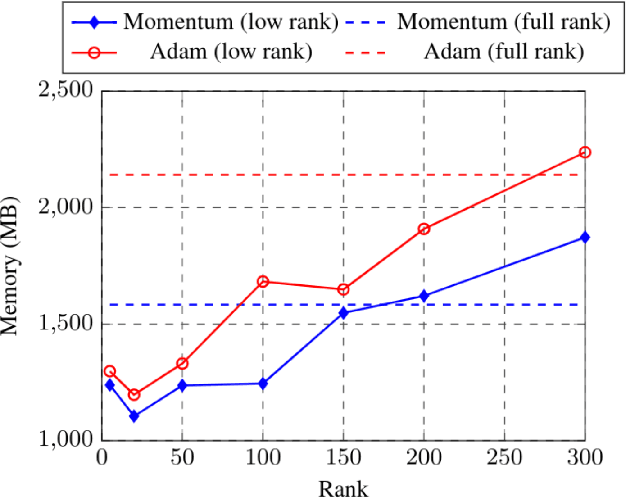
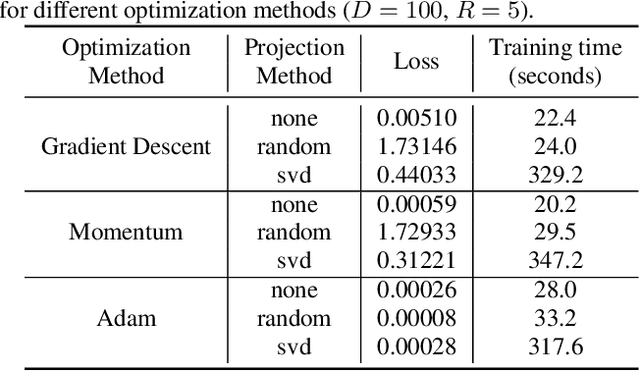
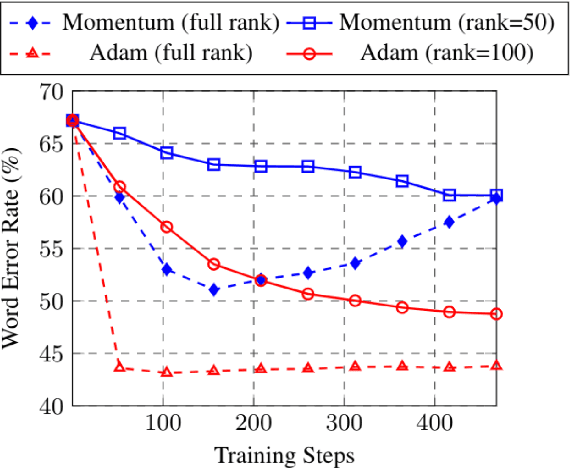
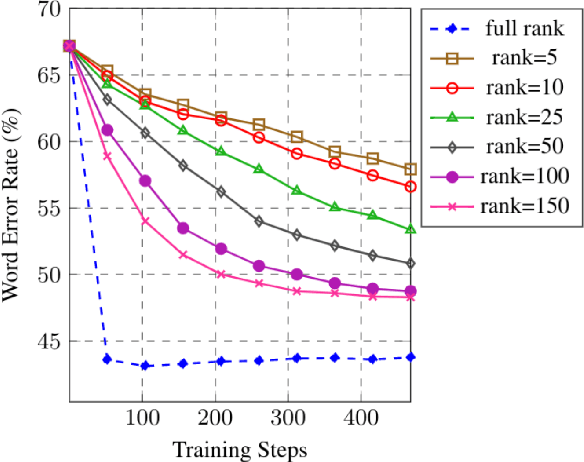
Training machine learning models on mobile devices has the potential of improving both privacy and accuracy of the models. However, one of the major obstacles to achieving this goal is the memory limitation of mobile devices. Reducing training memory enables models with high-dimensional weight matrices, like automatic speech recognition (ASR) models, to be trained on-device. In this paper, we propose approximating the gradient matrices of deep neural networks using a low-rank parameterization as an avenue to save training memory. The low-rank gradient approximation enables more advanced, memory-intensive optimization techniques to be run on device. Our experimental results show that we can reduce the training memory by about 33.0% for Adam optimization. It uses comparable memory to momentum optimization and achieves a 4.5% relative lower word error rate on an ASR personalization task.
Personalization of End-to-end Speech Recognition On Mobile Devices For Named Entities
Dec 14, 2019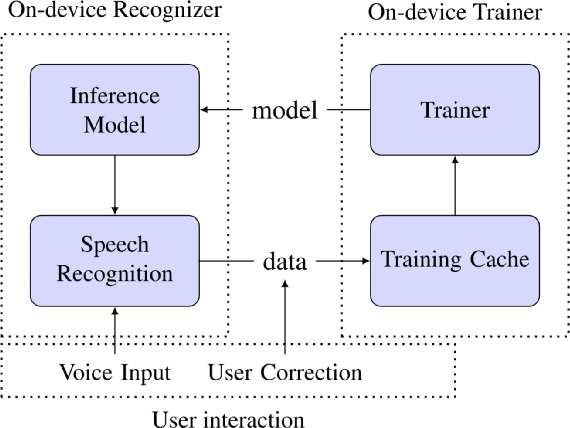
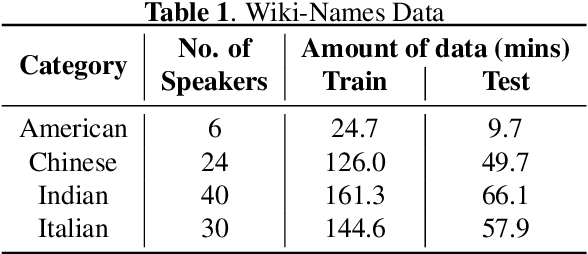
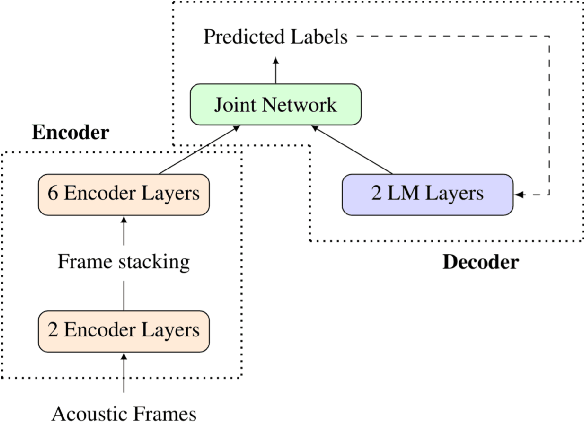
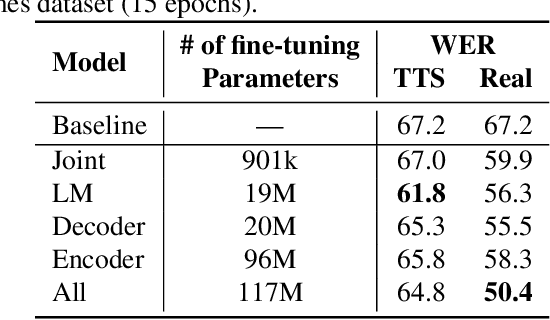
We study the effectiveness of several techniques to personalize end-to-end speech models and improve the recognition of proper names relevant to the user. These techniques differ in the amounts of user effort required to provide supervision, and are evaluated on how they impact speech recognition performance. We propose using keyword-dependent precision and recall metrics to measure vocabulary acquisition performance. We evaluate the algorithms on a dataset that we designed to contain names of persons that are difficult to recognize. Therefore, the baseline recall rate for proper names in this dataset is very low: 2.4%. A data synthesis approach we developed brings it to 48.6%, with no need for speech input from the user. With speech input, if the user corrects only the names, the name recall rate improves to 64.4%. If the user corrects all the recognition errors, we achieve the best recall of 73.5%. To eliminate the need to upload user data and store personalized models on a server, we focus on performing the entire personalization workflow on a mobile device.