 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards
May 07, 2025
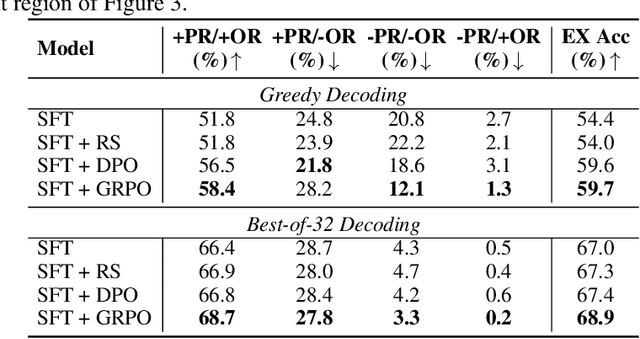
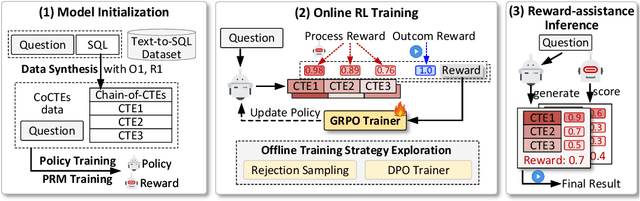
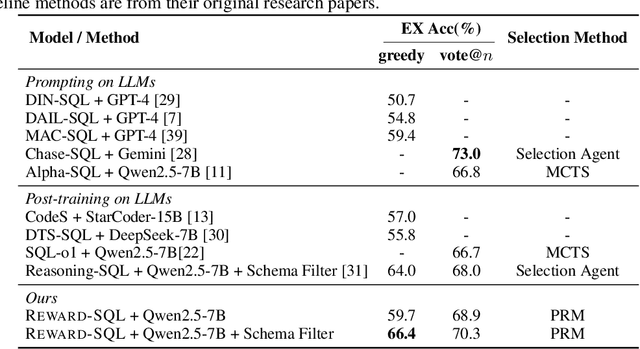
Recent advances in large language models (LLMs) have significantly improved performance on the Text-to-SQL task by leveraging their powerful reasoning capabilities. To enhance accuracy during the reasoning process, external Process Reward Models (PRMs) can be introduced during training and inference to provide fine-grained supervision. However, if misused, PRMs may distort the reasoning trajectory and lead to suboptimal or incorrect SQL generation.To address this challenge, we propose Reward-SQL, a framework that systematically explores how to incorporate PRMs into the Text-to-SQL reasoning process effectively. Our approach follows a "cold start, then PRM supervision" paradigm. Specifically, we first train the model to decompose SQL queries into structured stepwise reasoning chains using common table expressions (Chain-of-CTEs), establishing a strong and interpretable reasoning baseline. Then, we investigate four strategies for integrating PRMs, and find that combining PRM as an online training signal (GRPO) with PRM-guided inference (e.g., best-of-N sampling) yields the best results. Empirically, on the BIRD benchmark, Reward-SQL enables models supervised by a 7B PRM to achieve a 13.1% performance gain across various guidance strategies. Notably, our GRPO-aligned policy model based on Qwen2.5-Coder-7B-Instruct achieves 68.9% accuracy on the BIRD development set, outperforming all baseline methods under the same model size. These results demonstrate the effectiveness of Reward-SQL in leveraging reward-based supervision for Text-to-SQL reasoning. Our code is publicly available.
AutoPrep: Natural Language Question-Aware Data Preparation with a Multi-Agent Framework
Dec 10, 2024Answering natural language (NL) questions about tables, which is referred to as Tabular Question Answering (TQA), is important because it enables users to extract meaningful insights quickly and efficiently from structured data, bridging the gap between human language and machine-readable formats. Many of these tables originate from web sources or real-world scenarios, necessitating careful data preparation (or data prep for short) to ensure accurate answers. However, unlike traditional data prep, question-aware data prep introduces new requirements, which include tasks such as column augmentation and filtering for given questions, and question-aware value normalization or conversion. Because each of the above tasks is unique, a single model (or agent) may not perform effectively across all scenarios. In this paper, we propose AUTOPREP, a large language model (LLM)-based multi-agent framework that leverages the strengths of multiple agents, each specialized in a certain type of data prep, ensuring more accurate and contextually relevant responses. Given an NL question over a table, AUTOPREP performs data prep through three key components. Planner: Determines a logical plan, outlining a sequence of high-level operations. Programmer: Translates this logical plan into a physical plan by generating the corresponding low-level code. Executor: Iteratively executes and debugs the generated code to ensure correct outcomes. To support this multi-agent framework, we design a novel chain-of-thought reasoning mechanism for high-level operation suggestion, and a tool-augmented method for low-level code generation. Extensive experiments on real-world TQA datasets demonstrate that AUTOPREP can significantly improve the SOTA TQA solutions through question-aware data prep.
Cost-Effective In-Context Learning for Entity Resolution: A Design Space Exploration
Dec 07, 2023Entity resolution (ER) is an important data integration task with a wide spectrum of applications. The state-of-the-art solutions on ER rely on pre-trained language models (PLMs), which require fine-tuning on a lot of labeled matching/non-matching entity pairs. Recently, large languages models (LLMs), such as GPT-4, have shown the ability to perform many tasks without tuning model parameters, which is known as in-context learning (ICL) that facilitates effective learning from a few labeled input context demonstrations. However, existing ICL approaches to ER typically necessitate providing a task description and a set of demonstrations for each entity pair and thus have limitations on the monetary cost of interfacing LLMs. To address the problem, in this paper, we provide a comprehensive study to investigate how to develop a cost-effective batch prompting approach to ER. We introduce a framework BATCHER consisting of demonstration selection and question batching and explore different design choices that support batch prompting for ER. We also devise a covering-based demonstration selection strategy that achieves an effective balance between matching accuracy and monetary cost. We conduct a thorough evaluation to explore the design space and evaluate our proposed strategies. Through extensive experiments, we find that batch prompting is very cost-effective for ER, compared with not only PLM-based methods fine-tuned with extensive labeled data but also LLM-based methods with manually designed prompting. We also provide guidance for selecting appropriate design choices for batch prompting.