 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Label Cleaning for Reliable Detection of Electron Dense Deposits in Transmission Electron Microscopy Images
Feb 05, 2026Automated detection of electron dense deposits (EDD) in glomerular disease is hindered by the scarcity of high-quality labeled data. While crowdsourcing reduces annotation cost, it introduces label noise. We propose an active label cleaning method to efficiently denoise crowdsourced datasets. Our approach uses active learning to select the most valuable noisy samples for expert re-annotation, building high-accuracy cleaning models. A Label Selection Module leverages discrepancies between crowdsourced labels and model predictions for both sample selection and instance-level noise grading. Experiments show our method achieves 67.18% AP\textsubscript{50} on a private dataset, an 18.83% improvement over training on noisy labels. This performance reaches 95.79% of that with full expert annotation while reducing annotation cost by 73.30%. The method provides a practical, cost-effective solution for developing reliable medical AI with limited expert resources.
Fusion of Multiscale Features Via Centralized Sparse-attention Network for EEG Decoding
Dec 23, 2025Electroencephalography (EEG) signal decoding is a key technology that translates brain activity into executable commands, laying the foundation for direct brain-machine interfacing and intelligent interaction. To address the inherent spatiotemporal heterogeneity of EEG signals, this paper proposes a multi-branch parallel architecture, where each temporal scale is equipped with an independent spatial feature extraction module. To further enhance multi-branch feature fusion, we propose a Fusion of Multiscale Features via Centralized Sparse-attention Network (EEG-CSANet), a centralized sparse-attention network. It employs a main-auxiliary branch architecture, where the main branch models core spatiotemporal patterns via multiscale self-attention, and the auxiliary branch facilitates efficient local interactions through sparse cross-attention. Experimental results show that EEG-CSANet achieves state-of-the-art (SOTA) performance across five public datasets (BCIC-IV-2A, BCIC-IV-2B, HGD, SEED, and SEED-VIG), with accuracies of 88.54%, 91.09%, 99.43%, 96.03%, and 90.56%, respectively. Such performance demonstrates its strong adaptability and robustness across various EEG decoding tasks. Moreover, extensive ablation studies are conducted to enhance the interpretability of EEG-CSANet. In the future, we hope that EEG-CSANet could serve as a promising baseline model in the field of EEG signal decoding. The source code is publicly available at: https://github.com/Xiangrui-Cai/EEG-CSANet
Cross-modal ultra-scale learning with tri-modalities of renal biopsy images for glomerular multi-disease auxiliary diagnosis
Dec 17, 2025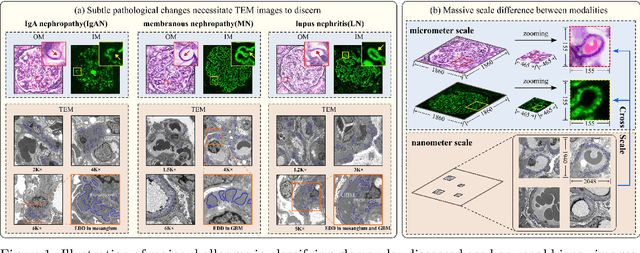
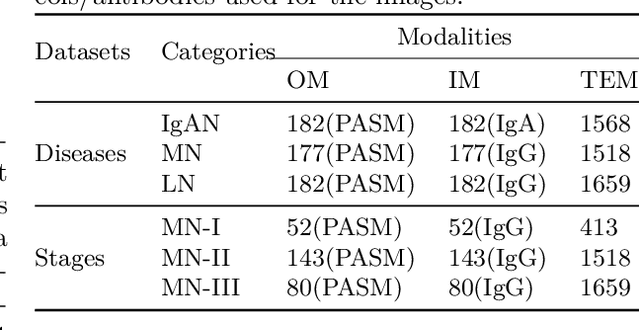
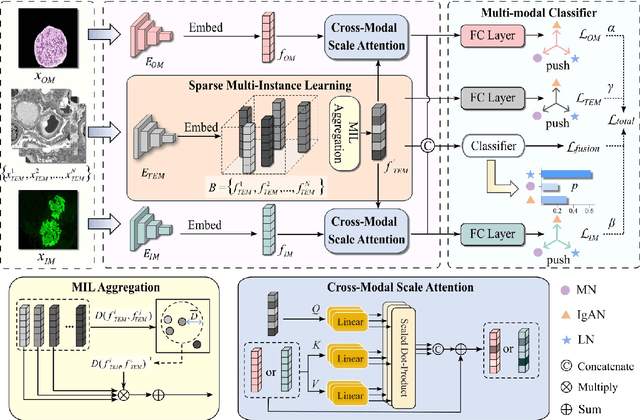
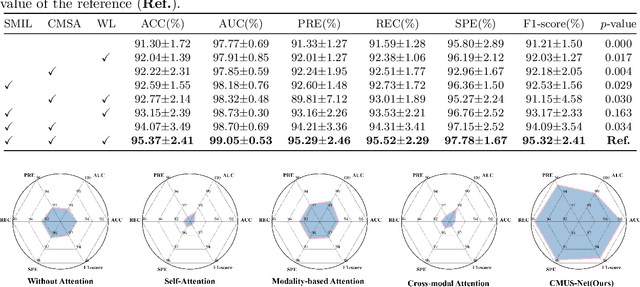
Constructing a multi-modal automatic classification model based on three types of renal biopsy images can assist pathologists in glomerular multi-disease identification. However, the substantial scale difference between transmission electron microscopy (TEM) image features at the nanoscale and optical microscopy (OM) or immunofluorescence microscopy (IM) images at the microscale poses a challenge for existing multi-modal and multi-scale models in achieving effective feature fusion and improving classification accuracy. To address this issue, we propose a cross-modal ultra-scale learning network (CMUS-Net) for the auxiliary diagnosis of multiple glomerular diseases. CMUS-Net utilizes multiple ultrastructural information to bridge the scale difference between nanometer and micrometer images. Specifically, we introduce a sparse multi-instance learning module to aggregate features from TEM images. Furthermore, we design a cross-modal scale attention module to facilitate feature interaction, enhancing pathological semantic information. Finally, multiple loss functions are combined, allowing the model to weigh the importance among different modalities and achieve precise classification of glomerular diseases. Our method follows the conventional process of renal biopsy pathology diagnosis and, for the first time, performs automatic classification of multiple glomerular diseases including IgA nephropathy (IgAN), membranous nephropathy (MN), and lupus nephritis (LN) based on images from three modalities and two scales. On an in-house dataset, CMUS-Net achieves an ACC of 95.37+/-2.41%, an AUC of 99.05+/-0.53%, and an F1-score of 95.32+/-2.41%. Extensive experiments demonstrate that CMUS-Net outperforms other well-known multi-modal or multi-scale methods and show its generalization capability in staging MN. Code is available at https://github.com/SMU-GL-Group/MultiModal_lkx/tree/main.
Not All Instances Are Equally Valuable: Towards Influence-Weighted Dataset Distillation
Oct 31, 2025Dataset distillation condenses large datasets into synthetic subsets, achieving performance comparable to training on the full dataset while substantially reducing storage and computation costs. Most existing dataset distillation methods assume that all real instances contribute equally to the process. In practice, real-world datasets contain both informative and redundant or even harmful instances, and directly distilling the full dataset without considering data quality can degrade model performance. In this work, we present Influence-Weighted Distillation IWD, a principled framework that leverages influence functions to explicitly account for data quality in the distillation process. IWD assigns adaptive weights to each instance based on its estimated impact on the distillation objective, prioritizing beneficial data while downweighting less useful or harmful ones. Owing to its modular design, IWD can be seamlessly integrated into diverse dataset distillation frameworks. Our empirical results suggest that integrating IWD tends to improve the quality of distilled datasets and enhance model performance, with accuracy gains of up to 7.8%.
Glo-DMU: A Deep Morphometry Framework of Ultrastructural Characterization in Glomerular Electron Microscopic Images
Aug 14, 2025Complex and diverse ultrastructural features can indicate the type, progression, and prognosis of kidney diseases. Recently, computational pathology combined with deep learning methods has shown tremendous potential in advancing automatic morphological analysis of glomerular ultrastructure. However, current research predominantly focuses on the recognition of individual ultrastructure, which makes it challenging to meet practical diagnostic needs. In this study, we propose the glomerular morphometry framework of ultrastructural characterization (Glo-DMU), which is grounded on three deep models: the ultrastructure segmentation model, the glomerular filtration barrier region classification model, and the electron-dense deposits detection model. Following the conventional protocol of renal biopsy diagnosis, this framework simultaneously quantifies the three most widely used ultrastructural features: the thickness of glomerular basement membrane, the degree of foot process effacement, and the location of electron-dense deposits. We evaluated the 115 patients with 9 renal pathological types in real-world diagnostic scenarios, demonstrating good consistency between automatic quantification results and morphological descriptions in the pathological reports. Glo-DMU possesses the characteristics of full automation, high precision, and high throughput, quantifying multiple ultrastructural features simultaneously, and providing an efficient tool for assisting renal pathologists.
KramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Data Lakes
Jun 06, 2025Constructing real-world data-to-insight pipelines often involves data extraction from data lakes, data integration across heterogeneous data sources, and diverse operations from data cleaning to analysis. The design and implementation of data science pipelines require domain knowledge, technical expertise, and even project-specific insights. AI systems have shown remarkable reasoning, coding, and understanding capabilities. However, it remains unclear to what extent these capabilities translate into successful design and execution of such complex pipelines. We introduce KRAMABENCH: a benchmark composed of 104 manually-curated real-world data science pipelines spanning 1700 data files from 24 data sources in 6 different domains. We show that these pipelines test the end-to-end capabilities of AI systems on data processing, requiring data discovery, wrangling and cleaning, efficient processing, statistical reasoning, and orchestrating data processing steps given a high-level task. Our evaluation tests 5 general models and 3 code generation models using our reference framework, DS-GURU, which instructs the AI model to decompose a question into a sequence of subtasks, reason through each step, and synthesize Python code that implements the proposed design. Our results on KRAMABENCH show that, although the models are sufficiently capable of solving well-specified data science code generation tasks, when extensive data processing and domain knowledge are required to construct real-world data science pipelines, existing out-of-box models fall short. Progress on KramaBench represents crucial steps towards developing autonomous data science agents for real-world applications. Our code, reference framework, and data are available at https://github.com/mitdbg/KramaBench.
Not All Documents Are What You Need for Extracting Instruction Tuning Data
May 18, 2025Instruction tuning improves the performance of large language models (LLMs), but it heavily relies on high-quality training data. Recently, LLMs have been used to synthesize instruction data using seed question-answer (QA) pairs. However, these synthesized instructions often lack diversity and tend to be similar to the input seeds, limiting their applicability in real-world scenarios. To address this, we propose extracting instruction tuning data from web corpora that contain rich and diverse knowledge. A naive solution is to retrieve domain-specific documents and extract all QA pairs from them, but this faces two key challenges: (1) extracting all QA pairs using LLMs is prohibitively expensive, and (2) many extracted QA pairs may be irrelevant to the downstream tasks, potentially degrading model performance. To tackle these issues, we introduce EQUAL, an effective and scalable data extraction framework that iteratively alternates between document selection and high-quality QA pair extraction to enhance instruction tuning. EQUAL first clusters the document corpus based on embeddings derived from contrastive learning, then uses a multi-armed bandit strategy to efficiently identify clusters that are likely to contain valuable QA pairs. This iterative approach significantly reduces computational cost while boosting model performance. Experiments on AutoMathText and StackOverflow across four downstream tasks show that EQUAL reduces computational costs by 5-10x and improves accuracy by 2.5 percent on LLaMA-3.1-8B and Mistral-7B
Quantum Conflict Measurement in Decision Making for Out-of-Distribution Detection
May 10, 2025Quantum Dempster-Shafer Theory (QDST) uses quantum interference effects to derive a quantum mass function (QMF) as a fuzzy metric type from information obtained from various data sources. In addition, QDST uses quantum parallel computing to speed up computation. Nevertheless, the effective management of conflicts between multiple QMFs in QDST is a challenging question. This work aims to address this problem by proposing a Quantum Conflict Indicator (QCI) that measures the conflict between two QMFs in decision-making. Then, the properties of the QCI are carefully investigated. The obtained results validate its compliance with desirable conflict measurement properties such as non-negativity, symmetry, boundedness, extreme consistency and insensitivity to refinement. We then apply the proposed QCI in conflict fusion methods and compare its performance with several commonly used fusion approaches. This comparison demonstrates the superiority of the QCI-based conflict fusion method. Moreover, the Class Description Domain Space (C-DDS) and its optimized version, C-DDS+ by utilizing the QCI-based fusion method, are proposed to address the Out-of-Distribution (OOD) detection task. The experimental results show that the proposed approach gives better OOD performance with respect to several state-of-the-art baseline OOD detection methods. Specifically, it achieves an average increase in Area Under the Receiver Operating Characteristic Curve (AUC) of 1.2% and a corresponding average decrease in False Positive Rate at 95% True Negative Rate (FPR95) of 5.4% compared to the optimal baseline method.
MISE: Meta-knowledge Inheritance for Social Media-Based Stressor Estimation
May 03, 2025Stress haunts people in modern society, which may cause severe health issues if left unattended. With social media becoming an integral part of daily life, leveraging social media to detect stress has gained increasing attention. While the majority of the work focuses on classifying stress states and stress categories, this study introduce a new task aimed at estimating more specific stressors (like exam, writing paper, etc.) through users' posts on social media. Unfortunately, the diversity of stressors with many different classes but a few examples per class, combined with the consistent arising of new stressors over time, hinders the machine understanding of stressors. To this end, we cast the stressor estimation problem within a practical scenario few-shot learning setting, and propose a novel meta-learning based stressor estimation framework that is enhanced by a meta-knowledge inheritance mechanism. This model can not only learn generic stressor context through meta-learning, but also has a good generalization ability to estimate new stressors with little labeled data. A fundamental breakthrough in our approach lies in the inclusion of the meta-knowledge inheritance mechanism, which equips our model with the ability to prevent catastrophic forgetting when adapting to new stressors. The experimental results show that our model achieves state-of-the-art performance compared with the baselines. Additionally, we construct a social media-based stressor estimation dataset that can help train artificial intelligence models to facilitate human well-being. The dataset is now public at \href{https://www.kaggle.com/datasets/xinwangcs/stressor-cause-of-mental-health-problem-dataset}{\underline{Kaggle}} and \href{https://huggingface.co/datasets/XinWangcs/Stressor}{\underline{Hugging Face}}.
Handling Label Noise via Instance-Level Difficulty Modeling and Dynamic Optimization
May 01, 2025
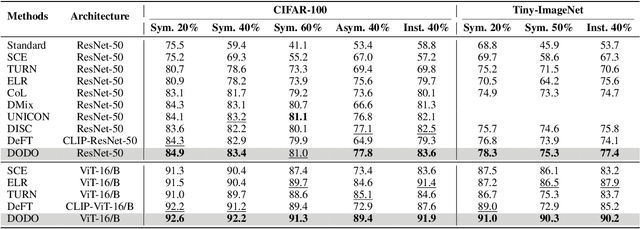


Recent studies indicate that deep neural networks degrade in generalization performance under noisy supervision. Existing methods focus on isolating clean subsets or correcting noisy labels, facing limitations such as high computational costs, heavy hyperparameter tuning process, and coarse-grained optimization. To address these challenges, we propose a novel two-stage noisy learning framework that enables instance-level optimization through a dynamically weighted loss function, avoiding hyperparameter tuning. To obtain stable and accurate information about noise modeling, we introduce a simple yet effective metric, termed wrong event, which dynamically models the cleanliness and difficulty of individual samples while maintaining computational costs. Our framework first collects wrong event information and builds a strong base model. Then we perform noise-robust training on the base model, using a probabilistic model to handle the wrong event information of samples. Experiments on five synthetic and real-world LNL benchmarks demonstrate our method surpasses state-of-the-art methods in performance, achieves a nearly 75% reduction in computational time and improves model scalability.