 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp-It: A Multi-view to Multi-view Diffusion Model for 3D Synthesis and Manipulation
Dec 03, 2024Advancements in text-to-image diffusion models have led to significant progress in fast 3D content creation. One common approach is to generate a set of multi-view images of an object, and then reconstruct it into a 3D model. However, this approach bypasses the use of a native 3D representation of the object and is hence prone to geometric artifacts and limited in controllability and manipulation capabilities. An alternative approach involves native 3D generative models that directly produce 3D representations. These models, however, are typically limited in their resolution, resulting in lower quality 3D objects. In this work, we bridge the quality gap between methods that directly generate 3D representations and ones that reconstruct 3D objects from multi-view images. We introduce a multi-view to multi-view diffusion model called Sharp-It, which takes a 3D consistent set of multi-view images rendered from a low-quality object and enriches its geometric details and texture. The diffusion model operates on the multi-view set in parallel, in the sense that it shares features across the generated views. A high-quality 3D model can then be reconstructed from the enriched multi-view set. By leveraging the advantages of both 2D and 3D approaches, our method offers an efficient and controllable method for high-quality 3D content creation. We demonstrate that Sharp-It enables various 3D applications, such as fast synthesis, editing, and controlled generation, while attaining high-quality assets.
FreeAugment: Data Augmentation Search Across All Degrees of Freedom
Sep 07, 2024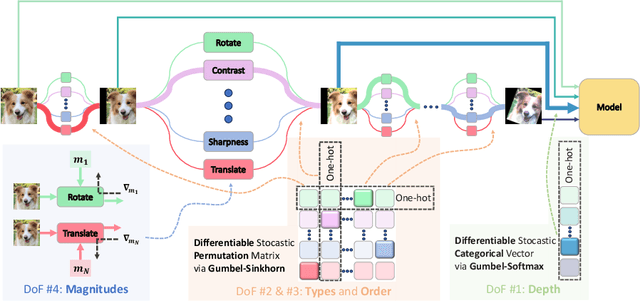
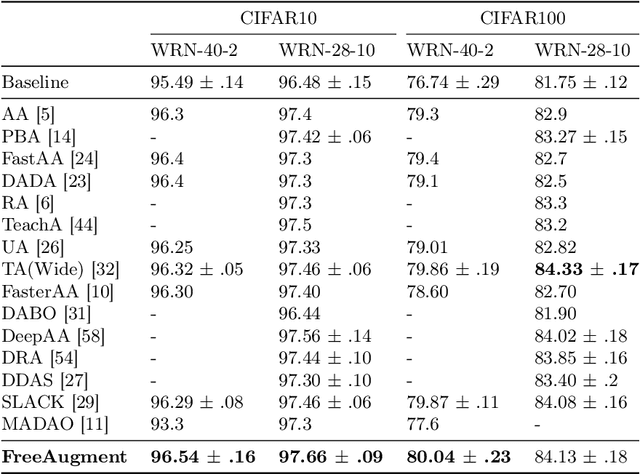
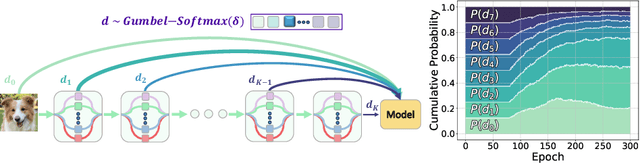

Data augmentation has become an integral part of deep learning, as it is known to improve the generalization capabilities of neural networks. Since the most effective set of image transformations differs between tasks and domains, automatic data augmentation search aims to alleviate the extreme burden of manually finding the optimal image transformations. However, current methods are not able to jointly optimize all degrees of freedom: (1) the number of transformations to be applied, their (2) types, (3) order, and (4) magnitudes. Many existing methods risk picking the same transformation more than once, limit the search to two transformations only, or search for the number of transformations exhaustively or iteratively in a myopic manner. Our approach, FreeAugment, is the first to achieve global optimization of all four degrees of freedom simultaneously, using a fully differentiable method. It efficiently learns the number of transformations and a probability distribution over their permutations, inherently refraining from redundant repetition while sampling. Our experiments demonstrate that this joint learning of all degrees of freedom significantly improves performance, achieving state-of-the-art results on various natural image benchmarks and beyond across other domains. Project page at https://tombekor.github.io/FreeAugment-web
STMPL: Human Soft-Tissue Simulation
Mar 13, 2024



In various applications, such as virtual reality and gaming, simulating the deformation of soft tissues in the human body during interactions with external objects is essential. Traditionally, Finite Element Methods (FEM) have been employed for this purpose, but they tend to be slow and resource-intensive. In this paper, we propose a unified representation of human body shape and soft tissue with a data-driven simulator of non-rigid deformations. This approach enables rapid simulation of realistic interactions. Our method builds upon the SMPL model, which generates human body shapes considering rigid transformations. We extend SMPL by incorporating a soft tissue layer and an intuitive representation of external forces applied to the body during object interactions. Specifically, we mapped the 3D body shape and soft tissue and applied external forces to 2D UV maps. Leveraging a UNET architecture designed for 2D data, our approach achieves high-accuracy inference in real time. Our experiment shows that our method achieves plausible deformation of the soft tissue layer, even for unseen scenarios.
Diverse Imagenet Models Transfer Better
Apr 19, 2022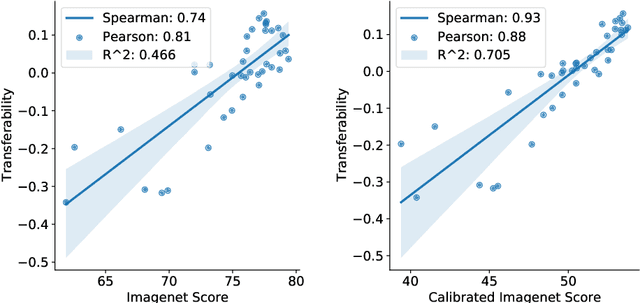
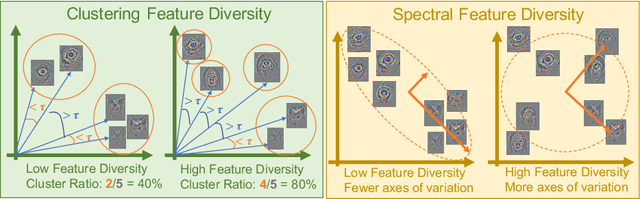
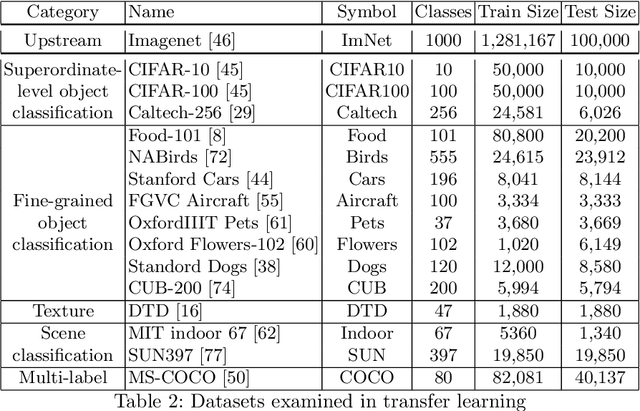
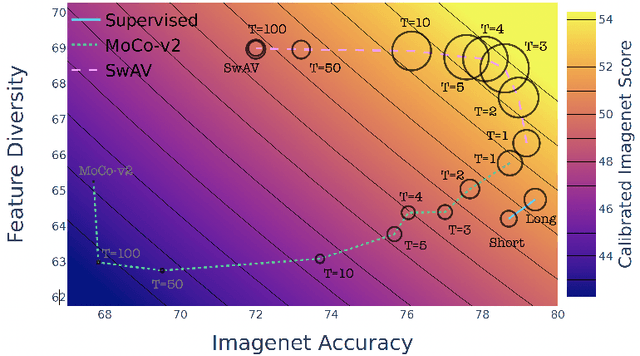
A commonly accepted hypothesis is that models with higher accuracy on Imagenet perform better on other downstream tasks, leading to much research dedicated to optimizing Imagenet accuracy. Recently this hypothesis has been challenged by evidence showing that self-supervised models transfer better than their supervised counterparts, despite their inferior Imagenet accuracy. This calls for identifying the additional factors, on top of Imagenet accuracy, that make models transferable. In this work we show that high diversity of the features learnt by the model promotes transferability jointly with Imagenet accuracy. Encouraged by the recent transferability results of self-supervised models, we propose a method that combines self-supervised and supervised pretraining to generate models with both high diversity and high accuracy, and as a result high transferability. We demonstrate our results on several architectures and multiple downstream tasks, including both single-label and multi-label classification.
IQNAS: Interpretable Integer Quadratic Programming Neural Architecture Search
Oct 24, 2021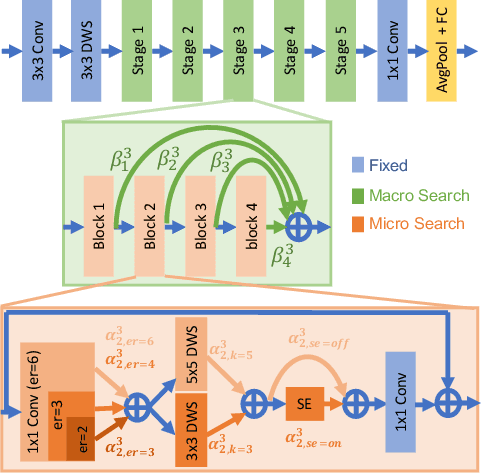
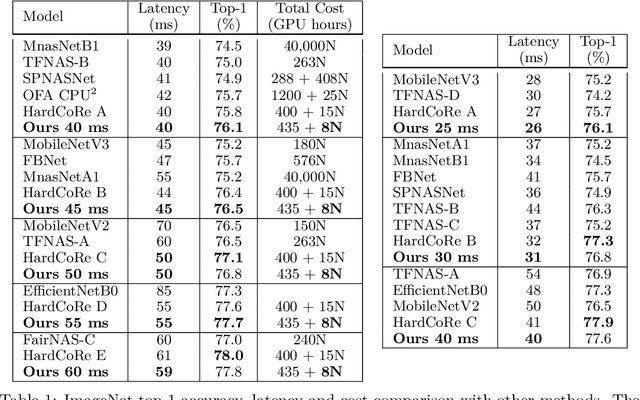
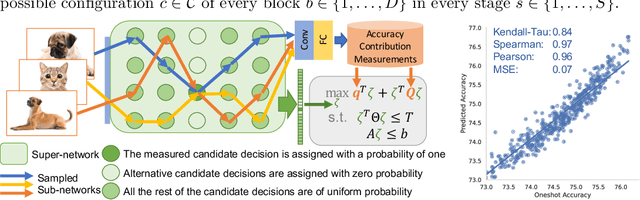
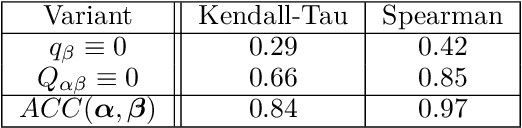
Realistic use of neural networks often requires adhering to multiple constraints on latency, energy and memory among others. A popular approach to find fitting networks is through constrained Neural Architecture Search (NAS). However, previous methods use complicated predictors for the accuracy of the network. Those predictors are hard to interpret and sensitive to many hyperparameters to be tuned, hence, the resulting accuracy of the generated models is often harmed. In this work we resolve this by introducing Interpretable Integer Quadratic programming Neural Architecture Search (IQNAS), that is based on an accurate and simple quadratic formulation of both the accuracy predictor and the expected resource requirement, together with a scalable search method with theoretical guarantees. The simplicity of our proposed predictor together with the intuitive way it is constructed bring interpretability through many insights about the contribution of different design choices. For example, we find that in the examined search space, adding depth and width is more effective at deeper stages of the network and at the beginning of each resolution stage. Our experiments show that IQNAS generates comparable to or better architectures than other state-of-the-art NAS methods within a reduced search cost for each additional generated network, while strictly satisfying the resource constraints.
Multi-label Classification with Partial Annotations using Class-aware Selective Loss
Oct 21, 2021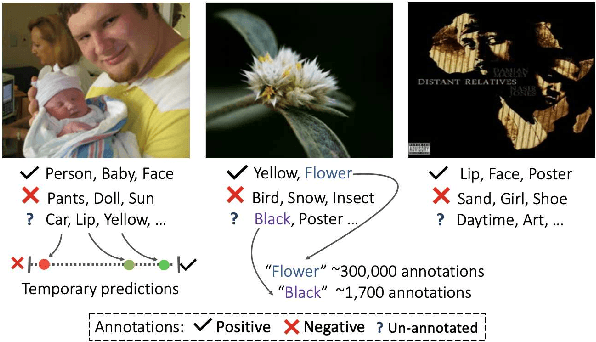
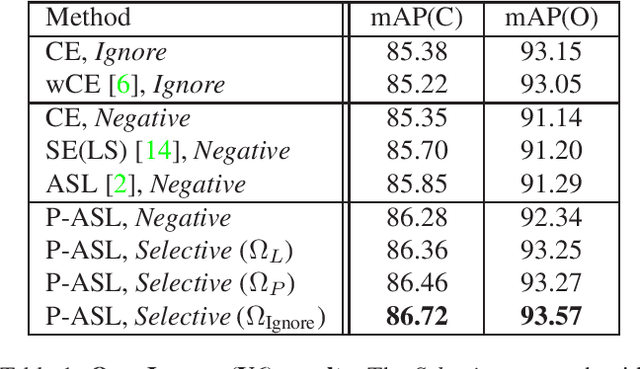
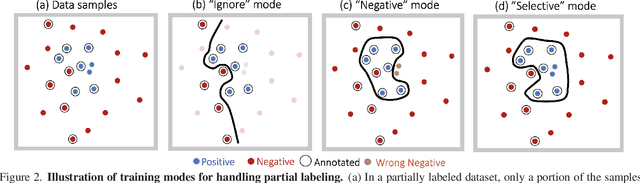

Large-scale multi-label classification datasets are commonly, and perhaps inevitably, partially annotated. That is, only a small subset of labels are annotated per sample. Different methods for handling the missing labels induce different properties on the model and impact its accuracy. In this work, we analyze the partial labeling problem, then propose a solution based on two key ideas. First, un-annotated labels should be treated selectively according to two probability quantities: the class distribution in the overall dataset and the specific label likelihood for a given data sample. We propose to estimate the class distribution using a dedicated temporary model, and we show its improved efficiency over a naive estimation computed using the dataset's partial annotations. Second, during the training of the target model, we emphasize the contribution of annotated labels over originally un-annotated labels by using a dedicated asymmetric loss. With our novel approach, we achieve state-of-the-art results on OpenImages dataset (e.g. reaching 87.3 mAP on V6). In addition, experiments conducted on LVIS and simulated-COCO demonstrate the effectiveness of our approach. Code is available at https://github.com/Alibaba-MIIL/PartialLabelingCSL.
PETA: Photo Albums Event Recognition using Transformers Attention
Sep 26, 2021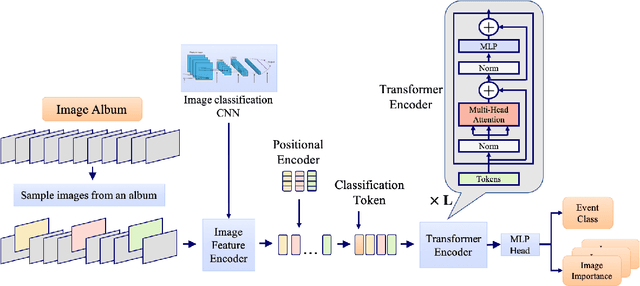
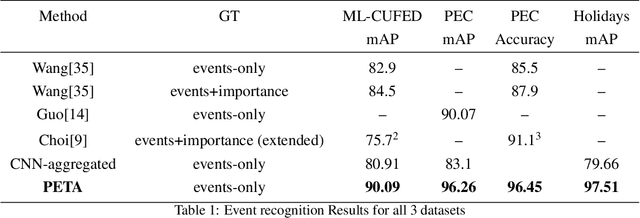

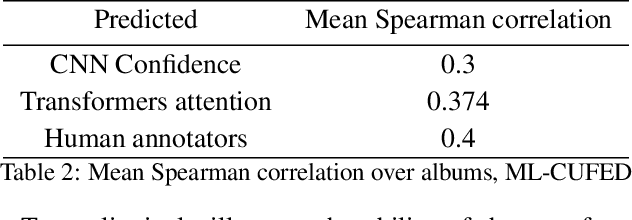
In recent years the amounts of personal photos captured increased significantly, giving rise to new challenges in multi-image understanding and high-level image understanding. Event recognition in personal photo albums presents one challenging scenario where life events are recognized from a disordered collection of images, including both relevant and irrelevant images. Event recognition in images also presents the challenge of high-level image understanding, as opposed to low-level image object classification. In absence of methods to analyze multiple inputs, previous methods adopted temporal mechanisms, including various forms of recurrent neural networks. However, their effective temporal window is local. In addition, they are not a natural choice given the disordered characteristic of photo albums. We address this gap with a tailor-made solution, combining the power of CNNs for image representation and transformers for album representation to perform global reasoning on image collection, offering a practical and efficient solution for photo albums event recognition. Our solution reaches state-of-the-art results on 3 prominent benchmarks, achieving above 90\% mAP on all datasets. We further explore the related image-importance task in event recognition, demonstrating how the learned attentions correlate with the human-annotated importance for this subjective task, thus opening the door for new applications.
Semantic Diversity Learning for Zero-Shot Multi-label Classification
May 12, 2021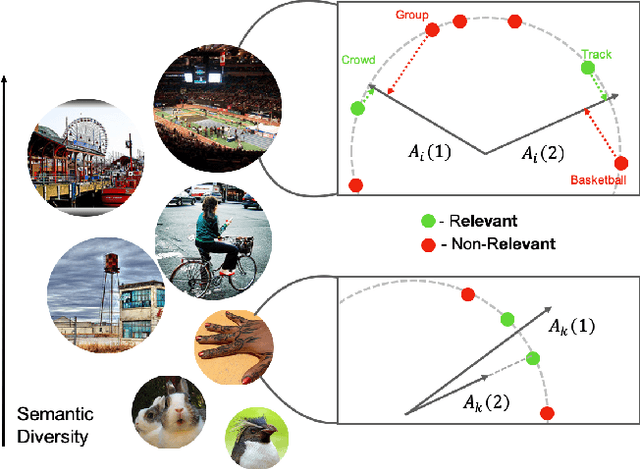
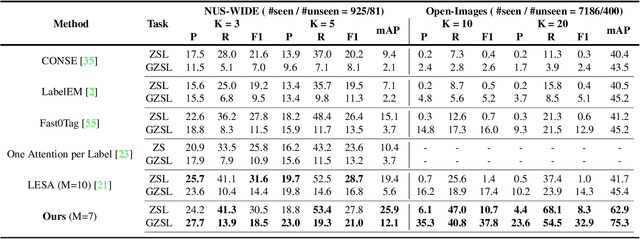
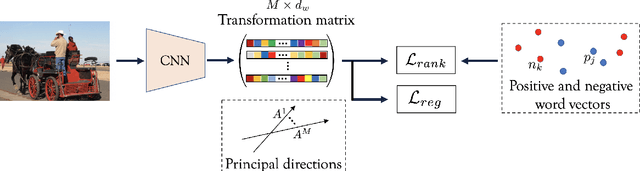
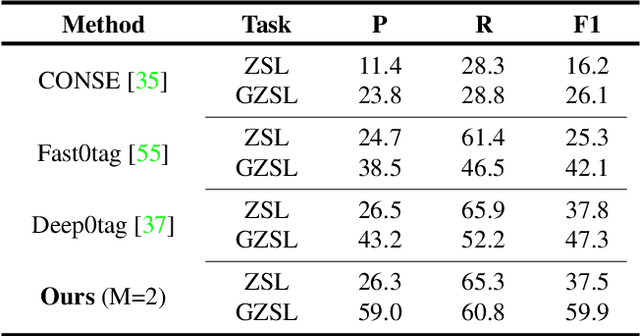
Training a neural network model for recognizing multiple labels associated with an image, including identifying unseen labels, is challenging, especially for images that portray numerous semantically diverse labels. As challenging as this task is, it is an essential task to tackle since it represents many real-world cases, such as image retrieval of natural images. We argue that using a single embedding vector to represent an image, as commonly practiced, is not sufficient to rank both relevant seen and unseen labels accurately. This study introduces an end-to-end model training for multi-label zero-shot learning that supports semantic diversity of the images and labels. We propose to use an embedding matrix having principal embedding vectors trained using a tailored loss function. In addition, during training, we suggest up-weighting in the loss function image samples presenting higher semantic diversity to encourage the diversity of the embedding matrix. Extensive experiments show that our proposed method improves the zero-shot model's quality in tag-based image retrieval achieving SoTA results on several common datasets (NUS-Wide, COCO, Open Images).
ImageNet-21K Pretraining for the Masses
May 04, 2021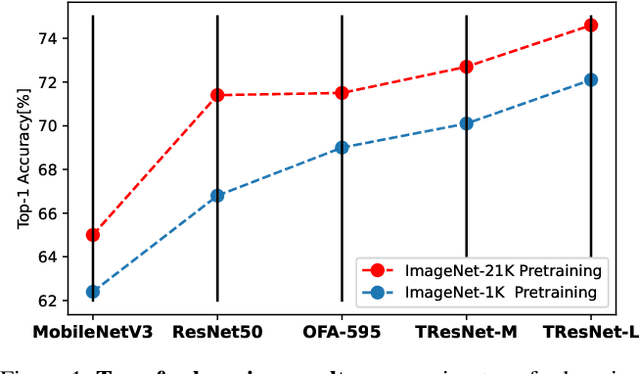

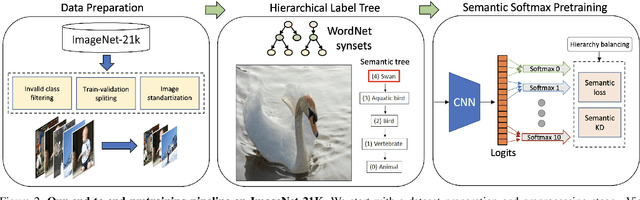
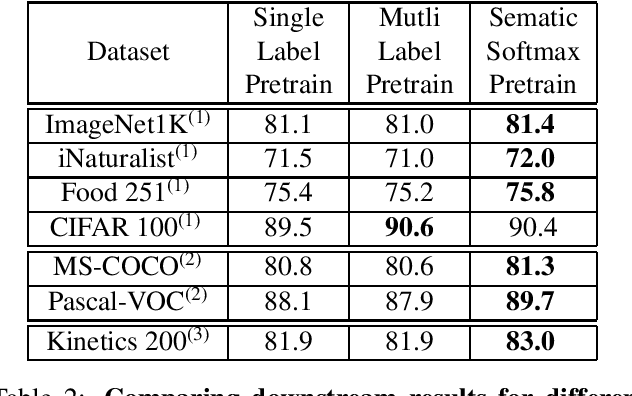
ImageNet-1K serves as the primary dataset for pretraining deep learning models for computer vision tasks. ImageNet-21K dataset, which contains more pictures and classes, is used less frequently for pretraining, mainly due to its complexity, and underestimation of its added value compared to standard ImageNet-1K pretraining. This paper aims to close this gap, and make high-quality efficient pretraining on ImageNet-21K available for everyone. Via a dedicated preprocessing stage, utilizing WordNet hierarchies, and a novel training scheme called semantic softmax, we show that various models, including small mobile-oriented models, significantly benefit from ImageNet-21K pretraining on numerous datasets and tasks. We also show that we outperform previous ImageNet-21K pretraining schemes for prominent new models like ViT. Our proposed pretraining pipeline is efficient, accessible, and leads to SoTA reproducible results, from a publicly available dataset. The training code and pretrained models are available at: https://github.com/Alibaba-MIIL/ImageNet21K
An Image is Worth 16x16 Words, What is a Video Worth?
Mar 25, 2021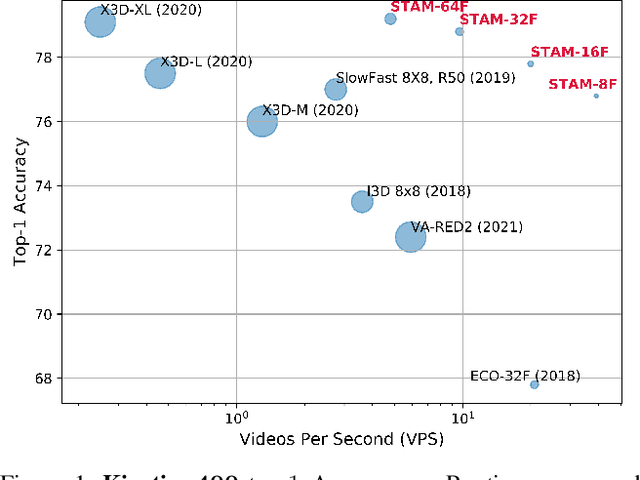
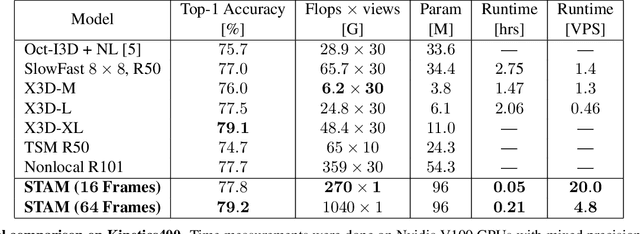

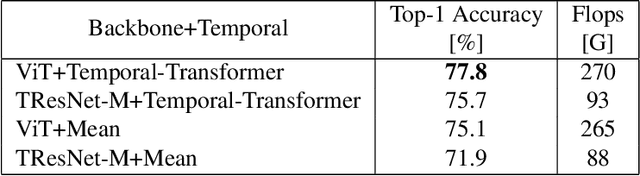
Leading methods in the domain of action recognition try to distill information from both the spatial and temporal dimensions of an input video. Methods that reach State of the Art (SotA) accuracy, usually make use of 3D convolution layers as a way to abstract the temporal information from video frames. The use of such convolutions requires sampling short clips from the input video, where each clip is a collection of closely sampled frames. Since each short clip covers a small fraction of an input video, multiple clips are sampled at inference in order to cover the whole temporal length of the video. This leads to increased computational load and is impractical for real-world applications. We address the computational bottleneck by significantly reducing the number of frames required for inference. Our approach relies on a temporal transformer that applies global attention over video frames, and thus better exploits the salient information in each frame. Therefore our approach is very input efficient, and can achieve SotA results (on Kinetics dataset) with a fraction of the data (frames per video), computation and latency. Specifically on Kinetics-400, we reach 78.8 top-1 accuracy with $\times 30$ less frames per video, and $\times 40$ faster inference than the current leading method. Code is available at: https://github.com/Alibaba-MIIL/STAM