 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA: Aligning Speech and Text Representations for Asr without Sampling
Jun 10, 2024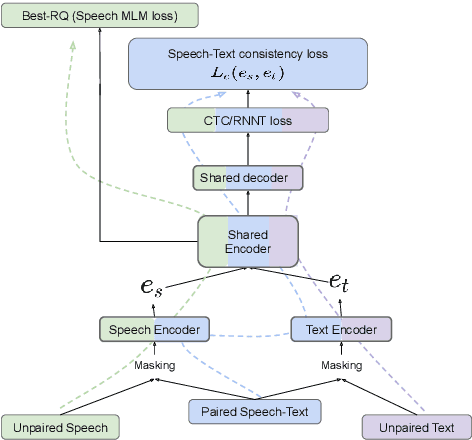



This paper introduces ASTRA, a novel method for improving Automatic Speech Recognition (ASR) through text injection.Unlike prevailing techniques, ASTRA eliminates the need for sampling to match sequence lengths between speech and text modalities. Instead, it leverages the inherent alignments learned within CTC/RNNT models. This approach offers the following two advantages, namely, avoiding potential misalignment between speech and text features that could arise from upsampling and eliminating the need for models to accurately predict duration of sub-word tokens. This novel formulation of modality (length) matching as a weighted RNNT objective matches the performance of the state-of-the-art duration-based methods on the FLEURS benchmark, while opening up other avenues of research in speech processing.
Audio-AdapterFusion: A Task-ID-free Approach for Efficient and Non-Destructive Multi-task Speech Recognition
Oct 17, 2023Adapters are an efficient, composable alternative to full fine-tuning of pre-trained models and help scale the deployment of large ASR models to many tasks. In practice, a task ID is commonly prepended to the input during inference to route to single-task adapters for the specified task. However, one major limitation of this approach is that the task ID may not be known during inference, rendering it unsuitable for most multi-task settings. To address this, we propose three novel task-ID-free methods to combine single-task adapters in multi-task ASR and investigate two learning algorithms for training. We evaluate our methods on 10 test sets from 4 diverse ASR tasks and show that our methods are non-destructive and parameter-efficient. While only updating 17% of the model parameters, our methods can achieve an 8% mean WER improvement relative to full fine-tuning and are on-par with task-ID adapter routing.
Using Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023



Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
Bi-Objective Community Detection (BOCD) in Networks using Genetic Algorithm
Sep 16, 2011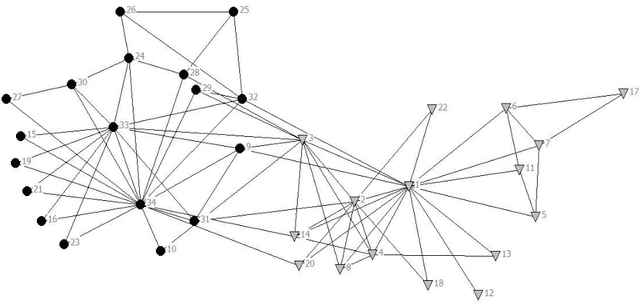

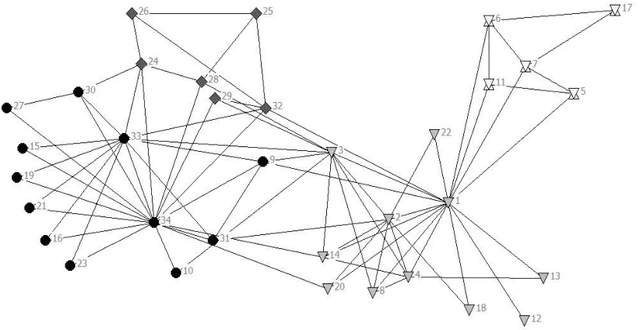
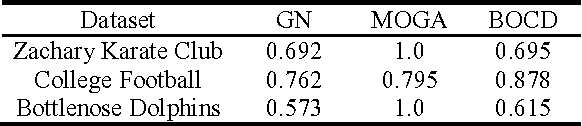
A lot of research effort has been put into community detection from all corners of academic interest such as physics, mathematics and computer science. In this paper I have proposed a Bi-Objective Genetic Algorithm for community detection which maximizes modularity and community score. Then the results obtained for both benchmark and real life data sets are compared with other algorithms using the modularity and MNI performance metrics. The results show that the BOCD algorithm is capable of successfully detecting community structure in both real life and synthetic datasets, as well as improving upon the performance of previous techniques.
Application of the Modified 2-opt and Jumping Gene Operators in Multi-Objective Genetic Algorithm to solve MOTSP
Sep 06, 2011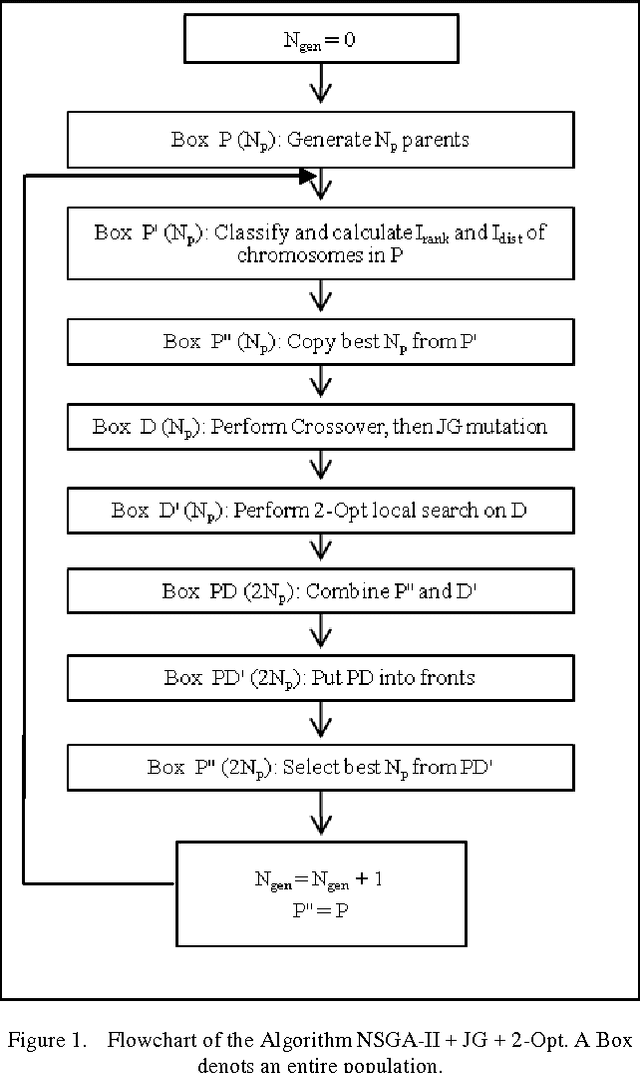
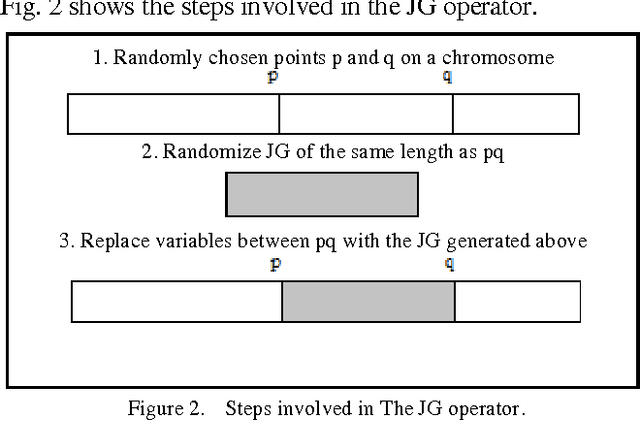
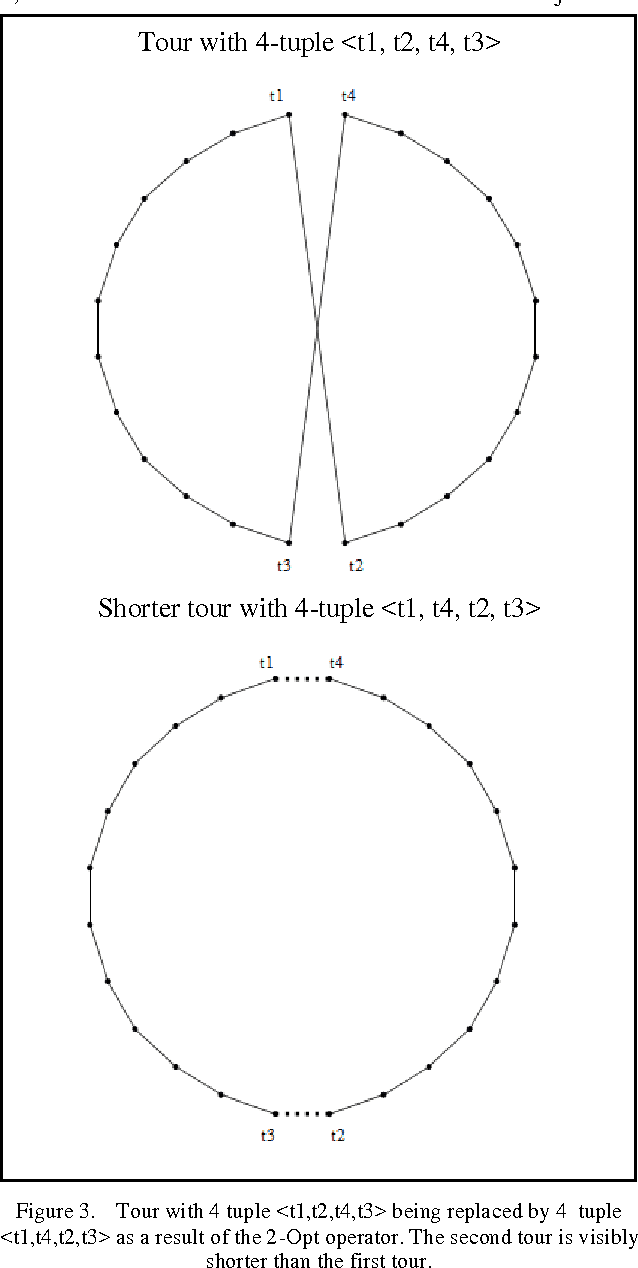

Evolutionary Multi-Objective Optimization is becoming a hot research area and quite a few papers regarding these algorithms have been published. However the role of local search techniques has not been expanded adequately. This paper studies the role of a local search technique called 2-opt for the Multi-Objective Travelling Salesman Problem (MOTSP). A new mutation operator called Jumping Gene (JG) is also used. Since 2-opt operator was intended for the single objective TSP, its domain has been expanded to MOTSP in this paper. This new technique is applied to the list of KroAB100 cities.