 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023



Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
Detecting Deficient Coverage in Colonoscopies
Jan 26, 2020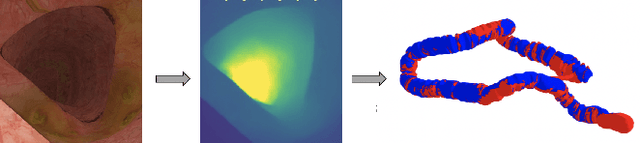
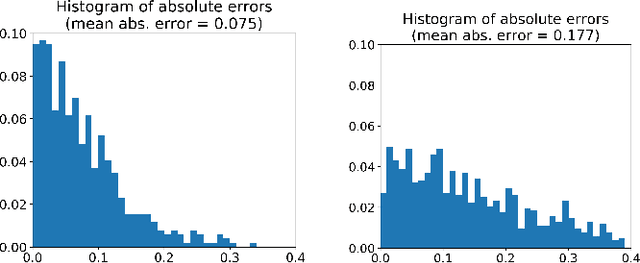
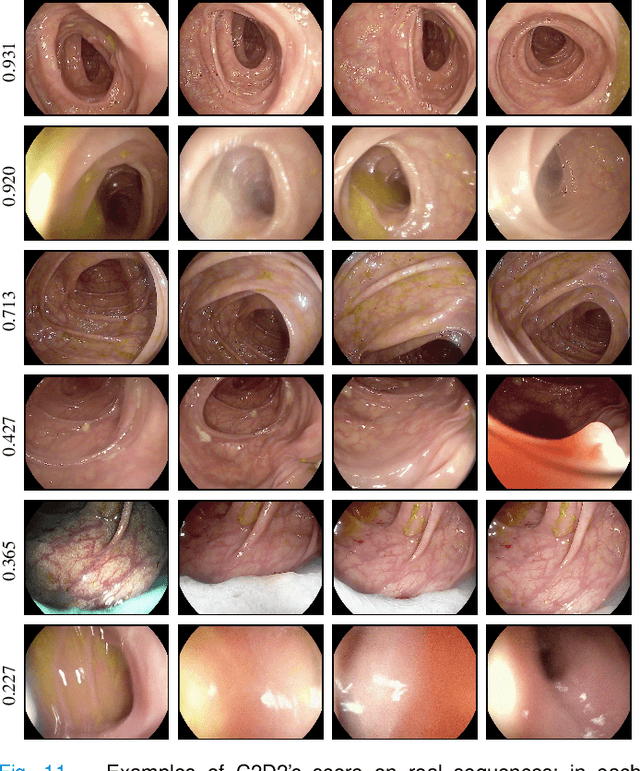
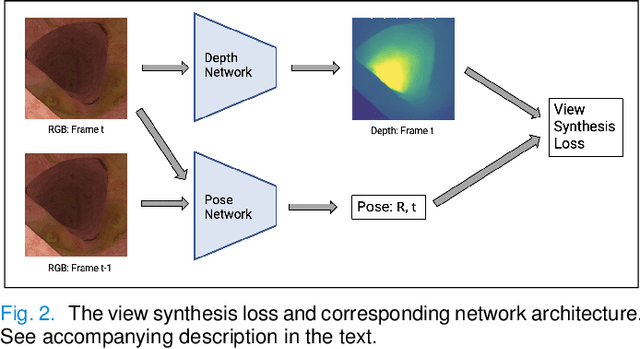
Colorectal Cancer (CRC) is a global health problem, resulting in 900K deaths per year. Colonoscopy is the tool of choice for preventing CRC, by detecting polyps before they become cancerous, and removing them. However, colonoscopy is hampered by the fact that endoscopists routinely miss an average of 22-28% of polyps. While some of these missed polyps appear in the endoscopist's field of view, others are missed simply because of substandard coverage of the procedure, i.e. not all of the colon is seen. This paper attempts to rectify the problem of substandard coverage in colonoscopy through the introduction of the C2D2 (Colonoscopy Coverage Deficiency via Depth) algorithm which detects deficient coverage, and can thereby alert the endoscopist to revisit a given area. More specifically, C2D2 consists of two separate algorithms: the first performs depth estimation of the colon given an ordinary RGB video stream; while the second computes coverage given these depth estimates. Rather than compute coverage for the entire colon, our algorithm computes coverage locally, on a segment-by-segment basis; C2D2 can then indicate in real-time whether a particular area of the colon has suffered from deficient coverage, and if so the endoscopist can return to that area. Our coverage algorithm is the first such algorithm to be evaluated in a large-scale way; while our depth estimation technique is the first calibration-free unsupervised method applied to colonoscopies. The C2D2 algorithm achieves state of the art results in the detection of deficient coverage: it is 2.4 times more accurate than human experts.
Rethinking Lossy Compression: The Rate-Distortion-Perception Tradeoff
Jan 23, 2019



Lossy compression algorithms are typically designed and analyzed through the lens of Shannon's rate-distortion theory, where the goal is to achieve the lowest possible distortion (e.g., low MSE or high SSIM) at any given bit rate. However, in recent years, it has become increasingly accepted that "low distortion" is not a synonym for "high perceptual quality", and in fact optimization of one often comes at the expense of the other. In light of this understanding, it is natural to seek for a generalization of rate-distortion theory which takes perceptual quality into account. In this paper, we adopt the mathematical definition of perceptual quality recently proposed by Blau & Michaeli (2018), and use it to study the three-way tradeoff between rate, distortion, and perception. We show that restricting the perceptual quality to be high, generally leads to an elevation of the rate-distortion curve, thus necessitating a sacrifice in either rate or distortion. We prove several fundamental properties of this triple-tradeoff, calculate it in closed form for a Bernoulli source, and illustrate it visually on a toy MNIST example.
2018 PIRM Challenge on Perceptual Image Super-resolution
Oct 03, 2018
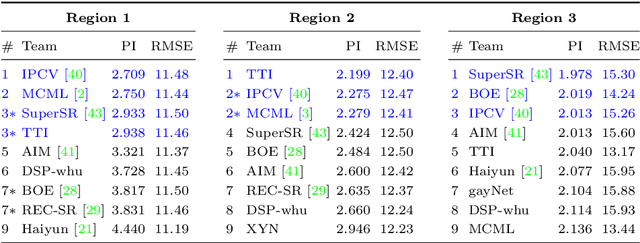
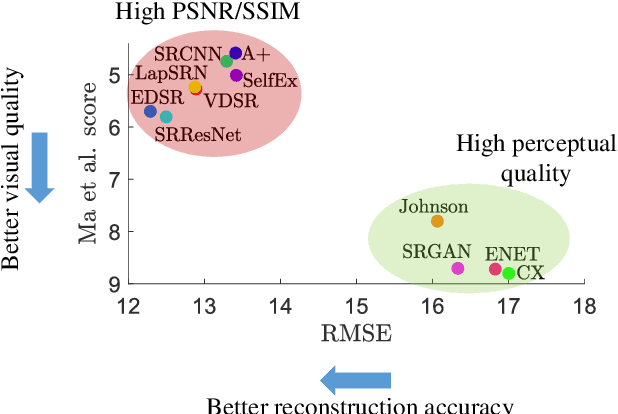

This paper reports on the 2018 PIRM challenge on perceptual super-resolution (SR), held in conjunction with the Perceptual Image Restoration and Manipulation (PIRM) workshop at ECCV 2018. In contrast to previous SR challenges, our evaluation methodology jointly quantifies accuracy and perceptual quality, therefore enabling perceptual-driven methods to compete alongside algorithms that target PSNR maximization. Twenty-one participating teams introduced algorithms which well-improved upon the existing state-of-the-art methods in perceptual SR, as confirmed by a human opinion study. We also analyze popular image quality measures and draw conclusions regarding which of them correlates best with human opinion scores. We conclude with an analysis of the current trends in perceptual SR, as reflected from the leading submissions.
The Perception-Distortion Tradeoff
Mar 16, 2018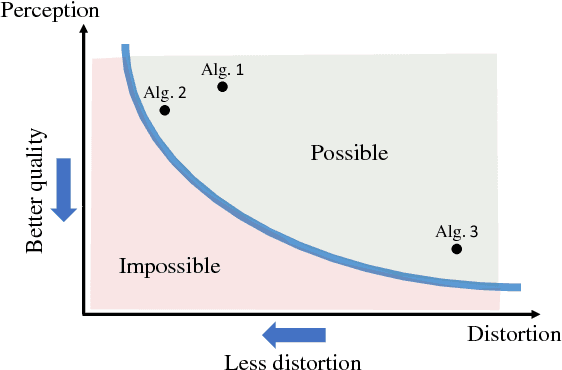



Image restoration algorithms are typically evaluated by some distortion measure (e.g. PSNR, SSIM, IFC, VIF) or by human opinion scores that quantify perceived perceptual quality. In this paper, we prove mathematically that distortion and perceptual quality are at odds with each other. Specifically, we study the optimal probability for correctly discriminating the outputs of an image restoration algorithm from real images. We show that as the mean distortion decreases, this probability must increase (indicating worse perceptual quality). As opposed to the common belief, this result holds true for any distortion measure, and is not only a problem of the PSNR or SSIM criteria. However, as we show experimentally, for some measures it is less severe (e.g. distance between VGG features). We also show that generative-adversarial-nets (GANs) provide a principled way to approach the perception-distortion bound. This constitutes theoretical support to their observed success in low-level vision tasks. Based on our analysis, we propose a new methodology for evaluating image restoration methods, and use it to perform an extensive comparison between recent super-resolution algorithms.
Non-Redundant Spectral Dimensionality Reduction
Apr 20, 2017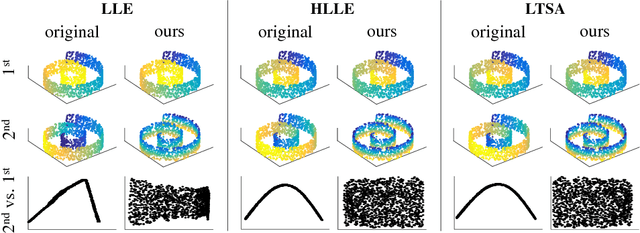



Spectral dimensionality reduction algorithms are widely used in numerous domains, including for recognition, segmentation, tracking and visualization. However, despite their popularity, these algorithms suffer from a major limitation known as the "repeated Eigen-directions" phenomenon. That is, many of the embedding coordinates they produce typically capture the same direction along the data manifold. This leads to redundant and inefficient representations that do not reveal the true intrinsic dimensionality of the data. In this paper, we propose a general method for avoiding redundancy in spectral algorithms. Our approach relies on replacing the orthogonality constraints underlying those methods by unpredictability constraints. Specifically, we require that each embedding coordinate be unpredictable (in the statistical sense) from all previous ones. We prove that these constraints necessarily prevent redundancy, and provide a simple technique to incorporate them into existing methods. As we illustrate on challenging high-dimensional scenarios, our approach produces significantly more informative and compact representations, which improve visualization and classification tasks.