 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
LegoSLM: Connecting LLM with Speech Encoder using CTC Posteriors
May 16, 2025Recently, large-scale pre-trained speech encoders and Large Language Models (LLMs) have been released, which show state-of-the-art performance on a range of spoken language processing tasks including Automatic Speech Recognition (ASR). To effectively combine both models for better performance, continuous speech prompts, and ASR error correction have been adopted. However, these methods are prone to suboptimal performance or are inflexible. In this paper, we propose a new paradigm, LegoSLM, that bridges speech encoders and LLMs using the ASR posterior matrices. The speech encoder is trained to generate Connectionist Temporal Classification (CTC) posteriors over the LLM vocabulary, which are used to reconstruct pseudo-audio embeddings by computing a weighted sum of the LLM input embeddings. These embeddings are concatenated with text embeddings in the LLM input space. Using the well-performing USM and Gemma models as an example, we demonstrate that our proposed LegoSLM method yields good performance on both ASR and speech translation tasks. By connecting USM with Gemma models, we can get an average of 49% WERR over the USM-CTC baseline on 8 MLS testsets. The trained model also exhibits modularity in a range of settings -- after fine-tuning the Gemma model weights, the speech encoder can be switched and combined with the LLM in a zero-shot fashion. Additionally, we propose to control the decode-time influence of the USM and LLM using a softmax temperature, which shows effectiveness in domain adaptation.
Schema Augmentation for Zero-Shot Domain Adaptation in Dialogue State Tracking
Oct 31, 2024
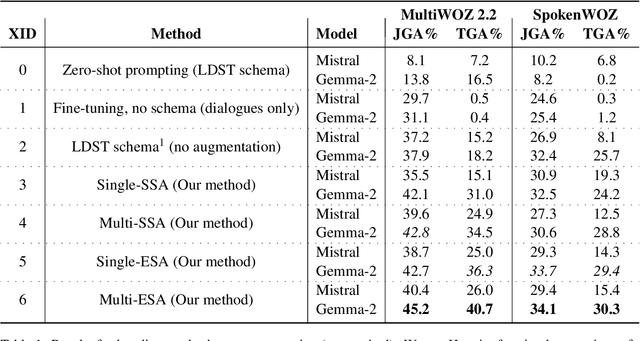
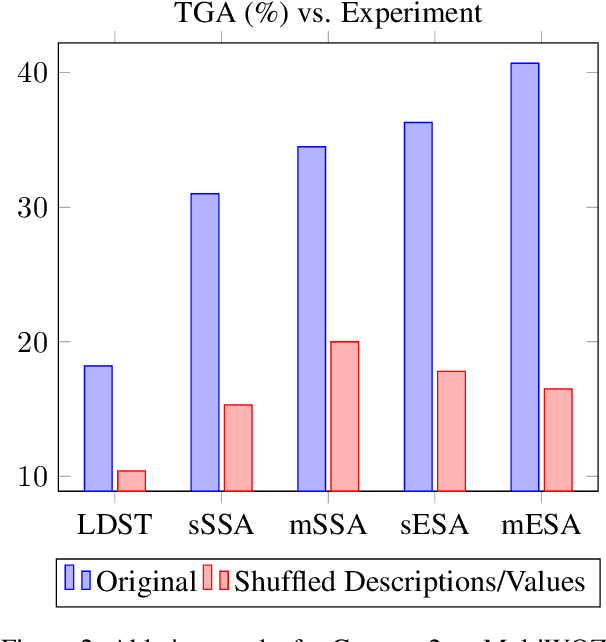
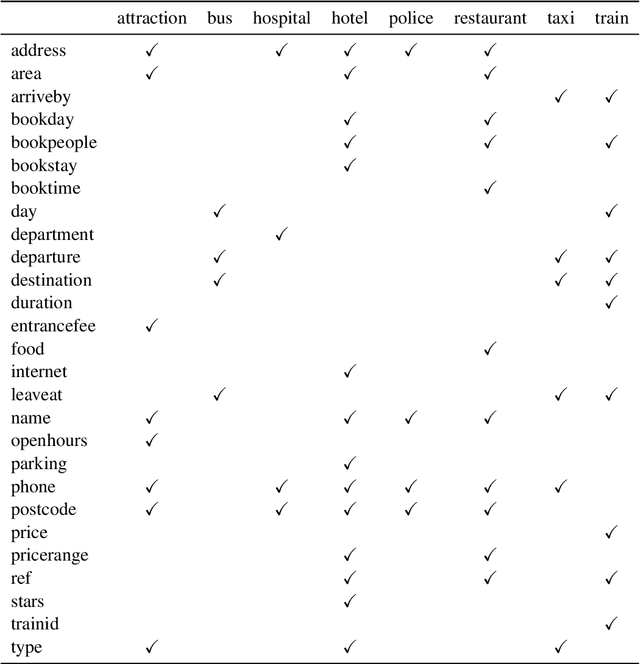
Zero-shot domain adaptation for dialogue state tracking (DST) remains a challenging problem in task-oriented dialogue (TOD) systems, where models must generalize to target domains unseen at training time. Current large language model approaches for zero-shot domain adaptation rely on prompting to introduce knowledge pertaining to the target domains. However, their efficacy strongly depends on prompt engineering, as well as the zero-shot ability of the underlying language model. In this work, we devise a novel data augmentation approach, Schema Augmentation, that improves the zero-shot domain adaptation of language models through fine-tuning. Schema Augmentation is a simple but effective technique that enhances generalization by introducing variations of slot names within the schema provided in the prompt. Experiments on MultiWOZ and SpokenWOZ showed that the proposed approach resulted in a substantial improvement over the baseline, in some experiments achieving over a twofold accuracy gain over unseen domains while maintaining equal or superior performance over all domains.
Zero-shot Cross-lingual Voice Transfer for TTS
Sep 20, 2024

In this paper, we introduce a zero-shot Voice Transfer (VT) module that can be seamlessly integrated into a multi-lingual Text-to-speech (TTS) system to transfer an individual's voice across languages. Our proposed VT module comprises a speaker-encoder that processes reference speech, a bottleneck layer, and residual adapters, connected to preexisting TTS layers. We compare the performance of various configurations of these components and report Mean Opinion Score (MOS) and Speaker Similarity across languages. Using a single English reference speech per speaker, we achieve an average voice transfer similarity score of 73% across nine target languages. Vocal characteristics contribute significantly to the construction and perception of individual identity. The loss of one's voice, due to physical or neurological conditions, can lead to a profound sense of loss, impacting one's core identity. As a case study, we demonstrate that our approach can not only transfer typical speech but also restore the voices of individuals with dysarthria, even when only atypical speech samples are available - a valuable utility for those who have never had typical speech or banked their voice. Cross-lingual typical audio samples, plus videos demonstrating voice restoration for dysarthric speakers are available here (google.github.io/tacotron/publications/zero_shot_voice_transfer).
STAB: Speech Tokenizer Assessment Benchmark
Sep 04, 2024
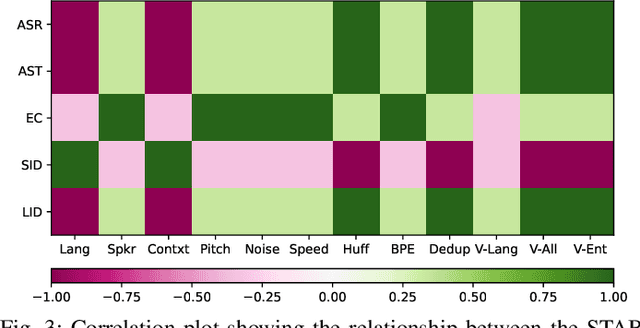
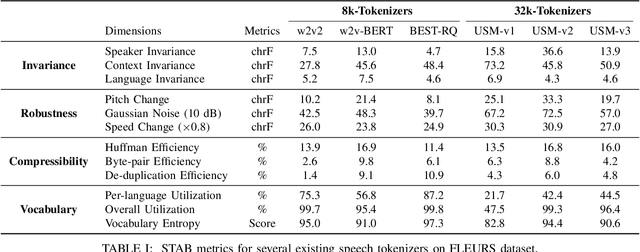
Representing speech as discrete tokens provides a framework for transforming speech into a format that closely resembles text, thus enabling the use of speech as an input to the widely successful large language models (LLMs). Currently, while several speech tokenizers have been proposed, there is ambiguity regarding the properties that are desired from a tokenizer for specific downstream tasks and its overall generalizability. Evaluating the performance of tokenizers across different downstream tasks is a computationally intensive effort that poses challenges for scalability. To circumvent this requirement, we present STAB (Speech Tokenizer Assessment Benchmark), a systematic evaluation framework designed to assess speech tokenizers comprehensively and shed light on their inherent characteristics. This framework provides a deeper understanding of the underlying mechanisms of speech tokenization, thereby offering a valuable resource for expediting the advancement of future tokenizer models and enabling comparative analysis using a standardized benchmark. We evaluate the STAB metrics and correlate this with downstream task performance across a range of speech tasks and tokenizer choices.
Speculative Speech Recognition by Audio-Prefixed Low-Rank Adaptation of Language Models
Jul 05, 2024

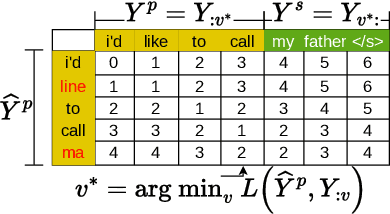

This paper explores speculative speech recognition (SSR), where we empower conventional automatic speech recognition (ASR) with speculation capabilities, allowing the recognizer to run ahead of audio. We introduce a metric for measuring SSR performance and we propose a model which does SSR by combining a RNN-Transducer-based ASR system with an audio-prefixed language model (LM). The ASR system transcribes ongoing audio and feeds the resulting transcripts, along with an audio-dependent prefix, to the LM, which speculates likely completions for the transcriptions. We experiment with a variety of ASR datasets on which show the efficacy our method and the feasibility of SSR as a method of reducing ASR latency.
Speech Prefix-Tuning with RNNT Loss for Improving LLM Predictions
Jun 20, 2024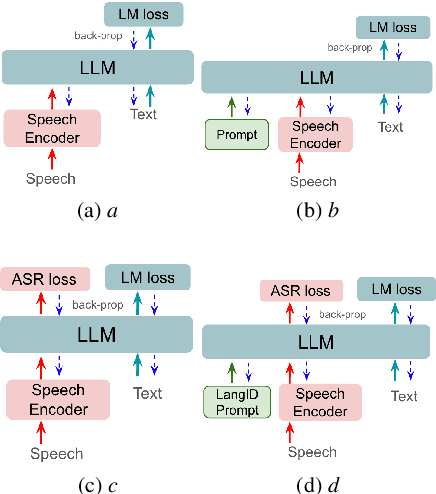



In this paper, we focus on addressing the constraints faced when applying LLMs to ASR. Recent works utilize prefixLM-type models, which directly apply speech as a prefix to LLMs for ASR. We have found that optimizing speech prefixes leads to better ASR performance and propose applying RNNT loss to perform speech prefix-tuning. This is a simple approach and does not increase the model complexity or alter the inference pipeline. We also propose language-based soft prompting to further improve with frozen LLMs. Empirical analysis on realtime testset from 10 Indic languages demonstrate that our proposed speech prefix-tuning yields improvements with both frozen and fine-tuned LLMs. Our recognition results on an average of 10 Indics show that the proposed prefix-tuning with RNNT loss results in a 12\% relative improvement in WER over the baseline with a fine-tuned LLM. Our proposed approches with the frozen LLM leads to a 31\% relative improvement over basic soft-prompting prefixLM.
ASTRA: Aligning Speech and Text Representations for Asr without Sampling
Jun 10, 2024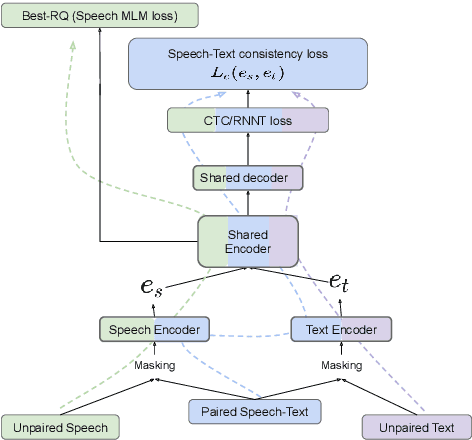



This paper introduces ASTRA, a novel method for improving Automatic Speech Recognition (ASR) through text injection.Unlike prevailing techniques, ASTRA eliminates the need for sampling to match sequence lengths between speech and text modalities. Instead, it leverages the inherent alignments learned within CTC/RNNT models. This approach offers the following two advantages, namely, avoiding potential misalignment between speech and text features that could arise from upsampling and eliminating the need for models to accurately predict duration of sub-word tokens. This novel formulation of modality (length) matching as a weighted RNNT objective matches the performance of the state-of-the-art duration-based methods on the FLEURS benchmark, while opening up other avenues of research in speech processing.
Text Injection for Neural Contextual Biasing
Jun 05, 2024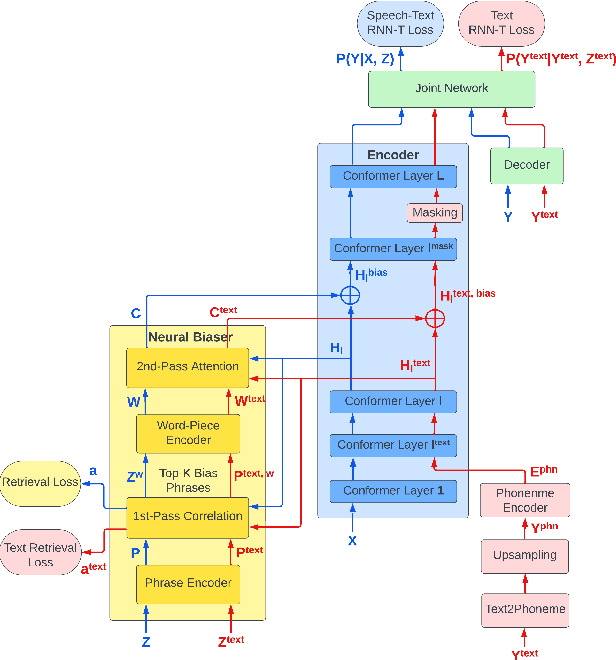
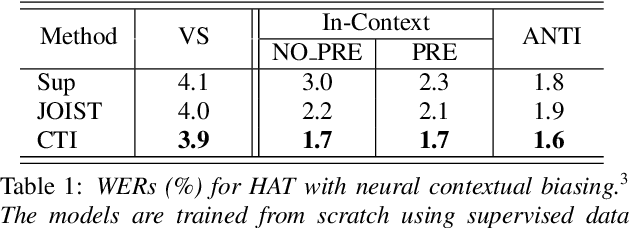
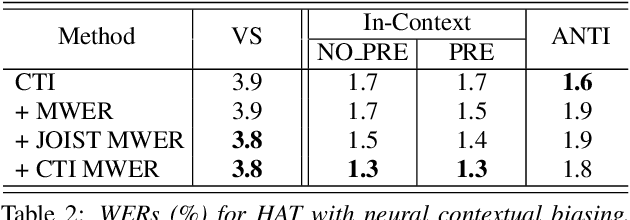
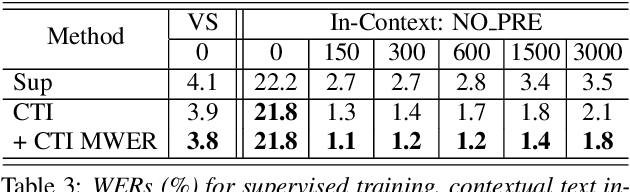
Neural contextual biasing effectively improves automatic speech recognition (ASR) for crucial phrases within a speaker's context, particularly those that are infrequent in the training data. This work proposes contextual text injection (CTI) to enhance contextual ASR. CTI leverages not only the paired speech-text data, but also a much larger corpus of unpaired text to optimize the ASR model and its biasing component. Unpaired text is converted into speech-like representations and used to guide the model's attention towards relevant bias phrases. Moreover, we introduce a contextual text-injected (CTI) minimum word error rate (MWER) training, which minimizes the expected WER caused by contextual biasing when unpaired text is injected into the model. Experiments show that CTI with 100 billion text sentences can achieve up to 43.3% relative WER reduction from a strong neural biasing model. CTI-MWER provides a further relative improvement of 23.5%.
* 5 pages, 1 figure
Extending Multilingual Speech Synthesis to 100+ Languages without Transcribed Data
Feb 29, 2024



Collecting high-quality studio recordings of audio is challenging, which limits the language coverage of text-to-speech (TTS) systems. This paper proposes a framework for scaling a multilingual TTS model to 100+ languages using found data without supervision. The proposed framework combines speech-text encoder pretraining with unsupervised training using untranscribed speech and unspoken text data sources, thereby leveraging massively multilingual joint speech and text representation learning. Without any transcribed speech in a new language, this TTS model can generate intelligible speech in >30 unseen languages (CER difference of <10% to ground truth). With just 15 minutes of transcribed, found data, we can reduce the intelligibility difference to 1% or less from the ground-truth, and achieve naturalness scores that match the ground-truth in several languages.