 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccented Speech Recognition: Benchmarking, Pre-training, and Diverse Data
May 16, 2022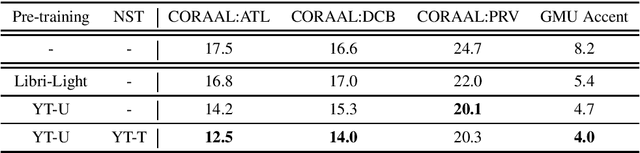

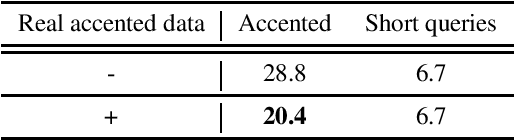
Building inclusive speech recognition systems is a crucial step towards developing technologies that speakers of all language varieties can use. Therefore, ASR systems must work for everybody independently of the way they speak. To accomplish this goal, there should be available data sets representing language varieties, and also an understanding of model configuration that is the most helpful in achieving robust understanding of all types of speech. However, there are not enough data sets for accented speech, and for the ones that are already available, more training approaches need to be explored to improve the quality of accented speech recognition. In this paper, we discuss recent progress towards developing more inclusive ASR systems, namely, the importance of building new data sets representing linguistic diversity, and exploring novel training approaches to improve performance for all users. We address recent directions within benchmarking ASR systems for accented speech, measure the effects of wav2vec 2.0 pre-training on accented speech recognition, and highlight corpora relevant for diverse ASR evaluations.
Neural Simultaneous Speech Translation Using Alignment-Based Chunking
May 29, 2020
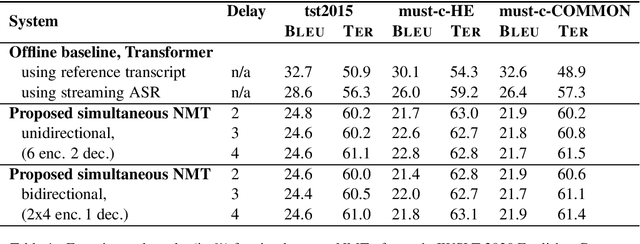
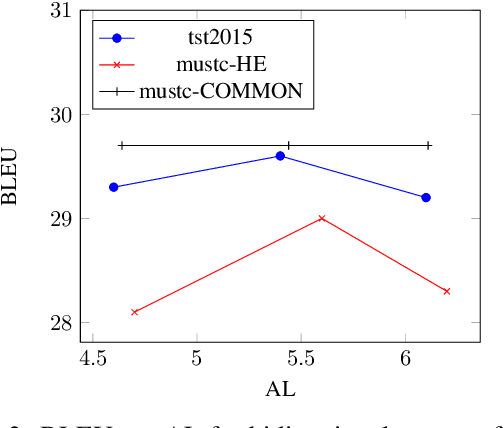
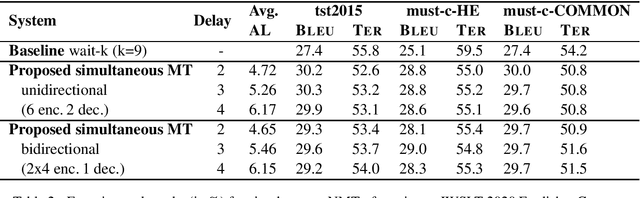
In simultaneous machine translation, the objective is to determine when to produce a partial translation given a continuous stream of source words, with a trade-off between latency and quality. We propose a neural machine translation (NMT) model that makes dynamic decisions when to continue feeding on input or generate output words. The model is composed of two main components: one to dynamically decide on ending a source chunk, and another that translates the consumed chunk. We train the components jointly and in a manner consistent with the inference conditions. To generate chunked training data, we propose a method that utilizes word alignment while also preserving enough context. We compare models with bidirectional and unidirectional encoders of different depths, both on real speech and text input. Our results on the IWSLT 2020 English-to-German task outperform a wait-k baseline by 2.6 to 3.7% BLEU absolute.
Cumulative Adaptation for BLSTM Acoustic Models
Jun 14, 2019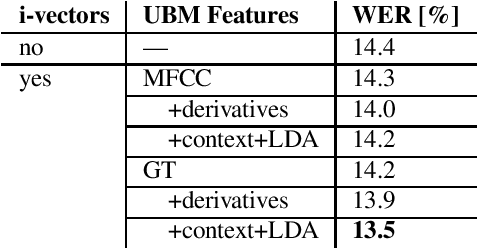
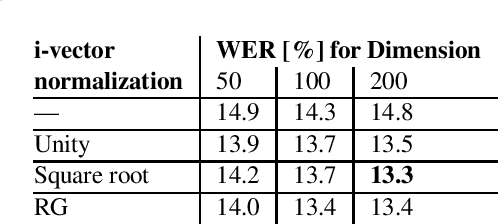
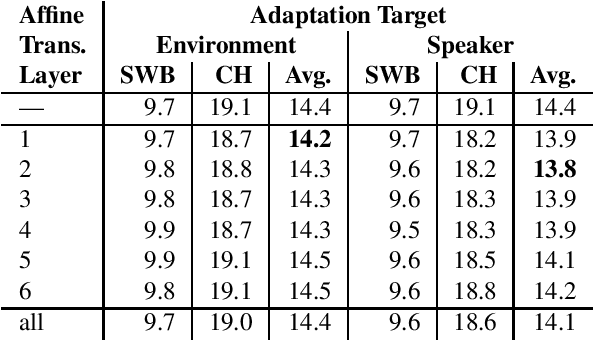
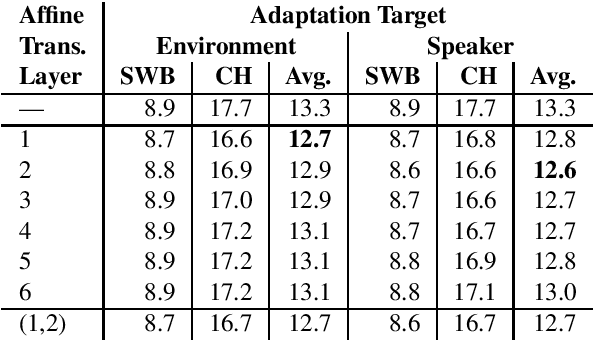
This paper addresses the robust speech recognition problem as an adaptation task. Specifically, we investigate the cumulative application of adaptation methods. A bidirectional Long Short-Term Memory (BLSTM) based neural network, capable of learning temporal relationships and translation invariant representations, is used for robust acoustic modelling. Further, i-vectors were used as an input to the neural network to perform instantaneous speaker and environment adaptation, providing 8\% relative improvement in word error rate on the NIST Hub5 2000 evaluation test set. By enhancing the first-pass i-vector based adaptation with a second-pass adaptation using speaker and environment dependent transformations within the network, a further relative improvement of 5\% in word error rate was achieved. We have reevaluated the features used to estimate i-vectors and their normalization to achieve the best performance in a modern large scale automatic speech recognition system.
A comprehensive study of batch construction strategies for recurrent neural networks in MXNet
May 05, 2017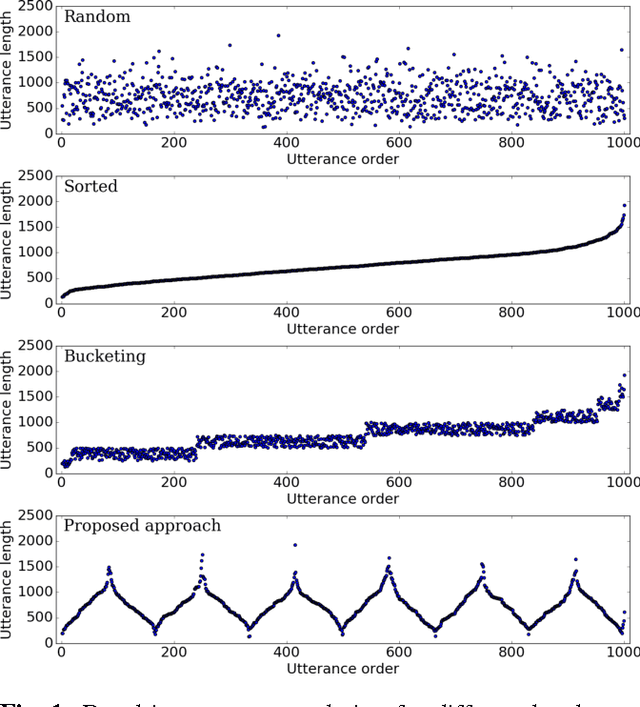
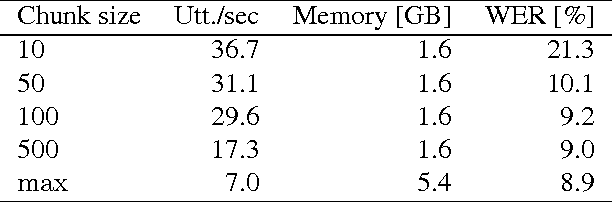
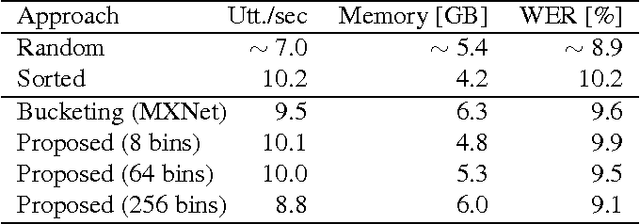
In this work we compare different batch construction methods for mini-batch training of recurrent neural networks. While popular implementations like TensorFlow and MXNet suggest a bucketing approach to improve the parallelization capabilities of the recurrent training process, we propose a simple ordering strategy that arranges the training sequences in a stochastic alternatingly sorted way. We compare our method to sequence bucketing as well as various other batch construction strategies on the CHiME-4 noisy speech recognition corpus. The experiments show that our alternated sorting approach is able to compete both in training time and recognition performance while being conceptually simpler to implement.