 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalist Game Players: An Investigation of Foundation Models in the Game Multiverse
May 11, 2026The real world unfolds along a single set of physics laws, yet human intelligence demonstrates a remarkable capacity to generalize experiences from this singular physical existence into a multiverse of games, each governed by entirely different rules, aesthetics, physics, and objectives. This omni-reality adaptability is a hallmark of general intelligence. As Artificial Intelligence progresses towards Artificial General Intelligence, the multiverse of games has evolved from mere entertainment into the ultimate ground for training and evaluating AGI. The pursuit of this generality has unfolded across four eras: from environment-specific symbolic and reinforcement learning agents, to current large foundation models acting as generalist players, and toward a future creator stage where agent both creates new game worlds and continually evolves within them. We trace the full lifecycle of a generalist game player along four interdependent pillars: Dataset, Model, Harness, and Benchmark. Every advance across these pillars can be read as an attempt to break one of five fundamental trade-offs that currently bound the whole system. Building on this end-to-end view, we chart a five-level roadmap, progressing from single-game mastery to the ultimate creator stage in which the agent simultaneously creates and evolves within theoretical game multiverse. Taken together, our work offers a unified lens onto a rapidly shifting field,and a principled path toward the omnipotent generalist agent capable of seamlessly mastering any challenge within the multiverse of games, thereby paving the way for AGI.
Handling Label Noise via Instance-Level Difficulty Modeling and Dynamic Optimization
May 01, 2025
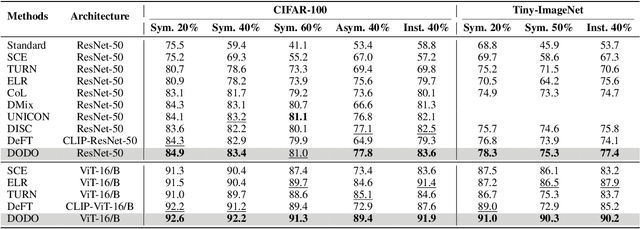


Recent studies indicate that deep neural networks degrade in generalization performance under noisy supervision. Existing methods focus on isolating clean subsets or correcting noisy labels, facing limitations such as high computational costs, heavy hyperparameter tuning process, and coarse-grained optimization. To address these challenges, we propose a novel two-stage noisy learning framework that enables instance-level optimization through a dynamically weighted loss function, avoiding hyperparameter tuning. To obtain stable and accurate information about noise modeling, we introduce a simple yet effective metric, termed wrong event, which dynamically models the cleanliness and difficulty of individual samples while maintaining computational costs. Our framework first collects wrong event information and builds a strong base model. Then we perform noise-robust training on the base model, using a probabilistic model to handle the wrong event information of samples. Experiments on five synthetic and real-world LNL benchmarks demonstrate our method surpasses state-of-the-art methods in performance, achieves a nearly 75% reduction in computational time and improves model scalability.
Harnessing Diversity for Important Data Selection in Pretraining Large Language Models
Sep 25, 2024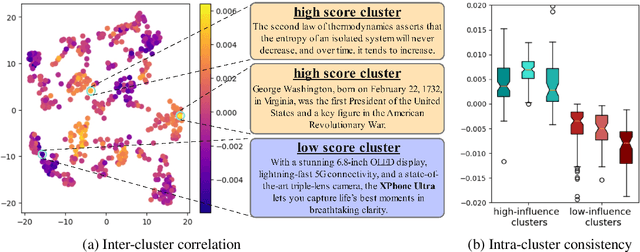
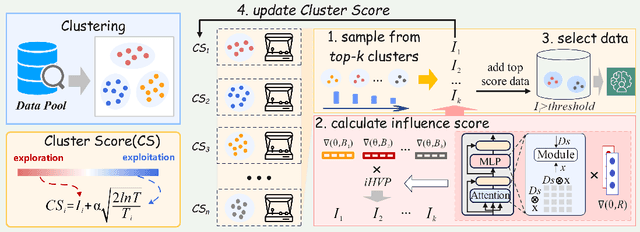
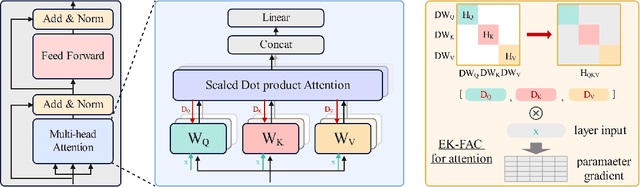
Data selection is of great significance in pre-training large language models, given the variation in quality within the large-scale available training corpora. To achieve this, researchers are currently investigating the use of data influence to measure the importance of data instances, $i.e.,$ a high influence score indicates that incorporating this instance to the training set is likely to enhance the model performance. Consequently, they select the top-$k$ instances with the highest scores. However, this approach has several limitations. (1) Computing the influence of all available data is time-consuming. (2) The selected data instances are not diverse enough, which may hinder the pre-trained model's ability to generalize effectively to various downstream tasks. In this paper, we introduce \texttt{Quad}, a data selection approach that considers both quality and diversity by using data influence to achieve state-of-the-art pre-training results. In particular, noting that attention layers capture extensive semantic details, we have adapted the accelerated $iHVP$ computation methods for attention layers, enhancing our ability to evaluate the influence of data, $i.e.,$ its quality. For the diversity, \texttt{Quad} clusters the dataset into similar data instances within each cluster and diverse instances across different clusters. For each cluster, if we opt to select data from it, we take some samples to evaluate the influence to prevent processing all instances. To determine which clusters to select, we utilize the classic Multi-Armed Bandit method, treating each cluster as an arm. This approach favors clusters with highly influential instances (ensuring high quality) or clusters that have been selected less frequently (ensuring diversity), thereby well balancing between quality and diversity.
Communication-Efficient Hybrid Federated Learning for E-health with Horizontal and Vertical Data Partitioning
Apr 15, 2024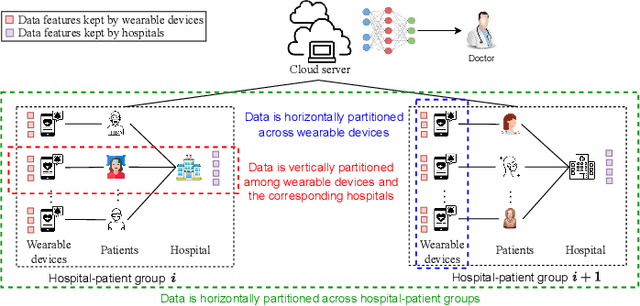
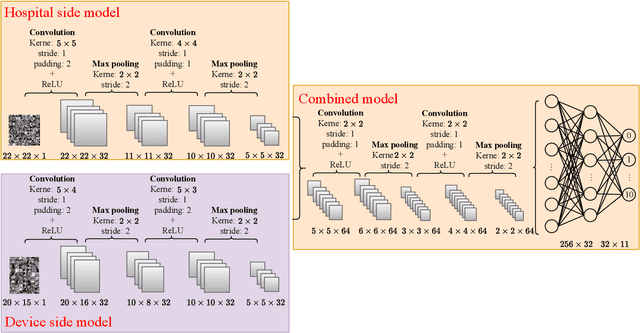

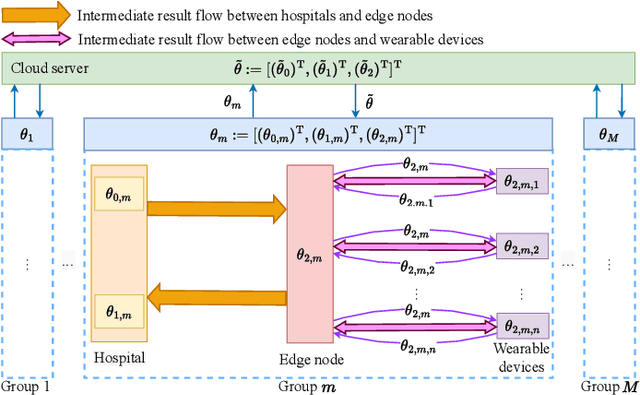
E-health allows smart devices and medical institutions to collaboratively collect patients' data, which is trained by Artificial Intelligence (AI) technologies to help doctors make diagnosis. By allowing multiple devices to train models collaboratively, federated learning is a promising solution to address the communication and privacy issues in e-health. However, applying federated learning in e-health faces many challenges. First, medical data is both horizontally and vertically partitioned. Since single Horizontal Federated Learning (HFL) or Vertical Federated Learning (VFL) techniques cannot deal with both types of data partitioning, directly applying them may consume excessive communication cost due to transmitting a part of raw data when requiring high modeling accuracy. Second, a naive combination of HFL and VFL has limitations including low training efficiency, unsound convergence analysis, and lack of parameter tuning strategies. In this paper, we provide a thorough study on an effective integration of HFL and VFL, to achieve communication efficiency and overcome the above limitations when data is both horizontally and vertically partitioned. Specifically, we propose a hybrid federated learning framework with one intermediate result exchange and two aggregation phases. Based on this framework, we develop a Hybrid Stochastic Gradient Descent (HSGD) algorithm to train models. Then, we theoretically analyze the convergence upper bound of the proposed algorithm. Using the convergence results, we design adaptive strategies to adjust the training parameters and shrink the size of transmitted data. Experimental results validate that the proposed HSGD algorithm can achieve the desired accuracy while reducing communication cost, and they also verify the effectiveness of the adaptive strategies.
Planning-inspired Hierarchical Trajectory Prediction for Autonomous Driving
Apr 22, 2023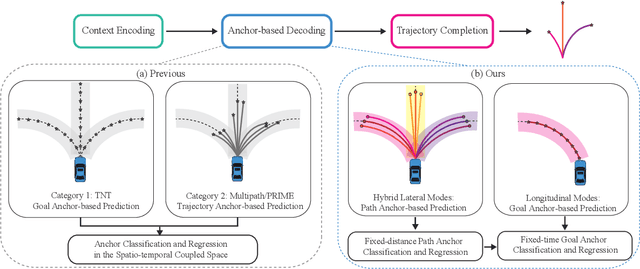
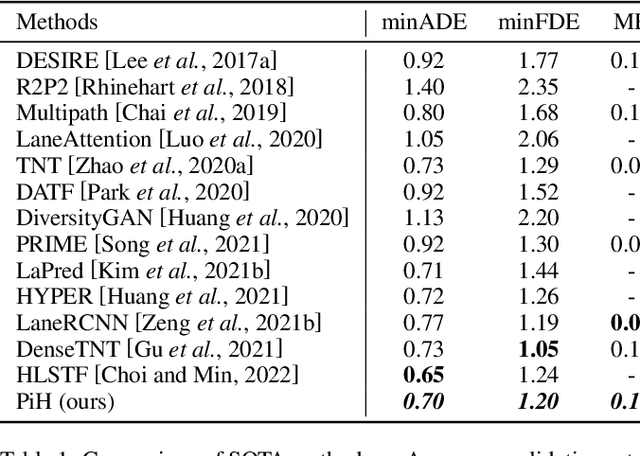
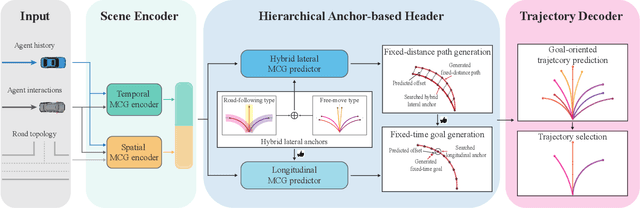
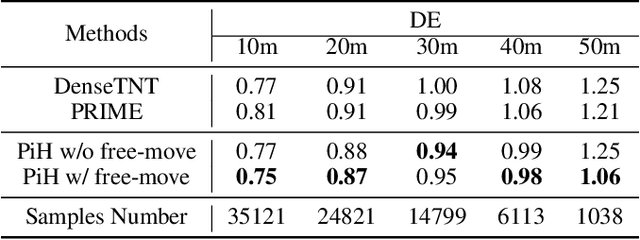
Recently, anchor-based trajectory prediction methods have shown promising performance, which directly selects a final set of anchors as future intents in the spatio-temporal coupled space. However, such methods typically neglect a deeper semantic interpretation of path intents and suffer from inferior performance under the imperfect High-Definition (HD) map. To address this challenge, we propose a novel Planning-inspired Hierarchical (PiH) trajectory prediction framework that selects path and speed intents through a hierarchical lateral and longitudinal decomposition. Especially, a hybrid lateral predictor is presented to select a set of fixed-distance lateral paths from map-based road-following and cluster-based free-move path candidates. {Then, the subsequent longitudinal predictor selects plausible goals sampled from a set of lateral paths as speed intents.} Finally, a trajectory decoder is given to generate future trajectories conditioned on a categorical distribution over lateral-longitudinal intents. Experiments demonstrate that PiH achieves competitive and more balanced results against state-of-the-art methods on the Argoverse motion forecasting benchmark and has the strongest robustness under the imperfect HD map.
Autonomous Platoon Control with Integrated Deep Reinforcement Learning and Dynamic Programming
Jun 15, 2022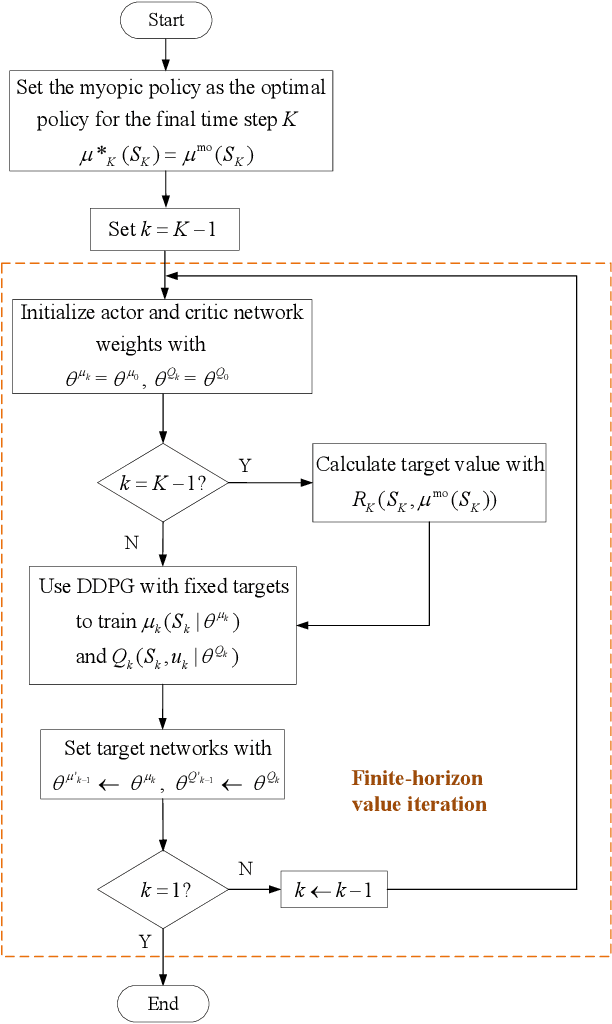
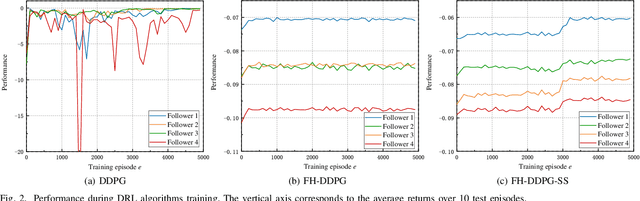
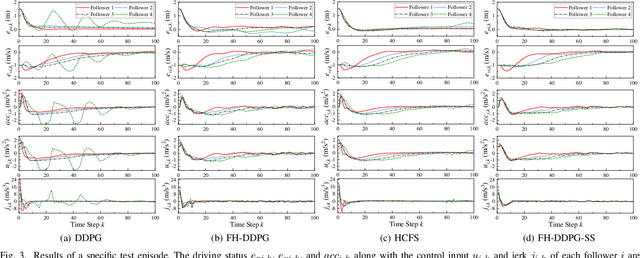
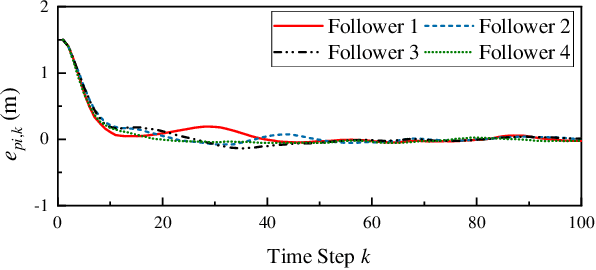
Deep Reinforcement Learning (DRL) is regarded as a potential method for car-following control and has been mostly studied to support a single following vehicle. However, it is more challenging to learn a stable and efficient car-following policy when there are multiple following vehicles in a platoon, especially with unpredictable leading vehicle behavior. In this context, we adopt an integrated DRL and Dynamic Programming (DP) approach to learn autonomous platoon control policies, which embeds the Deep Deterministic Policy Gradient (DDPG) algorithm into a finite-horizon value iteration framework. Although the DP framework can improve the stability and performance of DDPG, it has the limitations of lower sampling and training efficiency. In this paper, we propose an algorithm, namely Finite-Horizon-DDPG with Sweeping through reduced state space using Stationary approximation (FH-DDPG-SS), which uses three key ideas to overcome the above limitations, i.e., transferring network weights backward in time, stationary policy approximation for earlier time steps, and sweeping through reduced state space. In order to verify the effectiveness of FH-DDPG-SS, simulation using real driving data is performed, where the performance of FH-DDPG-SS is compared with those of the benchmark algorithms. Finally, platoon safety and string stability for FH-DDPG-SS are demonstrated.
SOUP-GAN: Super-Resolution MRI Using Generative Adversarial Networks
Jun 04, 2021
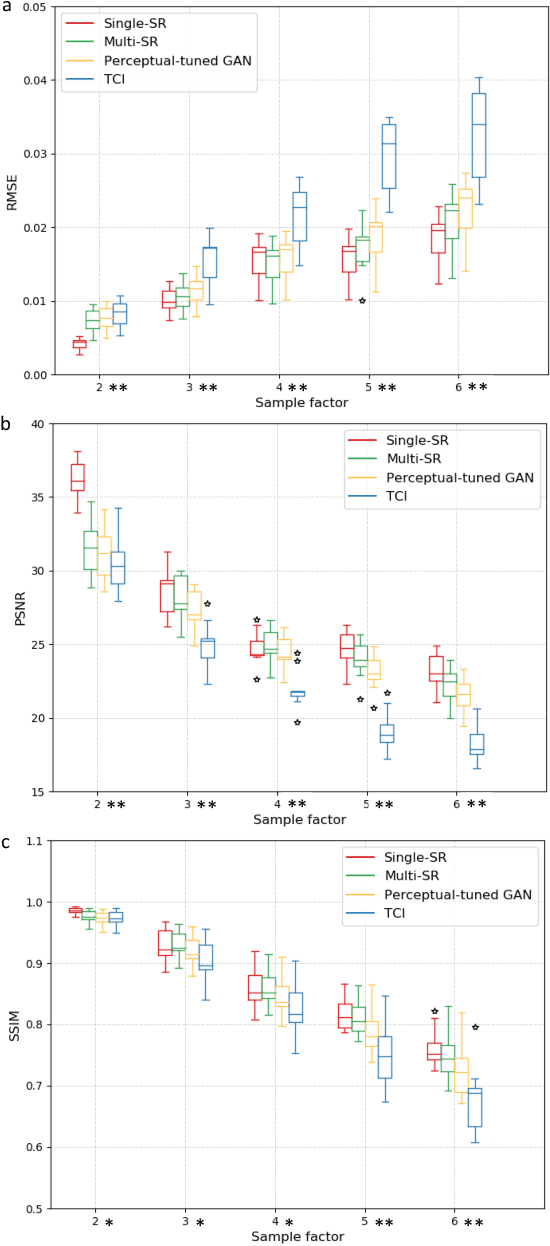
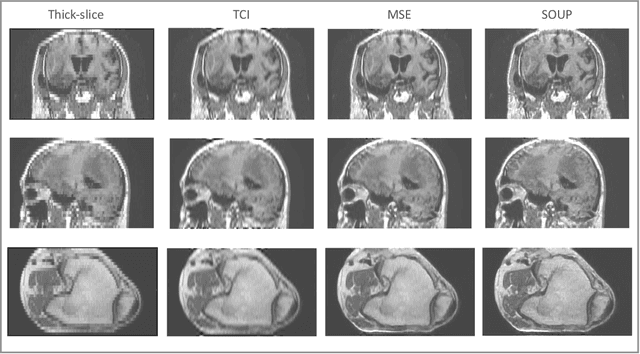

There is a growing demand for high-resolution (HR) medical images in both the clinical and research applications. Image quality is inevitably traded off with the acquisition time for better patient comfort, lower examination costs, dose, and fewer motion-induced artifacts. For many image-based tasks, increasing the apparent resolution in the perpendicular plane to produce multi-planar reformats or 3D images is commonly used. Single image super-resolution (SR) is a promising technique to provide HR images based on unsupervised learning to increase resolution of a 2D image, but there are few reports on 3D SR. Further, perceptual loss is proposed in the literature to better capture the textual details and edges than using pixel-wise loss functions, by comparing the semantic distances in the high-dimensional feature space of a pre-trained 2D network (e.g., VGG). However, it is not clear how one should generalize it to 3D medical images, and the attendant implications are still unclear. In this paper, we propose a framework called SOUP-GAN: Super-resolution Optimized Using Perceptual-tuned Generative Adversarial Network (GAN), in order to produce thinner slice (e.g., high resolution in the 'Z' plane) medical images with anti-aliasing and deblurring. The proposed method outperforms other conventional resolution-enhancement methods and previous SR work on medical images upon both qualitative and quantitative comparisons. Specifically, we examine the model in terms of its generalization for various SR ratios and imaging modalities. By addressing those limitations, our model shows promise as a novel 3D SR interpolation technique, providing potential applications in both clinical and research settings.
LSTM-based Anomaly Detection for Non-linear Dynamical System
Jun 05, 2020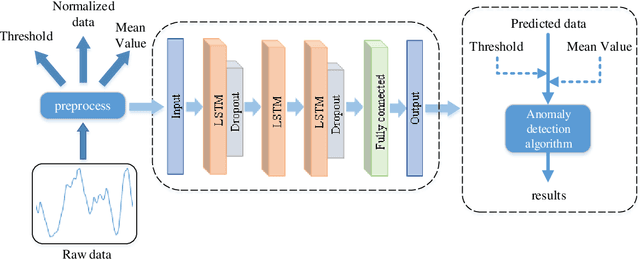
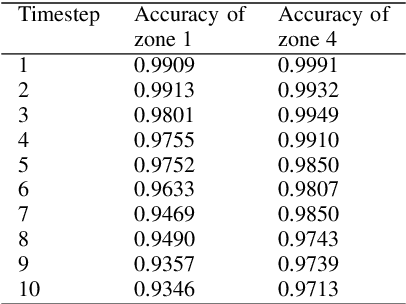
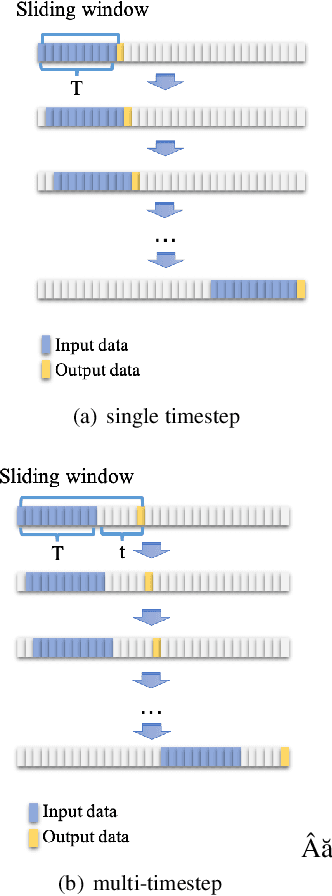
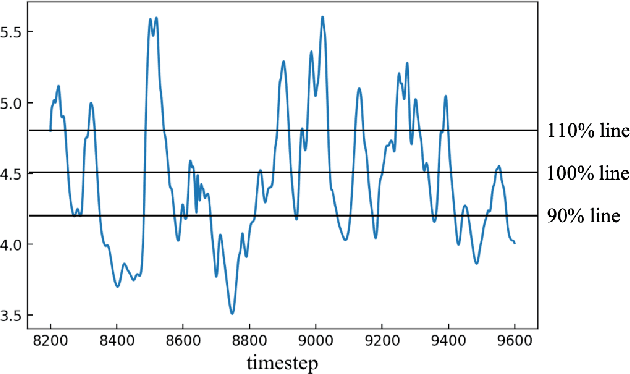
Anomaly detection for non-linear dynamical system plays an important role in ensuring the system stability. However, it is usually complex and has to be solved by large-scale simulation which requires extensive computing resources. In this paper, we propose a novel anomaly detection scheme in non-linear dynamical system based on Long Short-Term Memory (LSTM) to capture complex temporal changes of the time sequence and make multi-step predictions. Specifically, we first present the framework of LSTM-based anomaly detection in non-linear dynamical system, including data preprocessing, multi-step prediction and anomaly detection. According to the prediction requirement, two types of training modes are explored in multi-step prediction, where samples in a wall shear stress dataset are collected by an adaptive sliding window. On the basis of the multi-step prediction result, a Local Average with Adaptive Parameters (LAAP) algorithm is proposed to extract local numerical features of the time sequence and estimate the upcoming anomaly. The experimental results show that our proposed multi-step prediction method can achieve a higher prediction accuracy than traditional method in wall shear stress dataset, and the LAAP algorithm performs better than the absolute value-based method in anomaly detection task.