 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Modeling For Spoken Language Identification
Sep 19, 2023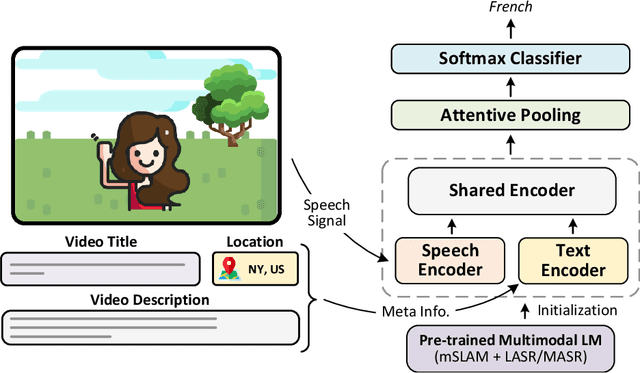
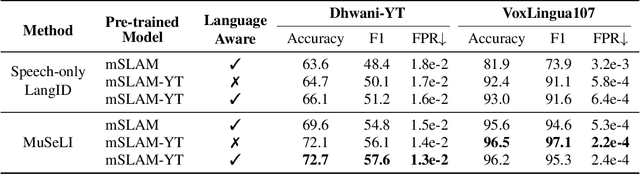
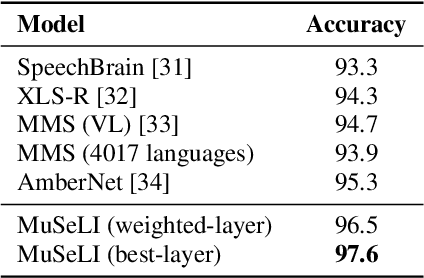
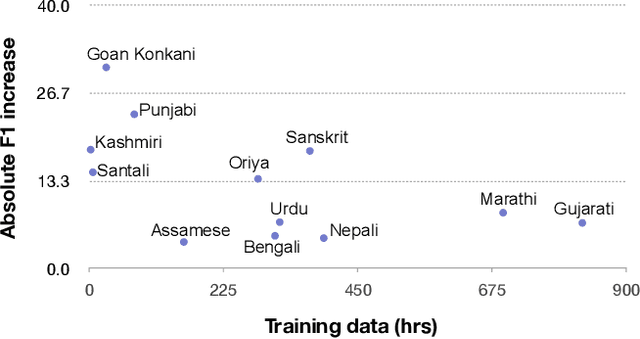
Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.
Large vocabulary speech recognition for languages of Africa: multilingual modeling and self-supervised learning
Aug 05, 2022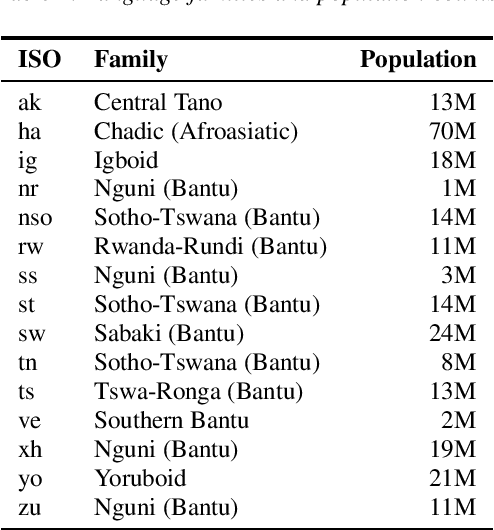
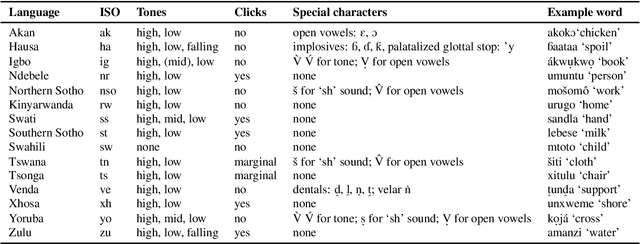
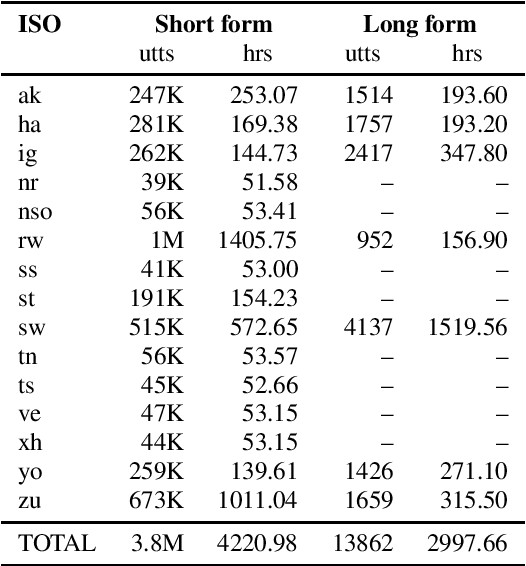
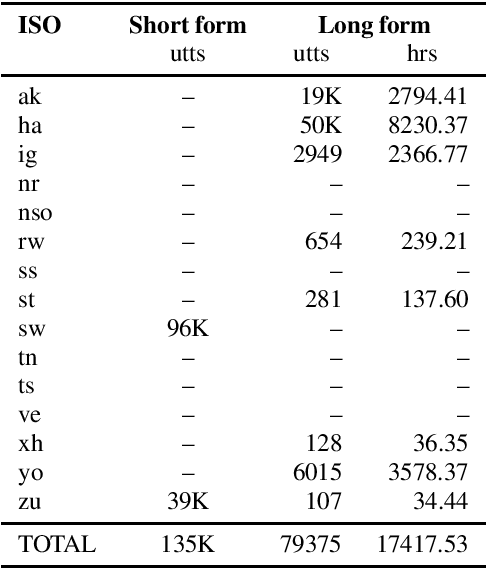
Almost none of the 2,000+ languages spoken in Africa have widely available automatic speech recognition systems, and the required data is also only available for a few languages. We have experimented with two techniques which may provide pathways to large vocabulary speech recognition for African languages: multilingual modeling and self-supervised learning. We gathered available open source data and collected data for 15 languages, and trained experimental models using these techniques. Our results show that pooling the small amounts of data available in multilingual end-to-end models, and pre-training on unsupervised data can help improve speech recognition quality for many African languages.
Accented Speech Recognition: Benchmarking, Pre-training, and Diverse Data
May 16, 2022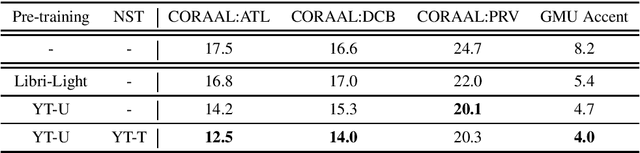

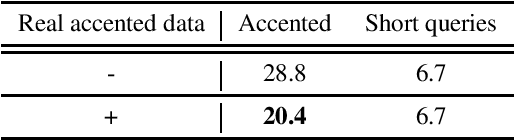
Building inclusive speech recognition systems is a crucial step towards developing technologies that speakers of all language varieties can use. Therefore, ASR systems must work for everybody independently of the way they speak. To accomplish this goal, there should be available data sets representing language varieties, and also an understanding of model configuration that is the most helpful in achieving robust understanding of all types of speech. However, there are not enough data sets for accented speech, and for the ones that are already available, more training approaches need to be explored to improve the quality of accented speech recognition. In this paper, we discuss recent progress towards developing more inclusive ASR systems, namely, the importance of building new data sets representing linguistic diversity, and exploring novel training approaches to improve performance for all users. We address recent directions within benchmarking ASR systems for accented speech, measure the effects of wav2vec 2.0 pre-training on accented speech recognition, and highlight corpora relevant for diverse ASR evaluations.
Building Machine Translation Systems for the Next Thousand Languages
May 16, 2022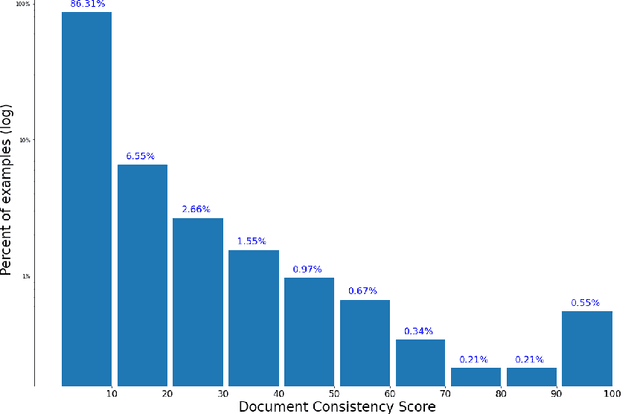
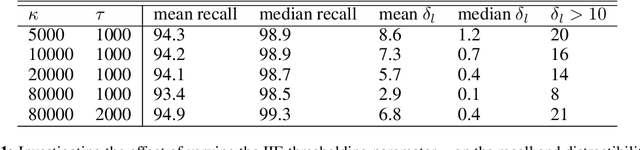

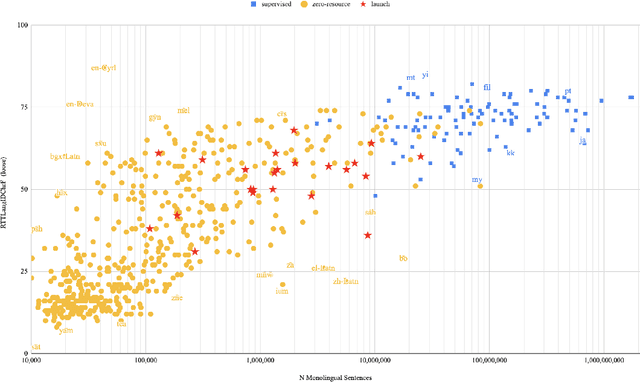
In this paper we share findings from our effort to build practical machine translation (MT) systems capable of translating across over one thousand languages. We describe results in three research domains: (i) Building clean, web-mined datasets for 1500+ languages by leveraging semi-supervised pre-training for language identification and developing data-driven filtering techniques; (ii) Developing practical MT models for under-served languages by leveraging massively multilingual models trained with supervised parallel data for over 100 high-resource languages and monolingual datasets for an additional 1000+ languages; and (iii) Studying the limitations of evaluation metrics for these languages and conducting qualitative analysis of the outputs from our MT models, highlighting several frequent error modes of these types of models. We hope that our work provides useful insights to practitioners working towards building MT systems for currently understudied languages, and highlights research directions that can complement the weaknesses of massively multilingual models in data-sparse settings.
Handling Compounding in Mobile Keyboard Input
Jan 17, 2022This paper proposes a framework to improve the typing experience of mobile users in morphologically rich languages. Smartphone keyboards typically support features such as input decoding, corrections and predictions that all rely on language models. For latency reasons, these operations happen on device, so the models are of limited size and cannot easily cover all the words needed by users for their daily tasks, especially in morphologically rich languages. In particular, the compounding nature of Germanic languages makes their vocabulary virtually infinite. Similarly, heavily inflecting and agglutinative languages (e.g. Slavic, Turkic or Finno-Ugric languages) tend to have much larger vocabularies than morphologically simpler languages, such as English or Mandarin. We propose to model such languages with automatically selected subword units annotated with what we call binding types, allowing the decoder to know when to bind subword units into words. We show that this method brings around 20% word error rate reduction in a variety of compounding languages. This is more than twice the improvement we previously obtained with a more basic approach, also described in the paper.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
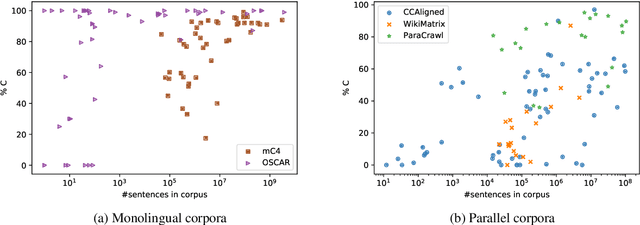

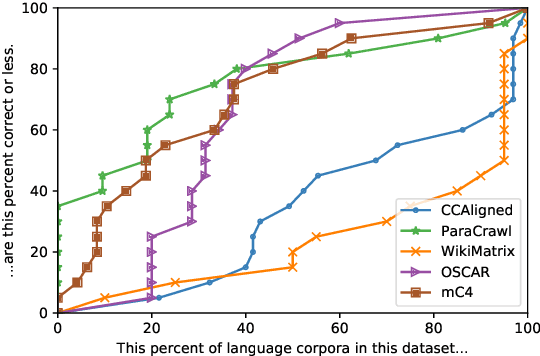
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
Mining Large-Scale Low-Resource Pronunciation Data From Wikipedia
Jan 27, 2021



Pronunciation modeling is a key task for building speech technology in new languages, and while solid grapheme-to-phoneme (G2P) mapping systems exist, language coverage can stand to be improved. The information needed to build G2P models for many more languages can easily be found on Wikipedia, but unfortunately, it is stored in disparate formats. We report on a system we built to mine a pronunciation data set in 819 languages from loosely structured tables within Wikipedia. The data includes phoneme inventories, and for 63 low-resource languages, also includes the grapheme-to-phoneme (G2P) mapping. 54 of these languages do not have easily findable G2P mappings online otherwise. We turned the information from Wikipedia into a structured, machine-readable TSV format, and make the resulting data set publicly available so it can be improved further and used in a variety of applications involving low-resource languages.
Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus
Oct 29, 2020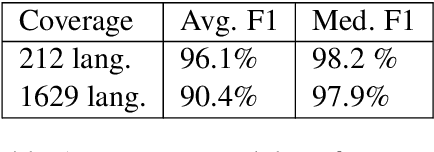


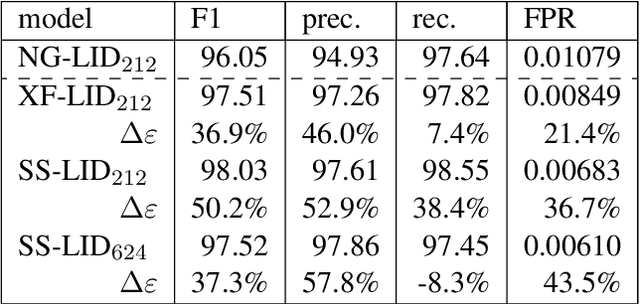
Large text corpora are increasingly important for a wide variety of Natural Language Processing (NLP) tasks, and automatic language identification (LangID) is a core technology needed to collect such datasets in a multilingual context. LangID is largely treated as solved in the literature, with models reported that achieve over 90% average F1 on as many as 1,366 languages. We train LangID models on up to 1,629 languages with comparable quality on held-out test sets, but find that human-judged LangID accuracy for web-crawl text corpora created using these models is only around 5% for many lower-resource languages, suggesting a need for more robust evaluation. Further analysis revealed a variety of error modes, arising from domain mismatch, class imbalance, language similarity, and insufficiently expressive models. We propose two classes of techniques to mitigate these errors: wordlist-based tunable-precision filters (for which we release curated lists in about 500 languages) and transformer-based semi-supervised LangID models, which increase median dataset precision from 5.5% to 71.2%. These techniques enable us to create an initial data set covering 100K or more relatively clean sentences in each of 500+ languages, paving the way towards a 1,000-language web text corpus.
Writing Across the World's Languages: Deep Internationalization for Gboard, the Google Keyboard
Dec 03, 2019This technical report describes our deep internationalization program for Gboard, the Google Keyboard. Today, Gboard supports 900+ language varieties across 70+ writing systems, and this report describes how and why we have been adding support for hundreds of language varieties from around the globe. Many languages of the world are increasingly used in writing on an everyday basis, and we describe the trends we see. We cover technological and logistical challenges in scaling up a language technology product like Gboard to hundreds of language varieties, and describe how we built systems and processes to operate at scale. Finally, we summarize the key take-aways from user studies we ran with speakers of hundreds of languages from around the world.
Automatic Keyboard Layout Design for Low-Resource Latin-Script Languages
Jan 18, 2019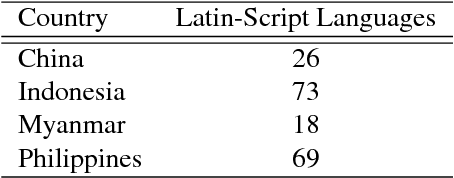


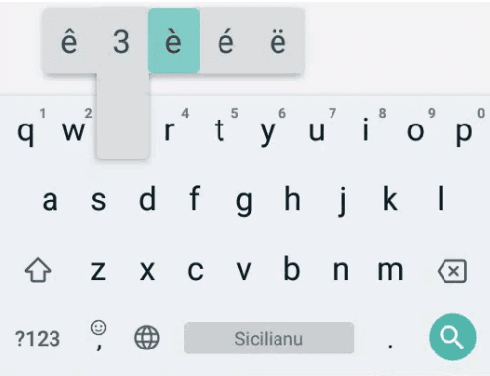
We present our approach to automatically designing and implementing keyboard layouts on mobile devices for typing low-resource languages written in the Latin script. For many speakers, one of the barriers in accessing and creating text content on the web is the absence of input tools for their language. Ease in typing in these languages would lower technological barriers to online communication and collaboration, likely leading to the creation of more web content. Unfortunately, it can be time-consuming to develop layouts manually even for language communities that use a keyboard layout very similar to English; starting from scratch requires many configuration files to describe multiple possible behaviors for each key. With our approach, we only need a small amount of data in each language to generate keyboard layouts with very little human effort. This process can help serve speakers of low-resource languages in a scalable way, allowing us to develop input tools for more languages. Having input tools that reflect the linguistic diversity of the world will let as many people as possible use technology to learn, communicate, and express themselves in their own native languages.