 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYVE: Hybrid Views for LLM Context Engineering over Machine Data
Apr 07, 2026Machine data is central to observability and diagnosis in modern computing systems, appearing in logs, metrics, telemetry traces, and configuration snapshots. When provided to large language models (LLMs), this data typically arrives as a mixture of natural language and structured payloads such as JSON or Python/AST literals. Yet LLMs remain brittle on such inputs, particularly when they are long, deeply nested, and dominated by repetitive structure. We present HYVE (HYbrid ViEw), a framework for LLM context engineering for inputs containing large machine-data payloads, inspired by database management principles. HYVE surrounds model invocation with coordinated preprocessing and postprocessing, centered on a request-scoped datastore augmented with schema information. During preprocessing, HYVE detects repetitive structure in raw inputs, materializes it in the datastore, transforms it into hybrid columnar and row-oriented views, and selectively exposes only the most relevant representation to the LLM. During postprocessing, HYVE either returns the model output directly, queries the datastore to recover omitted information, or performs a bounded additional LLM call for SQL-augmented semantic synthesis. We evaluate HYVE on diverse real-world workloads spanning knowledge QA, chart generation, anomaly detection, and multi-step network troubleshooting. Across these benchmarks, HYVE reduces token usage by 50-90% while maintaining or improving output quality. On structured generation tasks, it improves chart-generation accuracy by up to 132% and reduces latency by up to 83%. Overall, HYVE offers a practical approximation to an effectively unbounded context window for prompts dominated by large machine-data payloads.
Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards
May 07, 2025
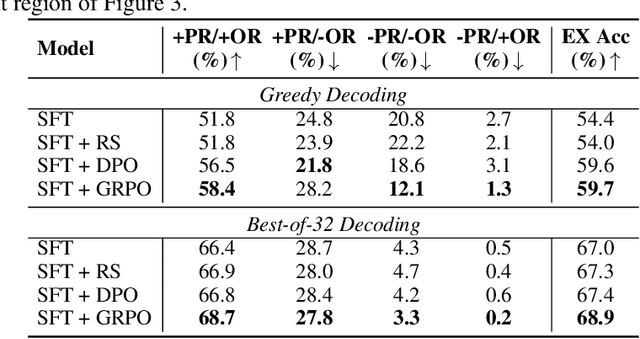
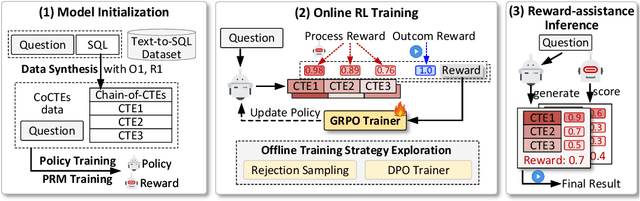
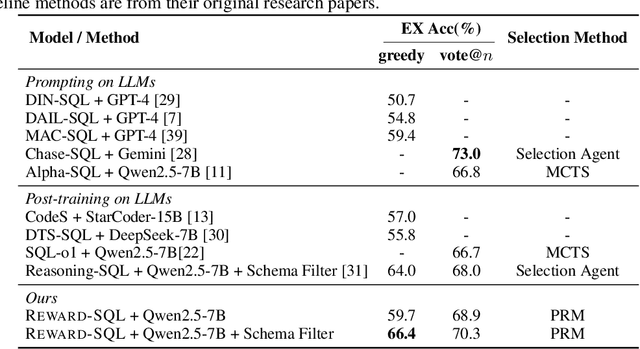
Recent advances in large language models (LLMs) have significantly improved performance on the Text-to-SQL task by leveraging their powerful reasoning capabilities. To enhance accuracy during the reasoning process, external Process Reward Models (PRMs) can be introduced during training and inference to provide fine-grained supervision. However, if misused, PRMs may distort the reasoning trajectory and lead to suboptimal or incorrect SQL generation.To address this challenge, we propose Reward-SQL, a framework that systematically explores how to incorporate PRMs into the Text-to-SQL reasoning process effectively. Our approach follows a "cold start, then PRM supervision" paradigm. Specifically, we first train the model to decompose SQL queries into structured stepwise reasoning chains using common table expressions (Chain-of-CTEs), establishing a strong and interpretable reasoning baseline. Then, we investigate four strategies for integrating PRMs, and find that combining PRM as an online training signal (GRPO) with PRM-guided inference (e.g., best-of-N sampling) yields the best results. Empirically, on the BIRD benchmark, Reward-SQL enables models supervised by a 7B PRM to achieve a 13.1% performance gain across various guidance strategies. Notably, our GRPO-aligned policy model based on Qwen2.5-Coder-7B-Instruct achieves 68.9% accuracy on the BIRD development set, outperforming all baseline methods under the same model size. These results demonstrate the effectiveness of Reward-SQL in leveraging reward-based supervision for Text-to-SQL reasoning. Our code is publicly available.
OneShotSTL: One-Shot Seasonal-Trend Decomposition For Online Time Series Anomaly Detection And Forecasting
Apr 04, 2023



Seasonal-trend decomposition is one of the most fundamental concepts in time series analysis that supports various downstream tasks, including time series anomaly detection and forecasting. However, existing decomposition methods rely on batch processing with a time complexity of O(W), where W is the number of data points within a time window. Therefore, they cannot always efficiently support real-time analysis that demands low processing delay. To address this challenge, we propose OneShotSTL, an efficient and accurate algorithm that can decompose time series online with an update time complexity of O(1). OneShotSTL is more than $1,000$ times faster than the batch methods, with accuracy comparable to the best counterparts. Extensive experiments on real-world benchmark datasets for downstream time series anomaly detection and forecasting tasks demonstrate that OneShotSTL is from 10 to over 1,000 times faster than the state-of-the-art methods, while still providing comparable or even better accuracy.
A Unified and Efficient Coordinating Framework for Autonomous DBMS Tuning
Mar 10, 2023Recently using machine learning (ML) based techniques to optimize modern database management systems has attracted intensive interest from both industry and academia. With an objective to tune a specific component of a DBMS (e.g., index selection, knobs tuning), the ML-based tuning agents have shown to be able to find better configurations than experienced database administrators. However, one critical yet challenging question remains unexplored -- how to make those ML-based tuning agents work collaboratively. Existing methods do not consider the dependencies among the multiple agents, and the model used by each agent only studies the effect of changing the configurations in a single component. To tune different components for DBMS, a coordinating mechanism is needed to make the multiple agents cognizant of each other. Also, we need to decide how to allocate the limited tuning budget among the agents to maximize the performance. Such a decision is difficult to make since the distribution of the reward for each agent is unknown and non-stationary. In this paper, we study the above question and present a unified coordinating framework to efficiently utilize existing ML-based agents. First, we propose a message propagation protocol that specifies the collaboration behaviors for agents and encapsulates the global tuning messages in each agent's model. Second, we combine Thompson Sampling, a well-studied reinforcement learning algorithm with a memory buffer so that our framework can allocate budget judiciously in a non-stationary environment. Our framework defines the interfaces adapted to a broad class of ML-based tuning agents, yet simple enough for integration with existing implementations and future extensions. We show that it can effectively utilize different ML-based agents and find better configurations with 1.4~14.1X speedups on the workload execution time compared with baselines.
Interactive Log Parsing via Light-weight User Feedbacks
Jan 28, 2023



Template mining is one of the foundational tasks to support log analysis, which supports the diagnosis and troubleshooting of large scale Web applications. This paper develops a human-in-the-loop template mining framework to support interactive log analysis, which is highly desirable in real-world diagnosis or troubleshooting of Web applications but yet previous template mining algorithms fails to support it. We formulate three types of light-weight user feedbacks and based on them we design three atomic human-in-the-loop template mining algorithms. We derive mild conditions under which the outputs of our proposed algorithms are provably correct. We also derive upper bounds on the computational complexity and query complexity of each algorithm. We demonstrate the versatility of our proposed algorithms by combining them to improve the template mining accuracy of five representative algorithms over sixteen widely used benchmark datasets.
LPC-AD: Fast and Accurate Multivariate Time Series Anomaly Detection via Latent Predictive Coding
May 05, 2022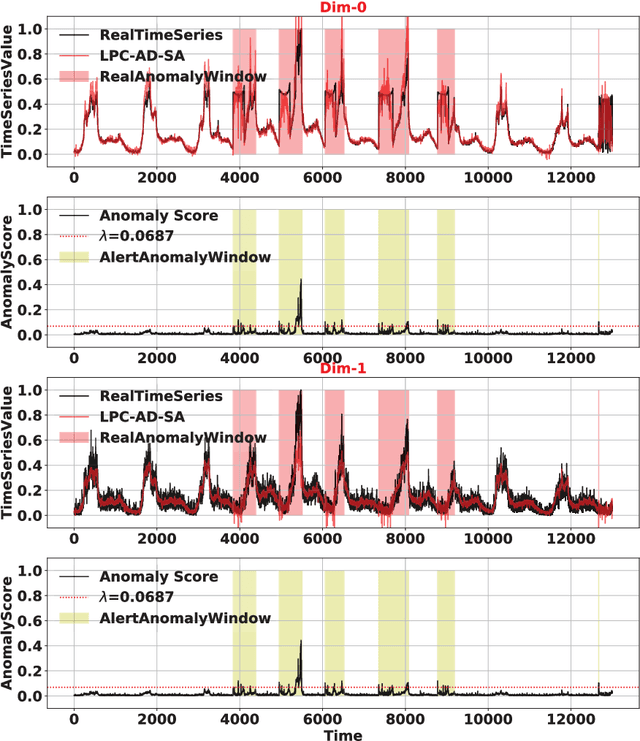
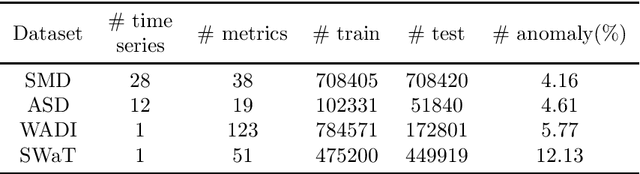
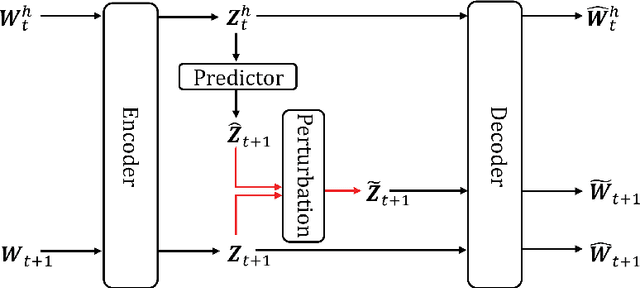
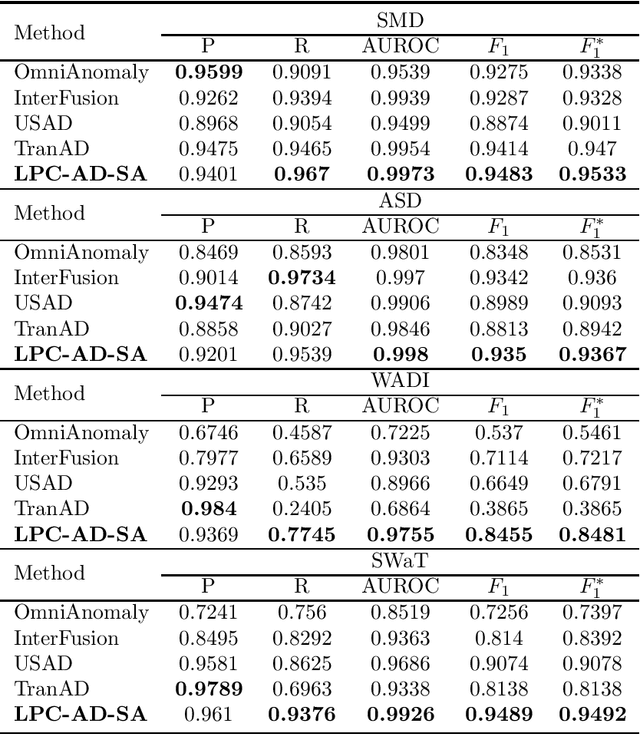
This paper proposes LPC-AD, a fast and accurate multivariate time series (MTS) anomaly detection method. LPC-AD is motivated by the ever-increasing needs for fast and accurate MTS anomaly detection methods to support fast troubleshooting in cloud computing, micro-service systems, etc. LPC-AD is fast in the sense that its reduces the training time by as high as 38.2% compared to the state-of-the-art (SOTA) deep learning methods that focus on training speed. LPC-AD is accurate in the sense that it improves the detection accuracy by as high as 18.9% compared to SOTA sophisticated deep learning methods that focus on enhancing detection accuracy. Methodologically, LPC-AD contributes a generic architecture LPC-Reconstruct for one to attain different trade-offs between training speed and detection accuracy. More specifically, LPC-Reconstruct is built on ideas from autoencoder for reducing redundancy in time series, latent predictive coding for capturing temporal dependence in MTS, and randomized perturbation for avoiding overfitting of anomalous dependence in the training data. We present simple instantiations of LPC-Reconstruct to attain fast training speed, where we propose a simple randomized perturbation method. The superior performance of LPC-AD over SOTA methods is validated by extensive experiments on four large real-world datasets. Experiment results also show the necessity and benefit of each component of the LPC-Reconstruct architecture and that LPC-AD is robust to hyper parameters.
CobBO: Coordinate Backoff Bayesian Optimization
Feb 16, 2021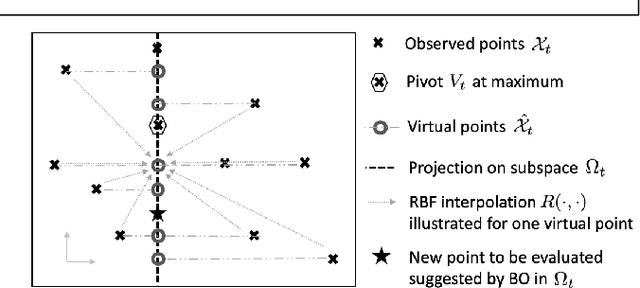

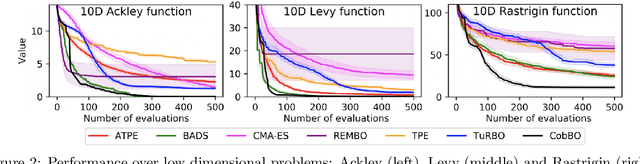

Bayesian optimization is a popular method for optimizing expensive black-box functions. The objective functions of hard real world problems are oftentimes characterized by a fluctuated landscape of many local optima. Bayesian optimization risks in over-exploiting such traps, remaining with insufficient query budget for exploring the global landscape. We introduce Coordinate Backoff Bayesian Optimization (CobBO) to alleviate those challenges. CobBO captures a smooth approximation of the global landscape by interpolating the values of queried points projected to randomly selected promising subspaces. Thus also a smaller query budget is required for the Gaussian process regressions applied over the lower dimensional subspaces. This approach can be viewed as a variant of coordinate ascent, tailored for Bayesian optimization, using a stopping rule for backing off from a certain subspace and switching to another coordinate subset. Extensive evaluations show that CobBO finds solutions comparable to or better than other state-of-the-art methods for dimensions ranging from tens to hundreds, while reducing the trial complexity.
Local Differential Privacy for Bayesian Optimization
Oct 13, 2020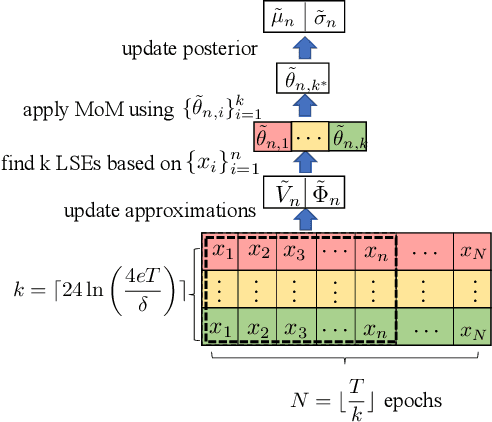
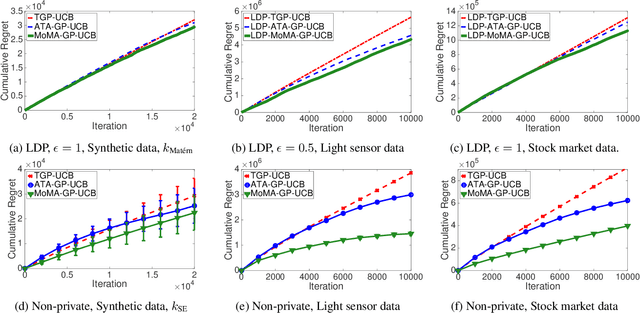
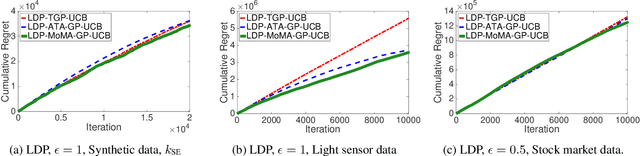
Motivated by the increasing concern about privacy in nowadays data-intensive online learning systems, we consider a black-box optimization in the nonparametric Gaussian process setting with local differential privacy (LDP) guarantee. Specifically, the rewards from each user are further corrupted to protect privacy and the learner only has access to the corrupted rewards to minimize the regret. We first derive the regret lower bounds for any LDP mechanism and any learning algorithm. Then, we present three almost optimal algorithms based on the GP-UCB framework and Laplace DP mechanism. In this process, we also propose a new Bayesian optimization (BO) method (called MoMA-GP-UCB) based on median-of-means techniques and kernel approximations, which complements previous BO algorithms for heavy-tailed payoffs with a reduced complexity. Further, empirical comparisons of different algorithms on both synthetic and real-world datasets highlight the superior performance of MoMA-GP-UCB in both private and non-private scenarios.
RobustTrend: A Huber Loss with a Combined First and Second Order Difference Regularization for Time Series Trend Filtering
Jun 27, 2019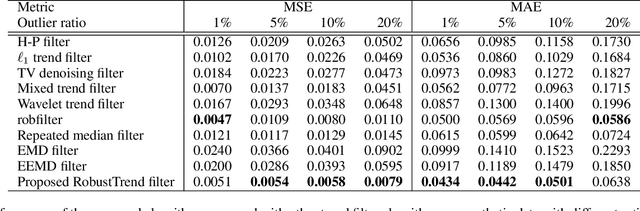
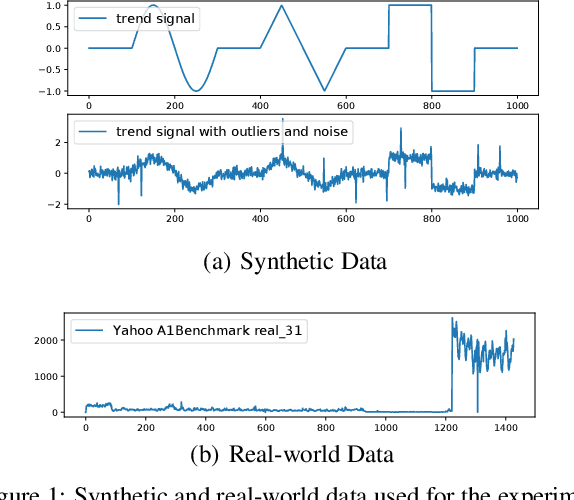
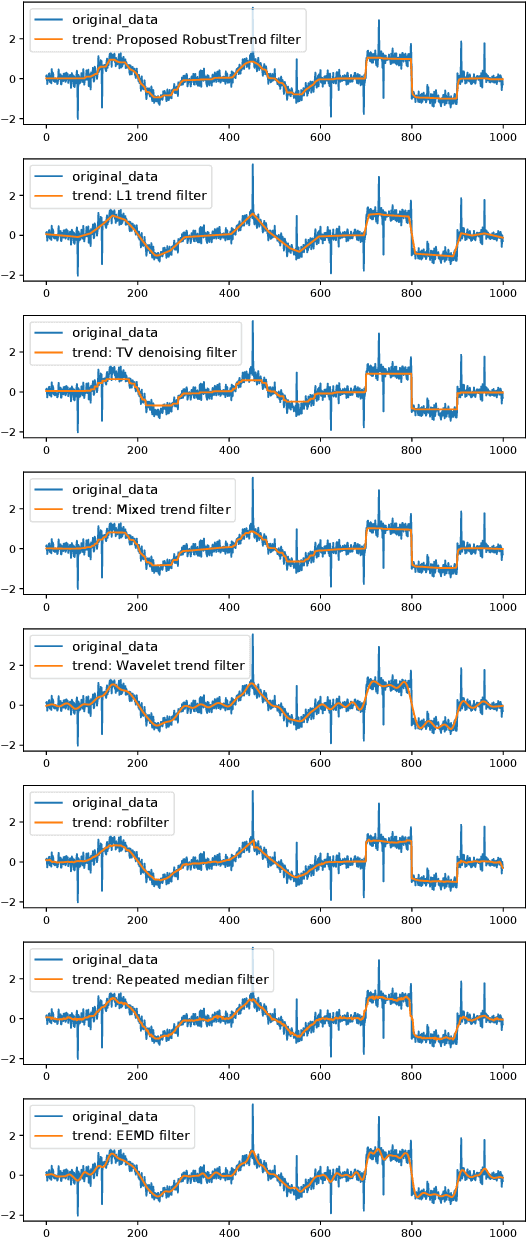
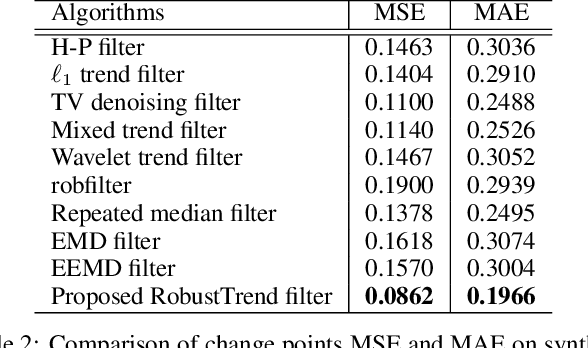
Extracting the underlying trend signal is a crucial step to facilitate time series analysis like forecasting and anomaly detection. Besides noise signal, time series can contain not only outliers but also abrupt trend changes in real-world scenarios. To deal with these challenges, we propose a robust trend filtering algorithm based on robust statistics and sparse learning. Specifically, we adopt the Huber loss to suppress outliers, and utilize a combination of the first order and second order difference on the trend component as regularization to capture both slow and abrupt trend changes. Furthermore, an efficient method is designed to solve the proposed robust trend filtering based on majorization minimization (MM) and alternative direction method of multipliers (ADMM). We compared our proposed robust trend filter with other nine state-of-the-art trend filtering algorithms on both synthetic and real-world datasets. The experiments demonstrate that our algorithm outperforms existing methods.
Learning Latent Features with Pairwise Penalties in Matrix Completion
Feb 16, 2018



Low-rank matrix completion (MC) has achieved great success in many real-world data applications. A latent feature model formulation is usually employed and, to improve prediction performance, the similarities between latent variables can be exploited by pairwise learning, e.g., the graph regularized matrix factorization (GRMF) method. However, existing GRMF approaches often use a squared L2 norm to measure the pairwise difference, which may be overly influenced by dissimilar pairs and lead to inferior prediction. To fully empower pairwise learning for matrix completion, we propose a general optimization framework that allows a rich class of (non-)convex pairwise penalty functions. A new and efficient algorithm is further developed to uniformly solve the optimization problem, with a theoretical convergence guarantee. In an important situation where the latent variables form a small number of subgroups, its statistical guarantee is also fully characterized. In particular, we theoretically characterize the complexity-regularized maximum likelihood estimator, as a special case of our framework. It has a better error bound when compared to the standard trace-norm regularized matrix completion. We conduct extensive experiments on both synthetic and real datasets to demonstrate the superior performance of this general framework.