 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA: Aligning Speech and Text Representations for Asr without Sampling
Paper and Code
Jun 10, 2024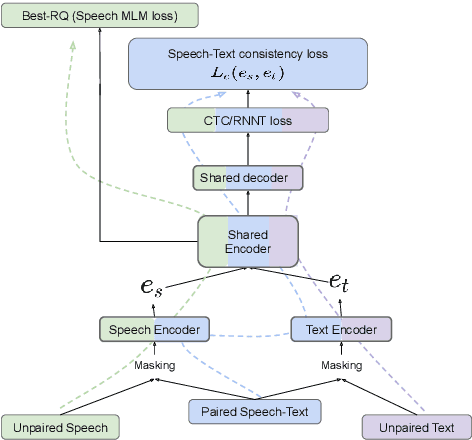



This paper introduces ASTRA, a novel method for improving Automatic Speech Recognition (ASR) through text injection.Unlike prevailing techniques, ASTRA eliminates the need for sampling to match sequence lengths between speech and text modalities. Instead, it leverages the inherent alignments learned within CTC/RNNT models. This approach offers the following two advantages, namely, avoiding potential misalignment between speech and text features that could arise from upsampling and eliminating the need for models to accurately predict duration of sub-word tokens. This novel formulation of modality (length) matching as a weighted RNNT objective matches the performance of the state-of-the-art duration-based methods on the FLEURS benchmark, while opening up other avenues of research in speech processing.