 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDODO: Discrete OCR Diffusion Models
Feb 18, 2026Optical Character Recognition (OCR) is a fundamental task for digitizing information, serving as a critical bridge between visual data and textual understanding. While modern Vision-Language Models (VLM) have achieved high accuracy in this domain, they predominantly rely on autoregressive decoding, which becomes computationally expensive and slow for long documents as it requires a sequential forward pass for every generated token. We identify a key opportunity to overcome this bottleneck: unlike open-ended generation, OCR is a highly deterministic task where the visual input strictly dictates a unique output sequence, theoretically enabling efficient, parallel decoding via diffusion models. However, we show that existing masked diffusion models fail to harness this potential; those introduce structural instabilities that are benign in flexible tasks, like captioning, but catastrophic for the rigid, exact-match requirements of OCR. To bridge this gap, we introduce DODO, the first VLM to utilize block discrete diffusion and unlock its speedup potential for OCR. By decomposing generation into blocks, DODO mitigates the synchronization errors of global diffusion. Empirically, our method achieves near state-of-the-art accuracy while enabling up to 3x faster inference compared to autoregressive baselines.
FreeAugment: Data Augmentation Search Across All Degrees of Freedom
Sep 07, 2024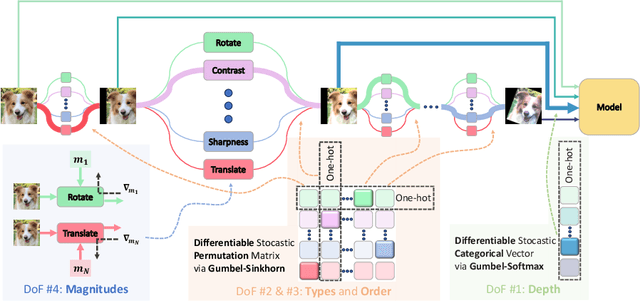
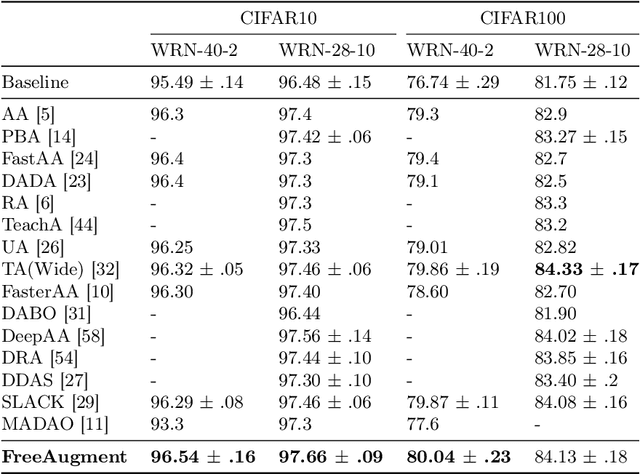
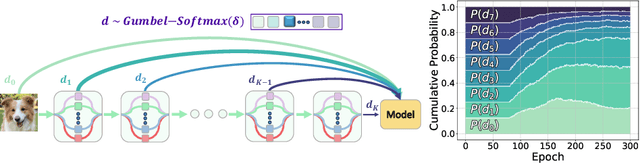

Data augmentation has become an integral part of deep learning, as it is known to improve the generalization capabilities of neural networks. Since the most effective set of image transformations differs between tasks and domains, automatic data augmentation search aims to alleviate the extreme burden of manually finding the optimal image transformations. However, current methods are not able to jointly optimize all degrees of freedom: (1) the number of transformations to be applied, their (2) types, (3) order, and (4) magnitudes. Many existing methods risk picking the same transformation more than once, limit the search to two transformations only, or search for the number of transformations exhaustively or iteratively in a myopic manner. Our approach, FreeAugment, is the first to achieve global optimization of all four degrees of freedom simultaneously, using a fully differentiable method. It efficiently learns the number of transformations and a probability distribution over their permutations, inherently refraining from redundant repetition while sampling. Our experiments demonstrate that this joint learning of all degrees of freedom significantly improves performance, achieving state-of-the-art results on various natural image benchmarks and beyond across other domains. Project page at https://tombekor.github.io/FreeAugment-web
VisFocus: Prompt-Guided Vision Encoders for OCR-Free Dense Document Understanding
Jul 17, 2024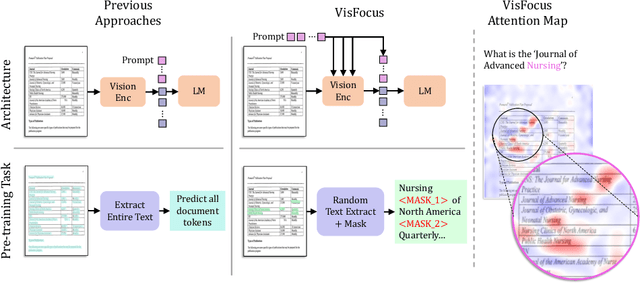
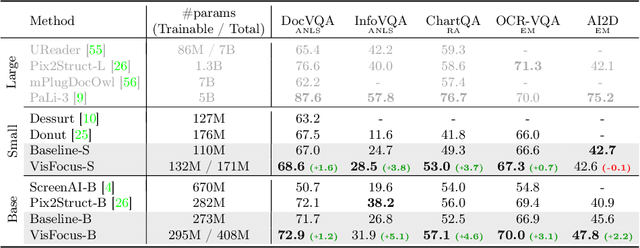
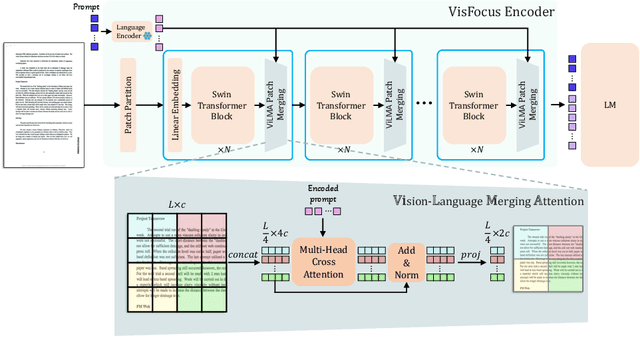

In recent years, notable advancements have been made in the domain of visual document understanding, with the prevailing architecture comprising a cascade of vision and language models. The text component can either be extracted explicitly with the use of external OCR models in OCR-based approaches, or alternatively, the vision model can be endowed with reading capabilities in OCR-free approaches. Typically, the queries to the model are input exclusively to the language component, necessitating the visual features to encompass the entire document. In this paper, we present VisFocus, an OCR-free method designed to better exploit the vision encoder's capacity by coupling it directly with the language prompt. To do so, we replace the down-sampling layers with layers that receive the input prompt and allow highlighting relevant parts of the document, while disregarding others. We pair the architecture enhancements with a novel pre-training task, using language masking on a snippet of the document text fed to the visual encoder in place of the prompt, to empower the model with focusing capabilities. Consequently, VisFocus learns to allocate its attention to text patches pertinent to the provided prompt. Our experiments demonstrate that this prompt-guided visual encoding approach significantly improves performance, achieving state-of-the-art results on various benchmarks.
Diverse Imagenet Models Transfer Better
Apr 19, 2022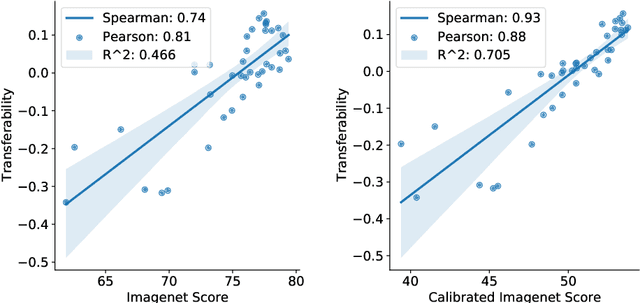
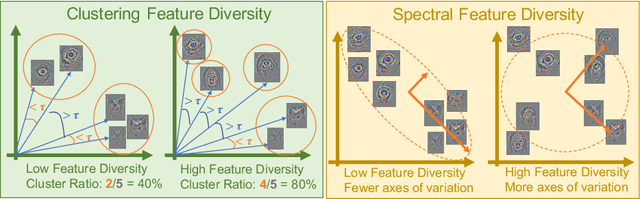
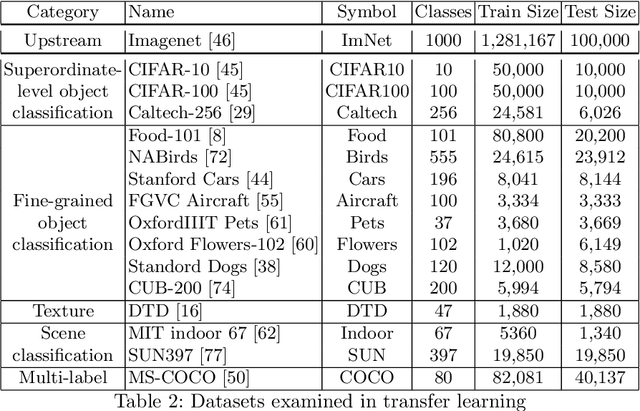
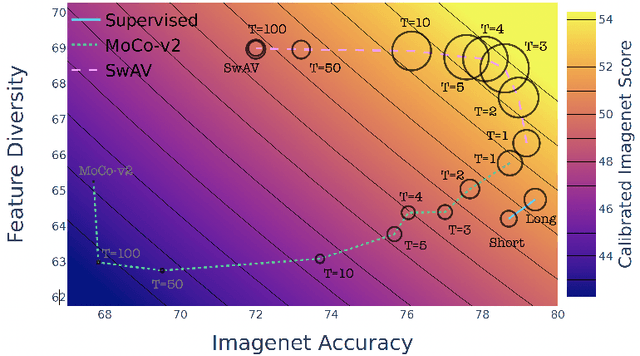
A commonly accepted hypothesis is that models with higher accuracy on Imagenet perform better on other downstream tasks, leading to much research dedicated to optimizing Imagenet accuracy. Recently this hypothesis has been challenged by evidence showing that self-supervised models transfer better than their supervised counterparts, despite their inferior Imagenet accuracy. This calls for identifying the additional factors, on top of Imagenet accuracy, that make models transferable. In this work we show that high diversity of the features learnt by the model promotes transferability jointly with Imagenet accuracy. Encouraged by the recent transferability results of self-supervised models, we propose a method that combines self-supervised and supervised pretraining to generate models with both high diversity and high accuracy, and as a result high transferability. We demonstrate our results on several architectures and multiple downstream tasks, including both single-label and multi-label classification.
IQNAS: Interpretable Integer Quadratic Programming Neural Architecture Search
Oct 24, 2021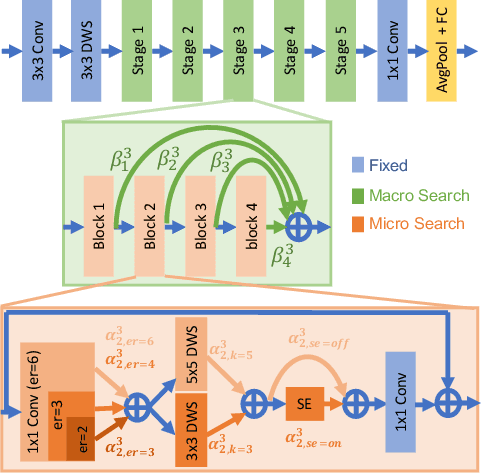
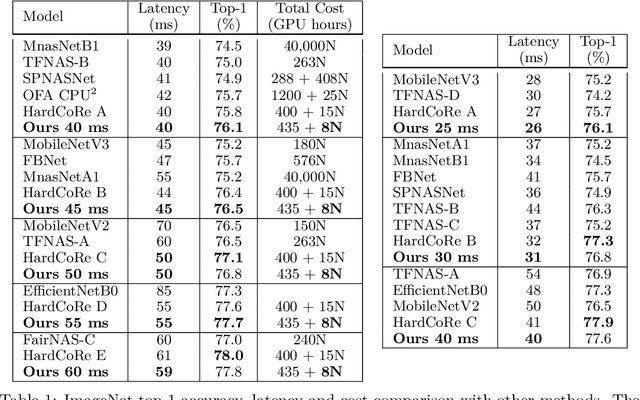
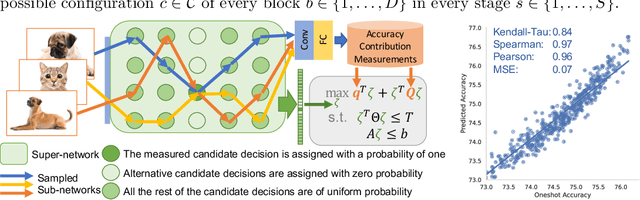
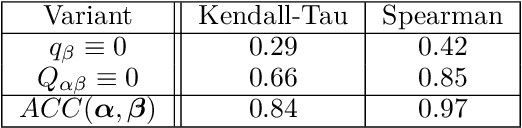
Realistic use of neural networks often requires adhering to multiple constraints on latency, energy and memory among others. A popular approach to find fitting networks is through constrained Neural Architecture Search (NAS). However, previous methods use complicated predictors for the accuracy of the network. Those predictors are hard to interpret and sensitive to many hyperparameters to be tuned, hence, the resulting accuracy of the generated models is often harmed. In this work we resolve this by introducing Interpretable Integer Quadratic programming Neural Architecture Search (IQNAS), that is based on an accurate and simple quadratic formulation of both the accuracy predictor and the expected resource requirement, together with a scalable search method with theoretical guarantees. The simplicity of our proposed predictor together with the intuitive way it is constructed bring interpretability through many insights about the contribution of different design choices. For example, we find that in the examined search space, adding depth and width is more effective at deeper stages of the network and at the beginning of each resolution stage. Our experiments show that IQNAS generates comparable to or better architectures than other state-of-the-art NAS methods within a reduced search cost for each additional generated network, while strictly satisfying the resource constraints.
HardCoRe-NAS: Hard Constrained diffeRentiable Neural Architecture Search
Feb 23, 2021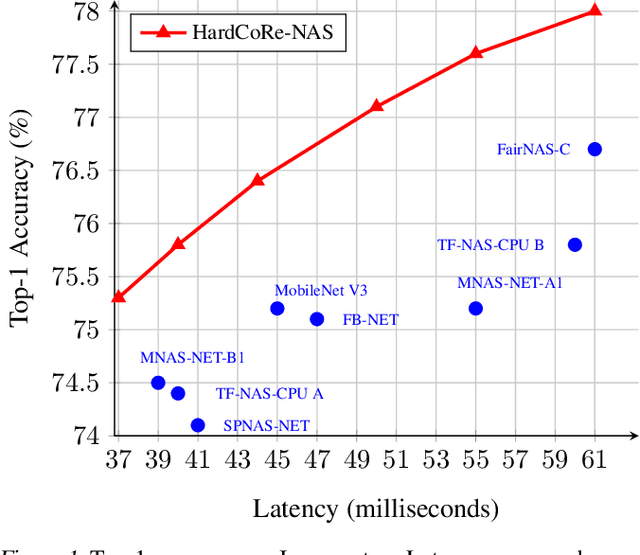
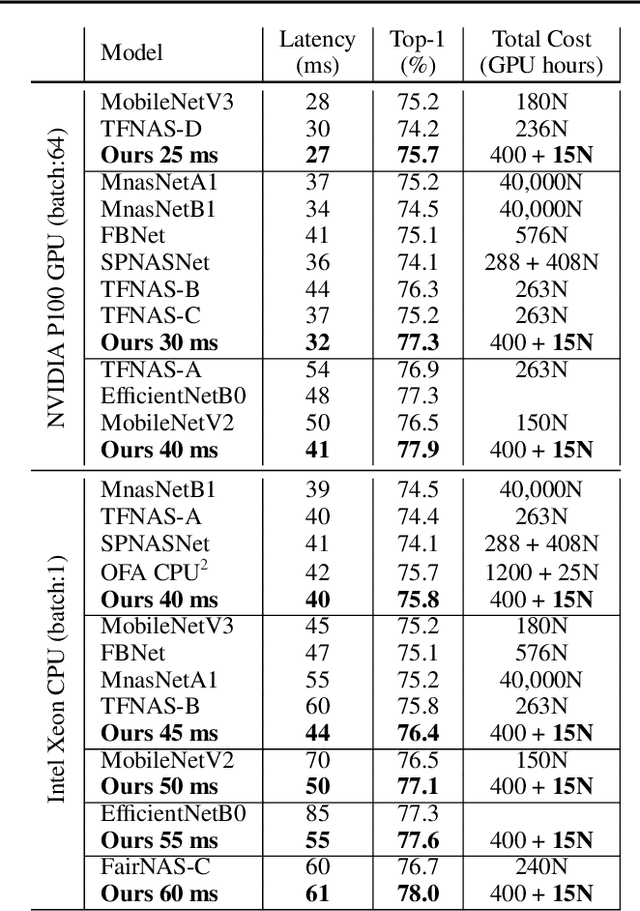
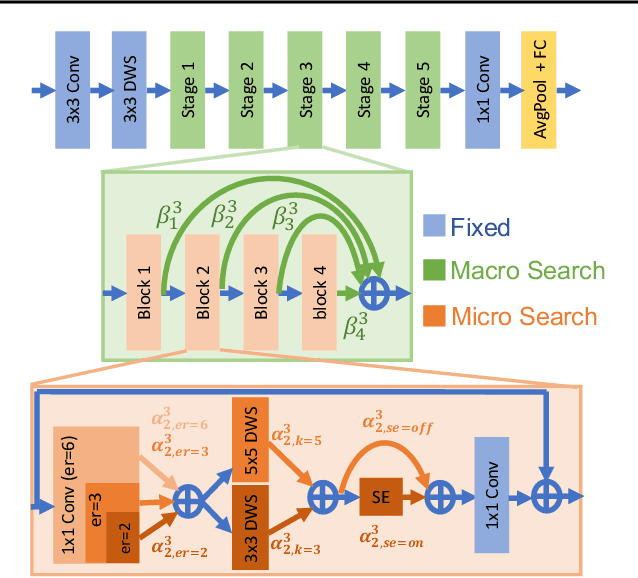
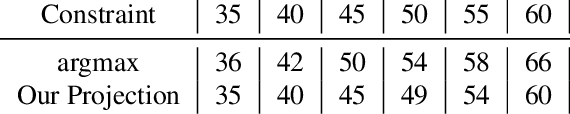
Realistic use of neural networks often requires adhering to multiple constraints on latency, energy and memory among others. A popular approach to find fitting networks is through constrained Neural Architecture Search (NAS), however, previous methods enforce the constraint only softly. Therefore, the resulting networks do not exactly adhere to the resource constraint and their accuracy is harmed. In this work we resolve this by introducing Hard Constrained diffeRentiable NAS (HardCoRe-NAS), that is based on an accurate formulation of the expected resource requirement and a scalable search method that satisfies the hard constraint throughout the search. Our experiments show that HardCoRe-NAS generates state-of-the-art architectures, surpassing other NAS methods, while strictly satisfying the hard resource constraints without any tuning required.
CobBO: Coordinate Backoff Bayesian Optimization
Feb 16, 2021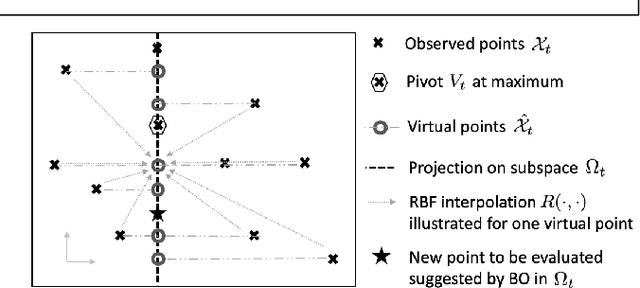

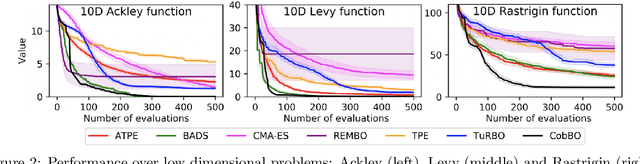

Bayesian optimization is a popular method for optimizing expensive black-box functions. The objective functions of hard real world problems are oftentimes characterized by a fluctuated landscape of many local optima. Bayesian optimization risks in over-exploiting such traps, remaining with insufficient query budget for exploring the global landscape. We introduce Coordinate Backoff Bayesian Optimization (CobBO) to alleviate those challenges. CobBO captures a smooth approximation of the global landscape by interpolating the values of queried points projected to randomly selected promising subspaces. Thus also a smaller query budget is required for the Gaussian process regressions applied over the lower dimensional subspaces. This approach can be viewed as a variant of coordinate ascent, tailored for Bayesian optimization, using a stopping rule for backing off from a certain subspace and switching to another coordinate subset. Extensive evaluations show that CobBO finds solutions comparable to or better than other state-of-the-art methods for dimensions ranging from tens to hundreds, while reducing the trial complexity.
XNAS: Neural Architecture Search with Expert Advice
Jun 19, 2019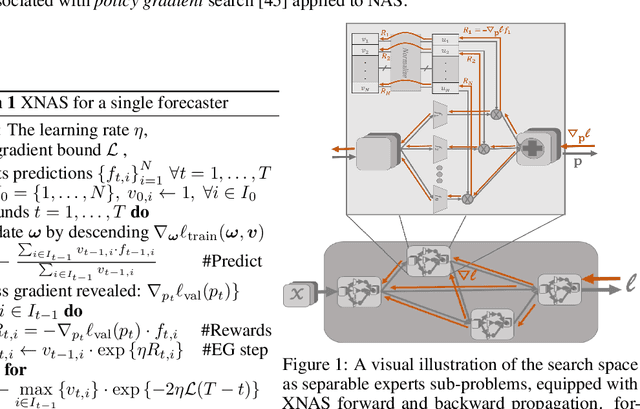
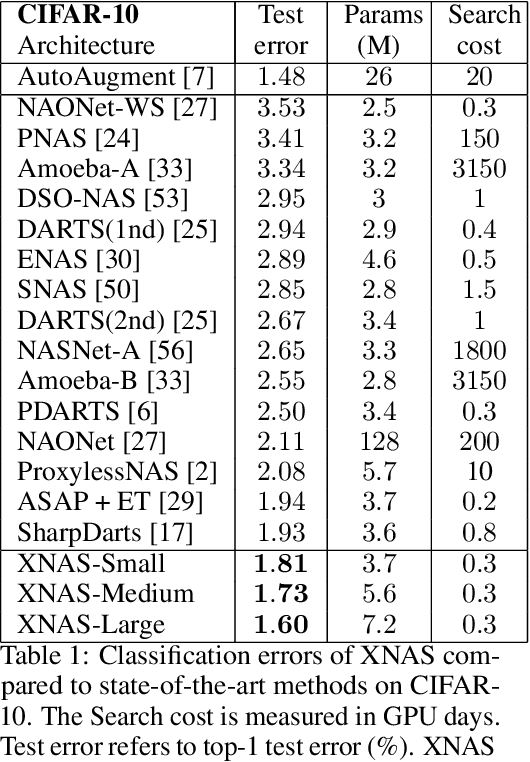
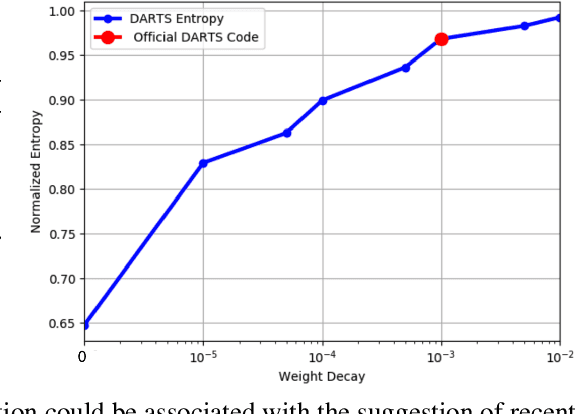
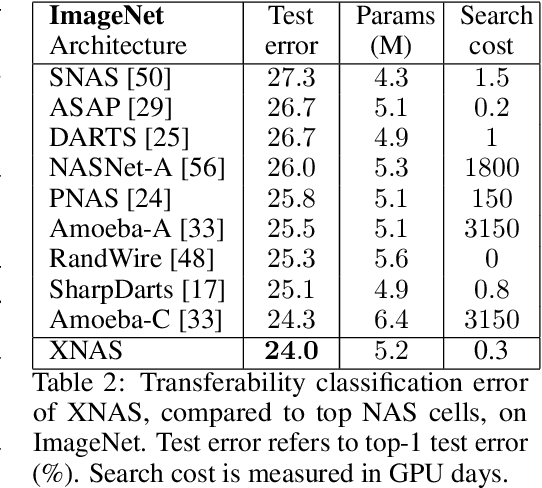
This paper introduces a novel optimization method for differential neural architecture search, based on the theory of prediction with expert advice. Its optimization criterion is well fitted for an architecture-selection, i.e., it minimizes the regret incurred by a sub-optimal selection of operations. Unlike previous search relaxations, that require hard pruning of architectures, our method is designed to dynamically wipe out inferior architectures and enhance superior ones. It achieves an optimal worst-case regret bound and suggests the use of multiple learning-rates, based on the amount of information carried by the backward gradients. Experiments show that our algorithm achieves a strong performance over several image classification datasets. Specifically, it obtains an error rate of 1.6% for CIFAR-10, 24% for ImageNet under mobile settings, and achieves state-of-the-art results on three additional datasets.
ASAP: Architecture Search, Anneal and Prune
Apr 08, 2019
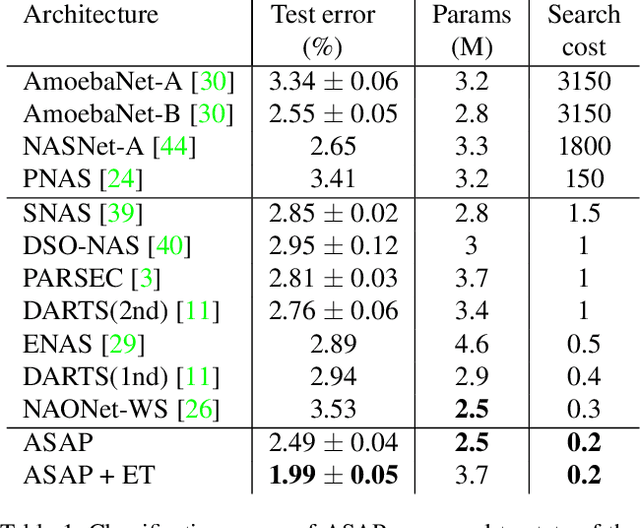
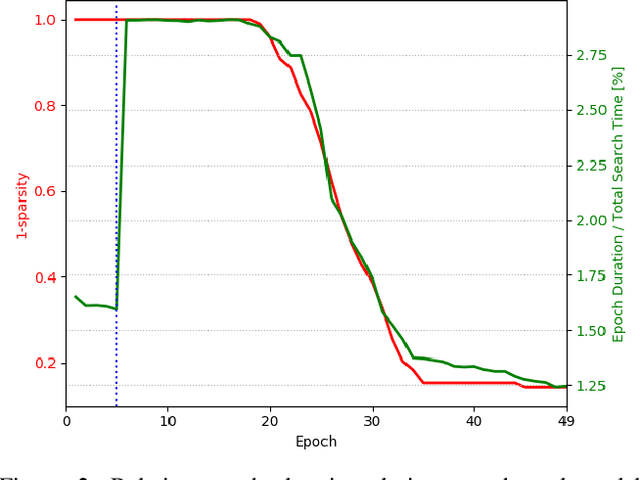
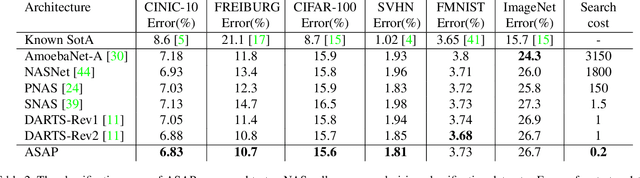
Automatic methods for Neural Architecture Search (NAS) have been shown to produce state-of-the-art network models, yet, their main drawback is the computational complexity of the search process. As some primal methods optimized over a discrete search space, thousands of days of GPU were required for convergence. A recent approach is based on constructing a differentiable search space that enables gradient-based optimization, thus reducing the search time to a few days. While successful, such methods still include some incontinuous steps, e.g., the pruning of many weak connections at once. In this paper, we propose a differentiable search space that allows the annealing of architecture weights, while gradually pruning inferior operations, thus the search converges to a single output network in a continuous manner. Experiments on several vision datasets demonstrate the effectiveness of our method with respect to the search cost, accuracy and the memory footprint of the achieved model.